

A Dinâmica de Transformação de Dados

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! Após navegar profundamente nos processos de leitura e escrita de dados com o Spark, sejam estes armazenados localmente ou em sistemas distribuídos, o próximo passo da jornada de aprendizado envolve o elemento central de um processo típico de ETL: a transformação.
Apesar de ter em mãos APIs estruturadas com uma série de abstrações de alto nível que fornecem uma grande facilidade aos usuários, transformar dados com o Spark envolve alguns conceitos teóricos fundamentais que precisam ser mapeados antes de explorar exercícios práticos.
Embarque nesta jornada!
Transformações: a definição da receita
Afinal, o que é transformar um dado? Intuitivamente, para responder esta questão é possível imaginar um conjunto de dados passando por algum processo de mudança representado pela aplicação de uma lógica característica. Filtrar linhas, alterar tipos primitivos, aplicar operadores lógicos, ordenar e agrupar são apenas alguns termos que estão presentes neste "universo de mudança".
Na vasta gama existente de ferramentas, softwares e linguagens de programação, processos de transformação possuem particularidades próprias. Com o Spark, não é diferente: termos como imutabilidade, lazily evaluation, DAGs e planos de execução se mostram como alguns dos pilares que caracterizam o Spark como uma das mais poderosas ferramentas de processamento de dados na era do Big Data.
Ao longo desta seção, toda esta roupagem será explorada em detalhes para que um entendimento claro desta dinâmica de transformação possa ser obtido.
O conceito de imutabilidade
De início, é altamente relevante registrar um dos principais conceitos por trás de toda a lógica de transformações realizadas em Spark: a imutabilidade. Na prática, este conceito indica que as estruturas de dados existentes (ex: DataFrames) são, literalmente, imutáveis.
Bom, se "transformar" é, de certa forma, "mudar", como então é possível transformar dados no Spark se as estruturas responsáveis por armazená-los são imutáveis? Esta é uma ótima questão a ser respondida em detalhes.
Sob a ótica da linguagem de programação utilizada para interagir com o Spark, os DataFrames podem ser considerados objetos gerados a partir de classes e que possuem seus próprios métodos capazes de serem aplicados, para entre outras funções, a transformação de dados. Estabelecer que estes DataFrames são imutáveis significa dizer que sempre que o usuário codificar instruções que visam modificar o conteúdo de uma estrutura de dados já existente, uma nova estrutura é criada para armazenar o "estado" do conjunto posterior à instrução.
Em outras palavras, aplicar um ou mais métodos de transformação em um DataFrame significa gerar um novo DataFrame enquanto o original é mantido intacto. Como exemplo prático, o código abaixo simula a aplicação de um filtro de registros em um DataFrame original lido em memória (df1), gerando assim uma nova coleção distribuída (df2).
# Lendo base original de dados
df1_flights = spark.read.format("parquet").load(data_path)
# Filtrando vôos com origem nos EUA
df2_flights_eua = df1_flights.where("ORIGIN_COUNTRY_NAME = 'United States'")
E assim, filtros, ordenação, agrupamentos e outros vários tipos de transformações podem ser aplicadas, isoladamente ou em conjunto, gerando novas coleções distribuídas de dados posteriormente avaliadas pelo Spark de maneira lazily, próximo conceito a ser detalhado neste artigo.
Spark preguiçoso: o conceito de Lazily Evaluation
Sabendo que o conceito de imutabilidade no Spark implica na geração de novas coleções de dados a cada bloco aplicado de transformações, é preciso entender o que de fato ocorre no decorrer deste processo. A resposta é direta e, de certa forma, surpreendente: nada.
Com a permissão do uso da primeira pessoa, imagino o leitor, neste momento do artigo, realizando um grande esforço para confiar em alguém que diz que os objetos de dados no Spark são imutáveis e que os métodos de transformação não geram resultado algum. Além disso, chamando o Spark de preguiçoso. Assim fica difícil, não é? Mas peço um voto de confiança para unir os fios que ainda podem estar soltos.
