

Adicionando, Renomeando e Removendo Colunas

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! No último artigo, foi possível discutir tópicos fundamentais envolvendo a construção de consultas através dos métodos select() e selectExpr() que, em essência, são responsáveis por proporcionar opções interessantes para análises específicas em conjuntos estruturados de dados. Para que este objetivo pudesse ser alcançado, foi preciso abordar detalhadamente as referências de colunas como expressões a partir das funções col() e expr(), cada uma com suas próprias particularidades.
Em continuidade ao nosso processo de aprendizado, este artigo tem como objetivo apresentar mais três métodos de transformação de dados aplicados à DataFrames:
| Método | Aplicação |
withColumn() | Criação de novas colunas em um DataFrame |
withColumnRenamed() | Alteração de nomes de colunas já existentes |
drop() | Eliminação de colunas de um DataFrame |
Considerando os avanços obtidos até aqui, é importante citar que, cada vez mais, os conhecimentos envolvendo conteúdos teóricos sobre os blocos fundamentais do Spark são elementos já presentes em nossa bagagem técnica. Dessa forma, os artigos a serem consolidados nesta série, aos poucos, irão naturalmente adotar uma conduta estritamente próxima ao completo hands on, permitindo ao leitor visualizar, de maneira direta, as aplicações e os resultados das transformações codificadas.
Embarque nesta jornada!
Dados para exploração
Assim como em outros artigos desta série, a base de dados utilizada para demonstração dos métodos de transformação aqui consolidados terá raízes nos registros de vôos extraídos do Bureau dos Estados Unidos. Abstraindo todo o processo de importação de bibliotecas, construção de sessão e leitura dos dados, o objeto alvo de estudo está representado na variável df exemplificada logo a seguir:
# [...]
# Criando tabela temporária
df.createOrReplaceTempView("tbl_flights")
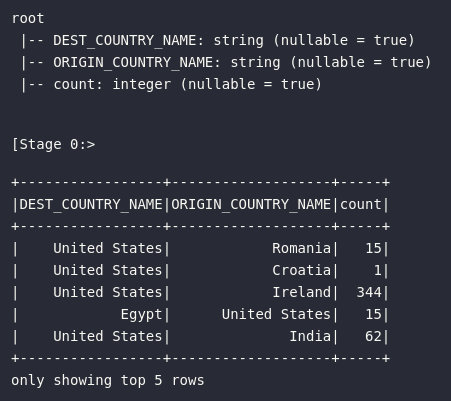
# Verificando amostra dos dados
df.printSchema()
df.show(5)
Operações em colunas
Em uma abertura oficial da seção que irá comportar as explorações práticas, é importante reforçar que a aplicação dos métodos nas coleções distribuídas de dados representam apenas a definição de um plano de execução que poderá ser avaliado posteriormente pelo Spark. Em outras palavras, executar qualquer um dos métodos demonstrados em um DataFrame não configura qualquer retorno visual ao usuário, a não ser que o mesmo codifique uma consulta (select(), selectExpr()) ou execute uma ação específica para isso (show()).
E assim, de maneira gradual, os códigos demonstrados contemplarão os conhecimentos adquiridos em outras experiências desta série, como uma jornada acumulada de aprendizado. Especificamente neste artigo, os métodos apresentados representam operações de transformações realizadas em colunas de um DataFrame, seja adicionando, renomeando ou removendo tais atributos.
Adicionando colunas: withColumn()
O primeiro novo método a ser explorado neste artigo é o withColumn() cuja aplicação permite adicionar colunas em um DataFrame lido em Spark. Sua sintaxe pode ser resumida pelo bloco abaixo:
.withColumn("nome_da_nova_coluna", "expressão")
Na prática, a nova coluna a ser adicionada na coleção distribuída recebe uma nomenclatura e uma expressão específica, permitindo assim a utilização direta da função expr() como definidora das operações a serem alocadas. No exemplo de código abaixo, o DataFrame original é utilizado para criar uma etapa de transformação envolvendo a adição de um novo atributo responsável por alocar o dobro da contagem de vôos registradas em cada linha.
