




Bem-vindos a mais um artigo da série "Visão Geral sobre o Ecossistema Hadoop"! Recheada de conteúdos relevantes, a última sequência de artigos trouxe uma visão altamente rica sobre os três principais componentes do Hadoop Core e a tabela abaixo serve como uma referência prática de leitura:
| Componente | Resumo | Artigo |
| HDFS | Sistema de armazenamento distribuído do Hadoop | Link |
| MapReduce | Modelo de programação para processamento paralelo | Link |
| YARN | Gerenciador de recursos do cluster Hadoop | Link |
Com isso, foi possível obter insumos suficientes para um entendimento geral das principais funcionalidades do Hadoop em sua concepção. Termos como namenode, datanode, resource manager e node manager, para citar alguns, são agora parte do vocabulário do leitor que consumiu as leituras citadas!
Assim, em um passo ainda mais ousado, este artigo tem como principal objetivo transcrever uma jornada simplificada de integração dos três componentes do Hadoop Core de modo a complementar o conhecimento adquirido. Conhecer individualmente o HDFS, o MapReduce e o YARN abriu portas para que seja possível compreender, por exemplo, as etapas operacionais executadas em um cluster Hadoop sempre que um job é submetido ao sistema para processamento de grandes volumes de dados.
Fluxo dos Dados
Em uma das seções do livro Hadoop: the Definitive Guide, o autor (Tom White) aborda conceitos sobre a escalabilidade do Hadoop como uma forma de proporcionar um entendimento claro dos processos relacionados ao HDFS e ao MapReduce.
Em um primeiro momento, é importante definir um job de MapReduce como uma unidade de trabalho submetida pelo client e composta pelos seguintes elementos:
- Dados de entrada
- Um programa de MapReduce
- Informações de configuração
Com estes três componentes em mãos, o Hadoop executa o job dividindo-o em tarefas de mapeamento e redução. Tais tarefas são agendadas pelo YARN e executadas nos nós do cluster. Se uma tarefa falha, ela é automaticamente reagendada para executar em um recurso distinto.
Definidos os detalhes do programa de MapReduce e dos recursos responsáveis por sua execução, o Hadoop então separa os dados de entrada em partes distintas (ou splits), fomentando assim a execução de uma função de mapeamento definida pelo usuário para cada uma dessas partes.
Neste ponto, é extremamente importante associar que, quanto maior o número de splits dos dados de entrada, maior o número de tarefas de mapeamento alocadas, sendo este um fator que pode contribuir positivamente com o processamento paralelo em cenários de Big Data. Por outro lado, se a quantidade de splits for elevada e em pequenos volumes, o gerenciamento destes "mini" pedaços de dados pode causar um alto tempo de processamento das tarefas submetidas em um dos grandes desafios operacionais do Hadoop conhecido como small files.
E é aqui que o conceito de blocos do HDFS entra em ação! Em geral, para grande parte dos jobs de MapReduce, um bom tamanho de split tende a ser exatamente igual ao tamanho do bloco definido para o cluster (128MB ou 256MB), proporcionando assim um aproveitamento completo dos recursos e otimizando as tarefas de mapeamento.
Assim, considerando o cenário proposto com diferentes partes dos dados presentes em diferentes recursos computacionais do cluster e submetidos a funções específicas definidas pelo usuário, alguns questionamentos se fazem presentes: como o Hadoop atua para garantir a execução das tarefas em diferentes máquinas de computadores? O que ocorre quando existem necessidades e persistência dos dados em diferentes máquinas do cluster? Em que momento os dados são "unidos" para a aplicação de tarefas de redução? Onde ocorre essa união?
Atuação do Hadoop em Tarefas de Mapeamento
É sempre importante reforçar que o contexto de atuação do Hadoop está relacionado a dados armazenados em sistemas distribuídos e processados de maneira paralela em um cluster de computadores. Na prática, quando o sistema realiza a divisão dos dados (split) para associação às tarefas de mapeamento, diferentes nós em diferentes racks do cluster podem ser designados para execução da função de map definida pelo usuário.