O conceito de lazily evaluation indica que o Spark irá aguardar até o último instante antes de executar o grafo de instruções computacionais programado pelo usuário na forma de transformações. Isso significa que os usuários, ao aplicarem métodos de transformação em DataFrames, não estarão modificando-os instantaneamente, mas sim construindo um plano de transformações que, posteriormente, será avaliado, compilado e executado pelo Spark da maneira mais otimizada possível.
Para exemplificar este cenário, o bloco de código abaixo atua como um complemento ao processo de transformação já ilustrado previamente. Nele, são aplicadas duas modificações no conjunto original lido em memória, sendo a primeira responsável por filtrar vôos de origem americana e, a segunda, ordenando os resultados para verificar os principais destinos destes vôos.
# Lendo base original de dados
df1_flights = spark.read.format("parquet").load(data_path)
# Filtrando vôos com origem nos EUA
df2_flights_eua = df1_flights.where("ORIGIN_COUNTRY_NAME = 'United States'")
# Ordenando conjunto de acordo com a contagem de vôos
df3_flights_eua_ordered = df2_flights_eua.orderBy(desc("count"))
Neste momento, o fluxo de dados possui três DataFrames, cada um contendo um estado específico com suas respectivas instruções computacionais. Diante disso, é literalmente correto dizer que nada ocorreu em termos de retorno de resultados. Os dados ainda não existem sob a ótica do usuário e isso pode ser, de certa forma, analisado ao printar os objetos representativos aos DataFrames:
# Onde estão os dados?
print(f'DataFrame 1: {df1_flights}')
print(f'DataFrame 2: {df2_flights_eua}')
print(f'DataFrame 3: {df3_flights_eua_ordered}')
# Os DataFrames são iguais?
print(f'\nOs DataFrames são iguais? {(df1_flights == df2_flights_eua == df3_flights_eua_ordered)}')

Como mencionado previamente, este comportamento ocorre pois todas as transformações programadas são avaliadas de maneira lazily (ou preguiçosa mesmo), indicando que os resultados não são computados imediatamente, mas sim mantidos ou lembrados como uma linhagem. Isto permite que o Spark, ao tentar construir o melhor plano de execução possível para o conjunto de transformações aplicadas, rearranje algumas operações de modo a otimizar todo o processo. Por exemplo, um filtro aplicado no final de um processo de transformação pelo usuário poderia ser mais eficiente caso aplicado no início (ou em algum ponto anterior), permitindo que as transformações sejam computadas de forma mais rápida em um conjunto menor de dados. O Spark consegue alcançar estes pontos de otimização através da manutenção da linhagem neste conceito de "avaliação preguiçosa".
Mas então, como obter os dados e informar ao Spark para, de fato, iniciar as computações aplicadas? Aqui é apresentado o conceito de ações.
Ações: a execução do prato principal
Se as transformações são basicamente a definição da receita, as ações são responsáveis por executar todos os passos definidos. Em continuidade aos exemplos já fornecidos, como seria possível visualizar alguns registros de cada um dos DataFrames criados dentro da lógica de transformações que visa obter uma lista ordenada de vôos com origem nos Estados Unidos?