# Importando funções adicionais
from pyspark.sql.functions import col, expr
# Adicionando coluna
df_double_count = df.withColumn("double_count", expr("count * 2"))
# Visualizando resultado
df_double_count.show(5)
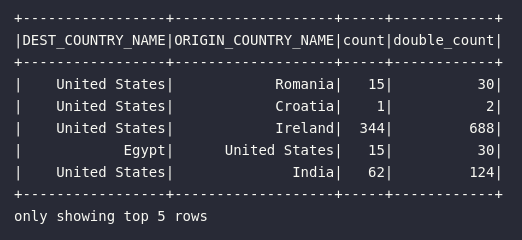
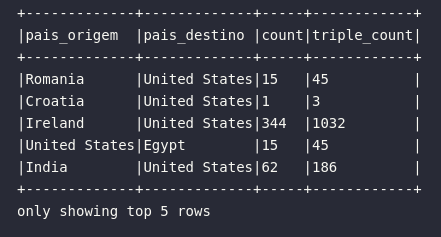
Neste caso, um novo DataFrame foi criado imaginando um cenário onde novas operações poderiam ser codificadas dentro da dinâmica de execução das DAGs de processamento. Entretanto, para os fins didáticos desta série, o mesmo código acima poderia ser reescrito considerando a aplicação de uma consulta nos dados logo após a transformação. Isto é interessante pois, sob o ponto de visto do desenvolvedor, trata-se de uma forma de encadear transformações em um bloco único. Neste cenário, o código abaixo une os elementos citados ao mesmo tempo que traz à tona múltiplos conceitos já abordados nesta série (como a mescla entre col() e expr()):
# Transformando e consultando
df.withColumn("triple_count", col("count") * 3)\
.select(
col("ORIGIN_COUNTRY_NAME").alias("pais_origem"),
expr("DEST_COUNTRY_NAME AS pais_destino"),
"count",
"triple_count"
).show(5, truncate=False)
Renomeando colunas: withColumnRenamed()
Progredindo na jornada, o método withColumnRenamed() pode ser diretamente utilizado para renomear colunas em um objeto do tipo DataFrame no Spark. Entretanto, aos acompanhantes assíduos desta série, eventualmente pode surgir uma dúvida relacionada às possibilidades abordadas anteriormente sobre o uso de expressões expr() ou do método alias() aplicado à colunas para realizar este mesmo processo.
Neste momento, é importante citar que ambas as formas já abordadas para modificar o nome de uma colunas estiveram sempre atreladas à consultas realizadas via select() ou selectExpr(). O método withColumnRenamed(), por sua vez, é utilizado para aplicar este mesmo efeito, porém em um cenário fixo de transformação de um DataFrame dentro do grafo de instruções. Sua sintaxe pode ser dada por:
withColumnRenamed("nome_atual_coluna", "nome_novo_coluna")
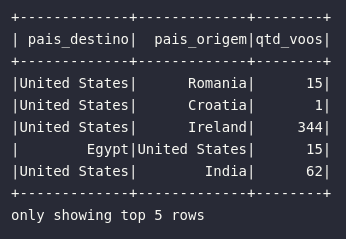
Para representar sua utilização prática, o bloco de código abaixo aplica o método de renomação de colunas para geração de um novo DataFrame:
# Renomeando colunas
df_renamed = df.withColumnRenamed("DEST_COUNTRY_NAME", "pais_destino")\
.withColumnRenamed("ORIGIN_COUNTRY_NAME", "pais_origem")\
.withColumnRenamed("count", "qtd_voos")
# Visualizando novo DataFrame
df_renamed.show(5)
Adicionalmente, para reforçar um cenário de utilização de consultas para alteração da nomenclatura de colunas, o mesmo resultado acima poderia ser obtido através da aplicação de um dos métodos de consultas disponíveis junto a expressões criadas com essa finalidade:
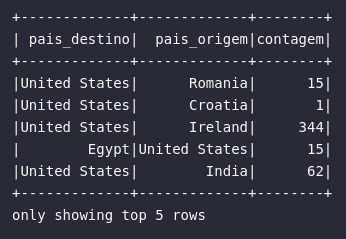
# Renomando colunas através de consultas
df_renamed_select = df.select(
col("DEST_COUNTRY_NAME").alias("pais_destino"),
expr("ORIGIN_COUNTRY_NAME AS pais_origem"),
expr("count AS contagem")
)
# Visualizando resultado
df_renamed_select.show(5)
Por fim, uma terceira alternativa poderia ser formalizada através do uso puro do SparkSQL:
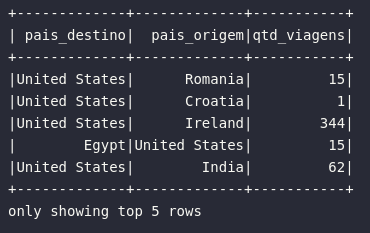
# Renomeando colunas com SparkSQL
df_renamed_sql = spark.sql("""
SELECT
DEST_COUNTRY_NAME AS pais_destino,
ORIGIN_COUNTRY_NAME AS pais_origem,
count AS qtd_viagens
FROM tbl_flights
""")
# Visualizando resultado
df_renamed_sql.show(5)
Ah, o Spark...
A proposta de apresentar soluções análogas para um mesmo processo permite ao leitor escolher aquela que mais se encaixa em suas preferências ou necessidades de trabalho.
Eliminando colunas: drop()
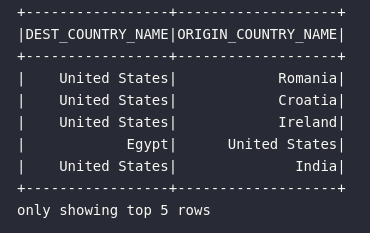
Por fim, encerrando este primeiro bloco de operações aplicadas à DataFrames para realizar transformações em colunas, o método drop() surge como uma forma direta de eliminar colunas de uma coleção distribuída de dados. Para utilizá-lo, basta fornecer a referência do atributo a ser eliminado:
# Eliminando colunas
df_dropped = df.drop("count")
# Visualizando
df_dropped.show(5)
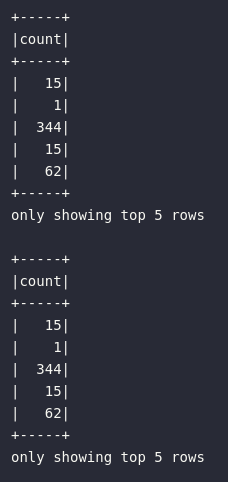
Adicionalmente, é possível eliminar múltiplas colunas em uma mesma chamada do método drop(), bastando apenas fornecer as referências em um formato capaz de ser processado pela linguagem utilizada.
# Eliminando múltiplas colunas
df.drop("ORIGIN_COUNTRY_NAME", "DEST_COUNTRY_NAME").show(5)
# Forma alternativa
to_drop = ["ORIGIN_COUNTRY_NAME", "DEST_COUNTRY_NAME"]
df.drop(*to_drop).show(5)
Conclusão e encerramento
E assim mais um artigo da série é encerrado com uma abordagem prática fundamental para contribuir cada vez mais com o aprendizado em processos de transformações de dados com o Spark. Os métodos para adicionar, renomear ou eliminar colunas contemplam uma parcela fundamental das operações mais comuns aplicadas em fluxos reais de trabalho. Compreender como utilizá-los, quais são as alternativas e as especifidades envolvidas pode ser considerado um marco importante na jornada.
Neste momento, é importante ressaltar e, mais uma vez reforçar, que os artigos desta série se aproximam cada vez mais de um cenário majoritariamente formado por exemplos práticos e diretos, tornando seu conteúdo mais reduzido e objetivo se comparados com artigos anteriores onde se fazia necessária uma fundamentação teórica específica. Que esta mudança na abordagem traga bons frutos de aprendizado!
Foi ótimo ter você aqui, caro leitor. Até a próxima!