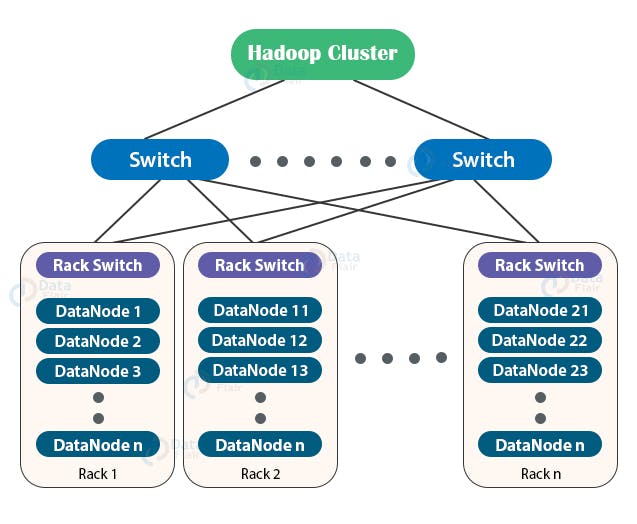
Pensando em otimização, é possível imaginar que o melhor cenário possível dentro desta dinâmica é a atribuição das tarefas de mapeamento no mesmo recurso computacional onde os dados residem no HDFS. Em outras palavras, isto significa dizer que o mesmo nó onde o bloco de dados está armazenado será utilizado para aplicar a tarefa de mapeamento associada à esta mesma entrada, aproveitando-se assim da proximidade dos dados e evitando necessidades de transferência de dados entre diferentes nós ou racks do cluster (o que ocasionaria uma alta latência).
Por padrão, o Hadoop faz o melhor possível para associar tarefas de mapeamento a nós onde os splits estão armazenados e isto inclui todas as replicas existentes no cluster. Por exemplo, supondo um bloco A de dados presente nos datanodes A, B e C (fator de replicação igual a três), então a tarefa de mapeamento associada tentará ser executada em um destes datanodes. A este processo dá-se o nome de data locality optimization.
Entretanto, é provável que todos os nós onde o "bloco A" está armazenado (A, B e C, no exemplo) estejam executando outras tarefas de mapeamento, impossibilitando assim a associação de uma nova atividade. Em casos assim, o job scheduler do Hadoop tenta então encontrar um slot livre em um nó do mesmo rack. Este é o segundo melhor cenário possível, visto que os dados de entrada para a função de mapeamento precisarão ser migrados para o nó de execução da função em uma transferência dentro do mesmo rack.
Em situações extremamente raras, é provável que tanto os nós de armazenamento do bloco quanto todos os nós do mesmo rack estejam ocupados processando outras tarefas. Em casos como este, o Hadoop invariavelmente irá alocar um recurso computacional de um rack distinto à localidade física dos dados no HDFS, exigindo assim uma transferência de dados em largura de banda para que o nó responsável pela execução da função de mapeamento obtenha o bloco de dados. Este é o pior cenário possível dentro da dinâmica operacional de execução no Hadoop, uma vez que os dados de entrada para a função precisarão passar por um processo de migração de alta latência entre racks.
A figura abaixo ilustra os três cenários acima exemplificados e relaciona as diferentes possibilidades de associação de tarefas de mapeamento dentro do cluster de computadores.
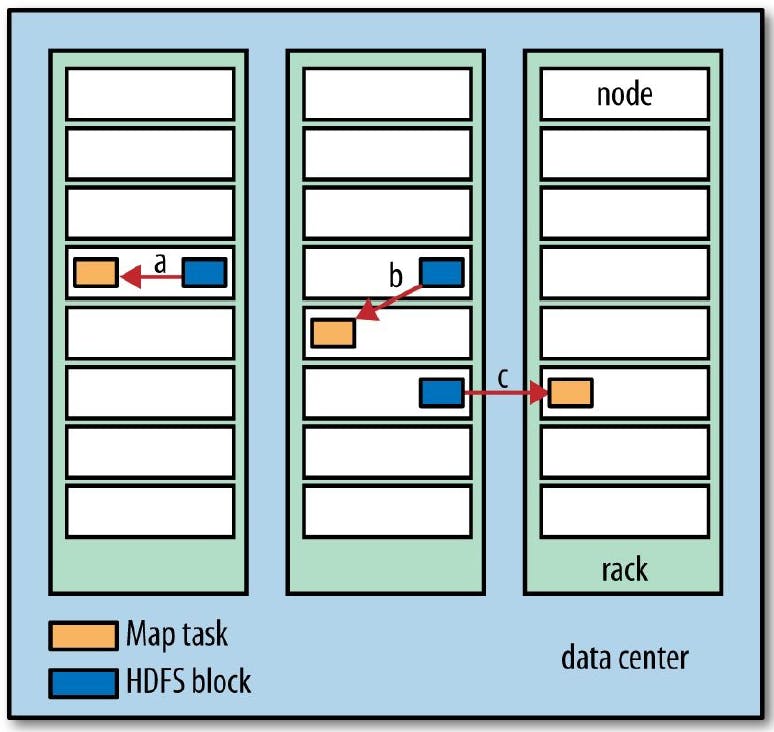
Em linhas gerais:
- a) A tarefa de mapeamento é designada ao mesmo nós onde o bloco de dados reside no HDFS (data-local);
- b) A tarefa de mapeamento é designada a um nó diferente do nó de armazenamento do bloco, porém no mesmo rack de recursos computacionais (rack-local);
- c) A tarefa de mapeamento é designada a um nó presente em um rack diferente ao nó de armazenamento de bloco (off-rack).