# Visualizando amostras de cada objeto DataFrame
print('DataFrame 1: Dados originais')
df1_flights.show(5)
print('DataFrame 2: Vôos com origem nos Estados Unidos')
df2_flights_eua.show(5)
print('DataFrame 3: Principais destinos de vôos americanos')
df3_flights_eua_ordered.show(5)
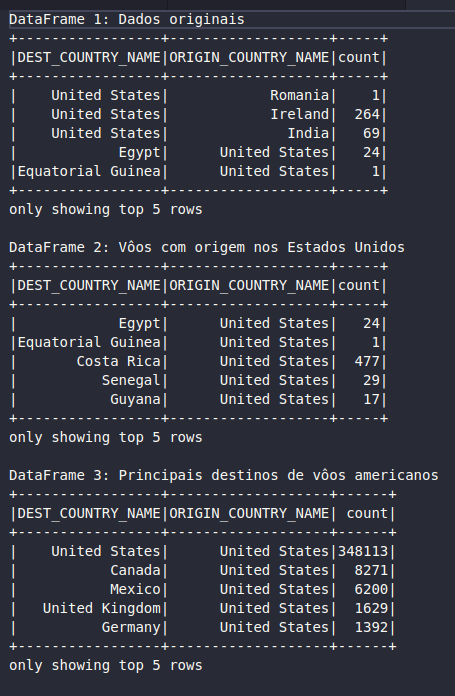
No bloco de código acima, a ação .show(n) é responsável por mostrar ao usuário os n registros de um DataFrame. Ao aplicar esta ação em cada um dos DataFrames gerados, é possível perceber como a linhagem é armazenada e como o Spark mantém o histórico de instruções, desde a leitura dos dados originais (df1_flights), até o conjunto final filtrado e ordenado (df3_flights_eua_ordered).
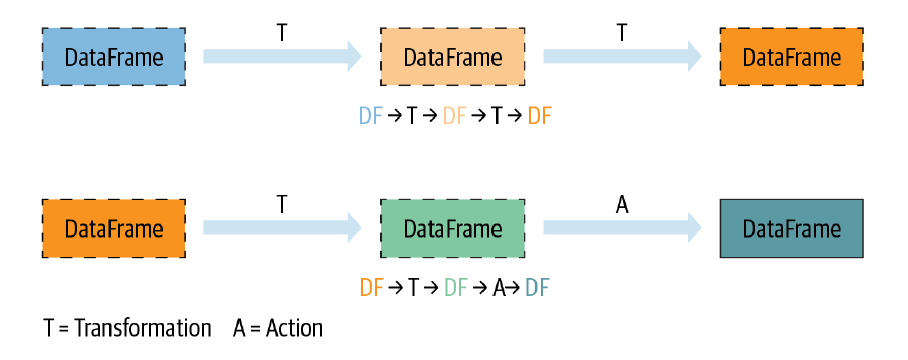
Na prática, a aplicação de uma ação em um conjunto de dados representa o acionamento de um gatilho para que o Spark possa iniciar toda a computação programada previamente dentro do grafo de instruções. Assim, ao executar o método show() no último DataFrame do processo, por trás das cortinas do Spark, foi possível identificar os processos de ordenação e filtragem de registros, permitindo então a construção de um plano ótimo para este cenário. A figura abaixo traz uma ilustração genérica sobre os processos de transformações e ações aplicadas em um pipeline de dados.
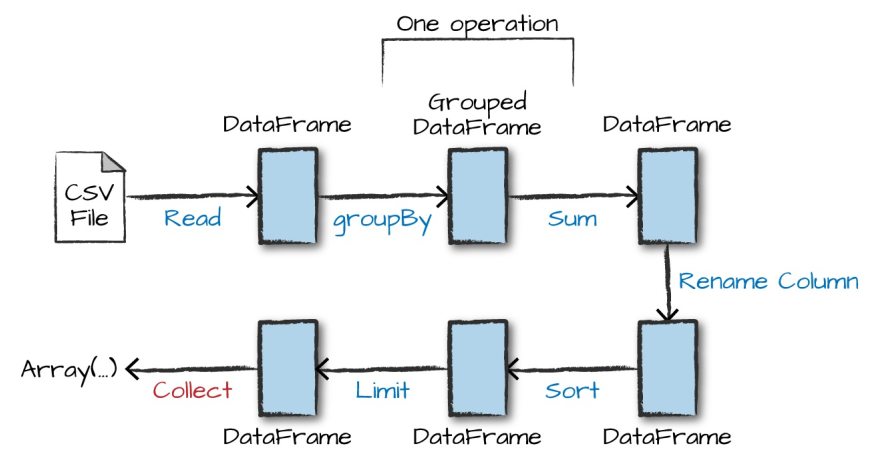
Existem ainda uma série de outras ações que podem ser chamadas como gatilhos de execução do grafo de instruções, como por exemplo, take(), count(), collect(), save(), etc. A documentação oficial do Apache Spark pode ser uma excelente amiga neste momento. Em um exemplo adicional representado pela figura abaixo, é possível perceber as etapas definidas em um processo típico de transformação de dados no Spark a partir de várias instruções distintas.