Nesta conjuntura, deve estar clara agora a importância do split ótimo dos dados como uma relação direta com o tamanho do bloco do HDFS. Este é basicamente o volume máximo dos dados que podem ser armazenados em um nó único. Se o split realizado supera o tamanho do bloco e, dessa forma, expande múltiplos nós, fatalmente as tarefas de mapeamento designadas exigiriam uma transferência destes dados através da rede (rack-local ou off-rack), aumentando a latência e eliminando qualquer vantagem associada à localidade dos dados.
Por fim, é válido citar que as tarefas de mapeamento escrevem suas respectivas saídas em disco e não no HDFS. Para justificar esta atuação, é importante pontuar que jobs que envolvem ambas as fases de mapeamento e redução, intuitivamente fazem com que as saídas das tarefas de map sejam apenas resultados intermediários da aplicação completa. Armazenar este resultado intermediário no HDFS e replicá-lo em múltiplos nós seria inviável. Uma vez completo o job submetido, os resultados intermediários das saídas das funções de mapeamento podem ser descartados.
Atuação do Hadoop em Tarefas de Redução
Tarefas de redução não possuem a vantagem da localidade dos dados. Em outras palavras, o recurso computacional responsável pela execução da função designada não é o mesmo que armazena os blocos necessários para o processamento. Como a entrada para uma tarefa de redução é uma combinação entre todas as saídas das funções de mapeamento (sendo estas armazenadas localmente nos nós), é intuitivo imaginar que o nó responsável pela execução da função de mapeamento deverá lidar com dados presentes em diferentes nós do cluster.
Naturalmente, os dados intermediários das fases de mapeamento precisam ser transferidos através da rede para o nó onde a função de redução será executada. Em geral, os resultados de uma tarefa de execução são persistidos no HDFS, assim como suas réplicas. A primeira réplica normalmente é armazenada no mesmo nó de execução da tarefa de redução e, para contribuir com uma maior disponibilidade do sistema, as demais réplicas são armazenadas em nós presentes em racks diferentes.
Diferentes Cenários do MapReduce
Entre os detalhes fornecidos para as tarefas de mapeamento e redução, é importante citar que os jobs de MapReduce podem apresentar diferentes características guiadas de acordo com as necessidades de transformação de dados solicitadas pelo client. Em linhas gerais, se uma aplicação não precisa de etapas relacionadas a agregação de dados, por exemplo, consequentemente não há a necessidade de realizar tarefas de redução, tornando o job de MapReduce algo resolvido apenas com tarefas de mapeamento. Em outros casos, a complexidade da solicitação pode exigir que o problema seja endereçado através da execução de múltiplas tarefas de redução.
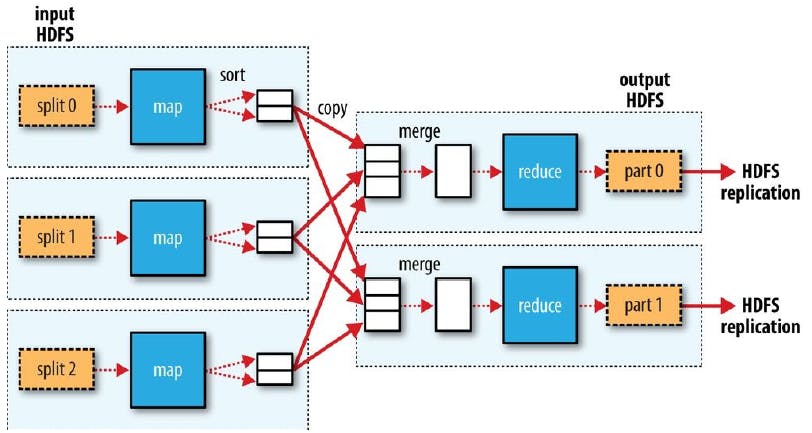
As imagens consolidadas abaixo irão ilustrar fluxos capazes de traduzir os tópicos teóricos detalhados nas seções anteriores considerando três cenários distintos de MapReduce factíveis de serem encontrados na dinâmica do Hadoop:
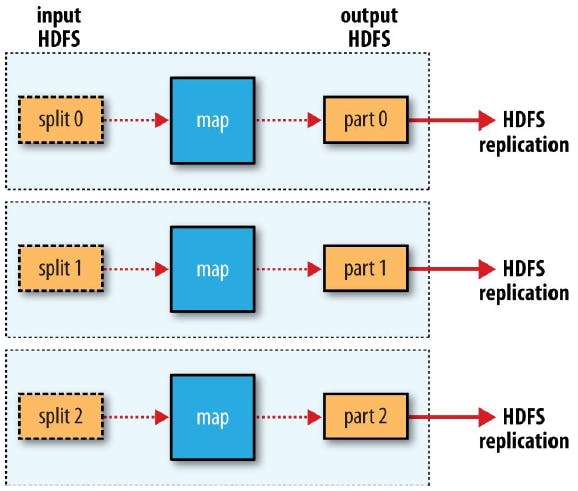
1. Fluxo de MapReduce formado apenas por tarefas de Map
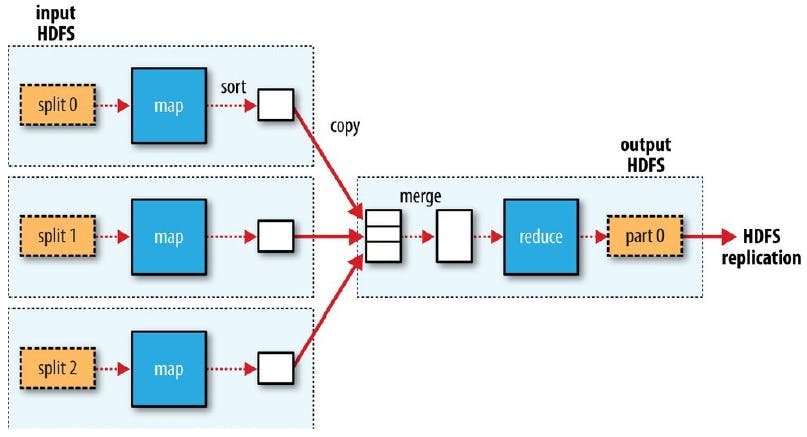
2. Fluxo de MapReduce com múltiplas tarefas de Map e uma única tarefa de Reduce
3. Fluxo de MapReduce com múltiplas tarefas de Map e múltiplas tarefas de Reduce
Considerações Finais
Considerando os recentes artigos desta série, é possível concluir que muito conhecimento interessante foi adquirido e compartilhado. Conhecer o Hadoop e sua atuação em cenários práticos de processamento e armazenamento de dados garante uma maior autonomia na construção de pipelines otimizados.
Com este propósito em mente, a sugestão final deste autor é que o leitor navegue por este e pelo menos pelos últimos três artigos desta série múltiplas vezes. De forma adicional, o consumo das referências utilizadas para a construção dos mesmos é uma dica fundamental para a obtenção de insights técnicos que superam os tópicos consolidados nos artigos recomendados.
Por fim, com a finalização deste artigo, podemos partir para uma sequência mais prática de utilização do Hadoop através de sua instalação em uma máquina virtual Linux. Assim, nos próximos conteúdos aqui alocados, colocaremos a mão na massa para exercitar grande parte dos tópicos teóricos consolidados em um cenário onde será possível visualizar o poder do Hadoop e suas vastas funcionalidades.
Muito obrigado por chegarem até aqui e espero vocês lá!