Até este ponto, foi possível compreender como transformações e ações atuam de modo a coordenar instruções de mudanças em coleções estruturadas, executando-as da melhor forma possível através de planos de execução. De maneira ilustrativa, as imagens disponibilizadas acima serviram como guia para entender a dinâmica de linhagem dentro do conceito de lazily evaluation. Na próxima seção, serão explorados alguns conceitos mais técnicos sobre o trabalho do Spark para definir o caminho mais otimizado em prol do retorno dos dados aos usuários.
Planos de Execução
No vasto mundo de utilização do Spark, as APIs estruturadas (DataFrames, Datasets e Spark SQL) atuam como um poderoso conjunto amplamente aderido pela comunidade de engenheiros, cientistas ou entusiastas do universo de dados.
Até este momento, foi possível compreender que, no ambiente das APIs estruturadas, um job Spark, seja este programado em Python, Scala ou Java, é composto de uma série de transformações e ações que, em conjunto são responsáveis por criar e executar o grafo computacional de instruções avaliado pelo Spark de forma lazily.
Imersos agora no mundo de execução de todo o trabalho programado, é possível resumir as operações realizadas pelo Spark considerando os seguintes pontos:
- O usuário escreve seu código utilizando DataFrames/Datasets/Spark SQL
- Se o código for válido, o Spark o converte para um Plano Lógico
- O Spark transforma o Plano Lógico em um Plano Físico, sempre procurando por otimizações ao longo do caminho
- O Spark então executa o Plano Físico no cluster
Plano Lógico
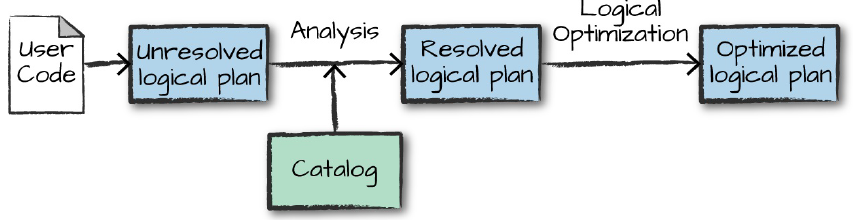
A primeira etapa do processo de execução de um job Spark compreende na construção de um plano lógico representando apenas um conjunto abstrato de transformações. Neste momento, apenas uma conversão do código escrito pelo usuário é realizada para uma versão mais otimizada sob a alcunha de um "plano lógico não resolvido" que, após algumas operações internas de consulta no catálogo, se transforma em um "plano lógico resolvido" capaz de ser otimizado.
Plano Físico
Após a criação de um plano lógico otimizado, o Spark então inicia a construção do plano físico para execução do job. Basicamente, é neste momento que uma interação estritamente próxima com o cluster de computadores é formalizada, visto que o código desenvolvido será executado em um ambiente distribuído. Para definir a melhor a abordagem possível, o Spark avalia uma série de planos físicos de execução através de uma função de custo, permitindo assim selecionar o caminho mais otimizado.
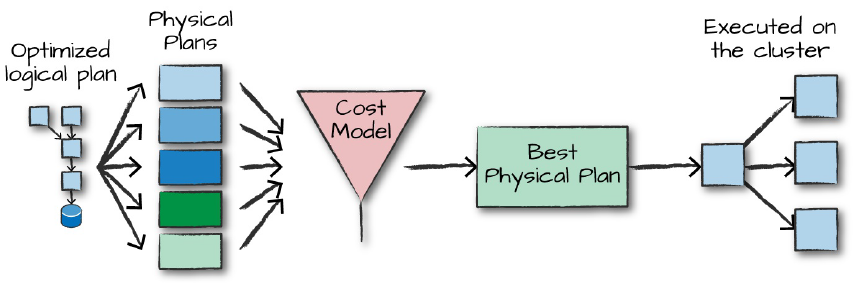
Visualizando Planos
Por mais abstrato que o conceito de planos de execução possa parecer, o Spark proporciona algumas entradas ao usuário que permitem avaliar exatamente as etapas a serem realizadas dentro do contexto de execução do job. Em alguns casos, principalmente em jobs que envolvem muitas etapas de transformação, este plano pode parecer pouco interpretável à primeira vista. Mesmo assim, com uma certa prática, é possível observar alguns pontos específicos e até encontrar, por conta própria, situações de melhoria.
Dessa forma, para verificar o plano de execução de uma coleção estruturada de dados no Spark basta executar o método explain(). No bloco de código abaixo, será possível verificar as etapas propostas pelo Spark para gerar o conjunto definido pelo DataFrame df3_flights_eua_ordered contendo dados ordenados por contagem de vôos com origem nos Estados Unidos:
# Verificando plano de execução
df3_flights_eua_ordered.explain()
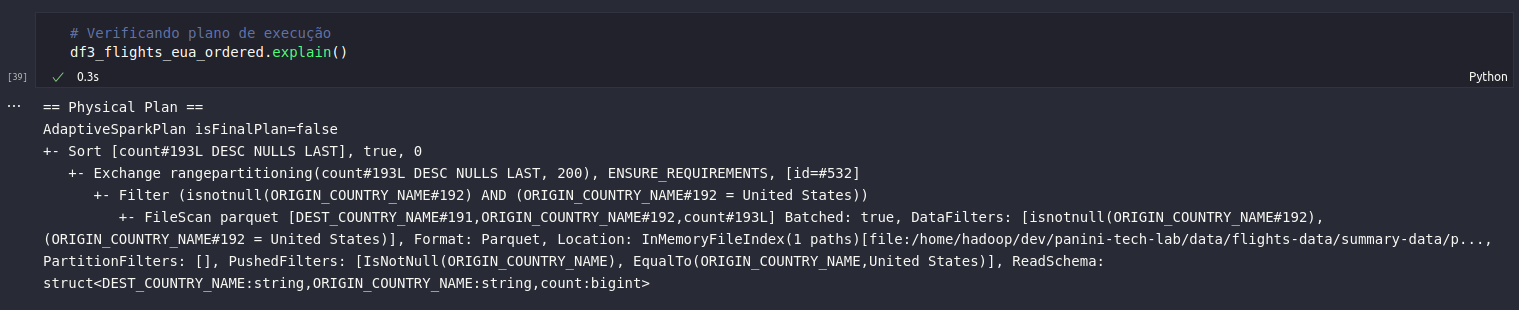
Ao analisar o resultado obtido, é possível identificar alguns termos que realmente fazem sentido dentro da lógica de transformações codificada. Alguns outros pontos presentes no plano indicam dinâmicas existentes no conceito de processamento distribuído, como o reparticionamento e o scan dos dados.
Conclusão e encerramento
E assim, após uma importante fundamentação teórica nos processos de transformações, ações, planos de execução e a forma "preguiçosa" (porém ótima) do Spark em avaliar e executar o grafo de instruções codificadas, mais um artigo desta série chega ao fim.
A importância do conteúdo aqui alocado está diretamente relacionada com a construção de jobs e pipelines de transformação de dados em processos de ETL ou mesmo de data preparation. Compreender as características do Spark dentro desta dinâmica auxilia no entendimento geral sobre como o poder de processamento desta ferramenta é construído.
Foi ótimo ter você aqui, caro leitor! Te aguardo nos próximos artigos.




