

Agregações e Agrupamentos de Dados

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! No momento atual da jornada de aprendizado, uma série de funções e métodos já foram apresentados aos leitores como elementos capazes de serem aplicados nos mais variados fluxos de transformação. Para adicionar ainda mais capacidade técnica e autonomia aos entusiastas do Spark, este artigo possui, como principal objetivo, demonstrar alguns métodos comumente aplicados para computar diferentes cálculos estatísticos e agregações.
Adicionalmente, o tipo RelationalGroupedDataset será apresentado como um elemento resultante de processos de agrupamento no qual as funções de agregações podem ser aplicadas, aumentando ainda mais o leque de possibilidades analíticas com o Spark.
Quer compreender como realizar agregações, agrupamentos, aplicar funções estatísticas e extrair análises específicas de conjuntos de dados no Spark? Embarque nessa jornada!
Dados para exploração
Visando proporcionar uma nova experiência aos leitores, a proposta para este artigo gira em torno da utilização de uma base de dados inédita. Considerando obter um maior número de possibilidades, os exemplos práticos a serem consolidados serão aplicados em uma base de dados retirada a partir da leitura de sensores IoT posicionados em fábricas ao redor do mundo.
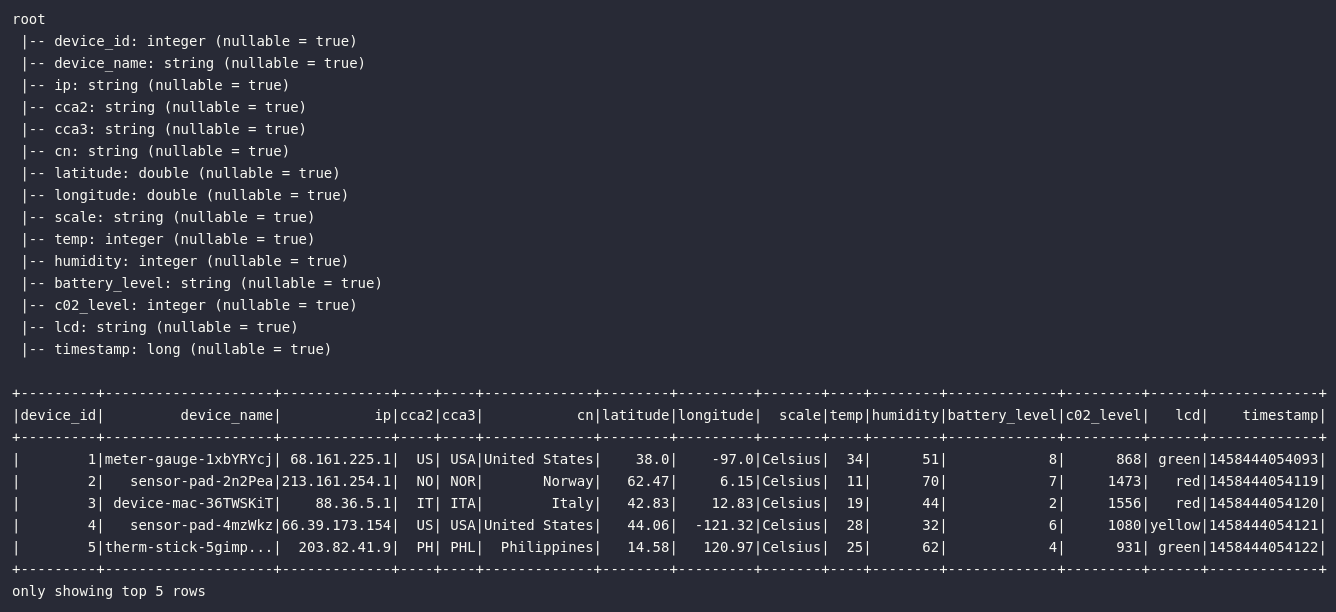
Presente originalmente no repositório oficial do livro Learning Spark, os dados de sensores IoT são disponibilizados no formato JSON e possuem a seguinte característica:
# Lendo dados
df_iot = spark.read.format("json")\
.schema(iot_schema).load(iot_path)
# Criando tabelas temporárias
df_iot.createOrReplaceTempView("tbl_iot")
# Visualizando dados
df_iot.printSchema()
df_iot.show(5)
Funções de Agregação
Para iniciar os detalhes práticos prometidos na seção de introdução, é importante pontuar que as operações a serem demonstradas refletem basicamente funções importadas do módulo pyspark.sql.functions e que serão aplicadas dentro de consultas a DataFrames a partir dos métodos select() ou selectExpr(). A partir deste ponto, uma avalanche de novos elementos estatísticos farão parte do leque de conhecimentos adquiridos!
count
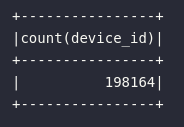
De modo simplório, o primeiro exemplo prático fornecido envolve a contagem de elementos de um DataFrame através da função count. O bloco de código abaixo pode ser utilizado para contabilizar as leituras realizadas pelos sensores:
# Importando função
from pyspark.sql.functions import count
# Contando leituras realizadas
df_iot.select(
count("device_id")
).show()
countDistinct
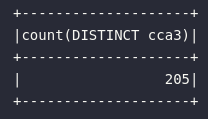
Em alguns cenários, pode ser necessário realizar uma contagem de elementos distintos presentes em um determinado atributo de uma base de dados. Dessa forma, a função countDistinct se faz presente e pode ser aplicada, no contexto da fonte de dados utilizada, para contabilizar a quantidade distinta de países onde os sensores de medição foram posicionados. A coluna que representa o país origem da medição é dada pela referência cca3:
# Importando função
from pyspark.sql.functions import countDistinct
# Contabilizando países distintos
df_iot.select(
countDistinct("cca3")
).show()
first e last
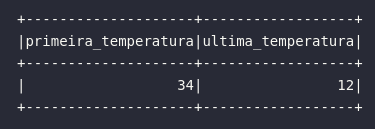
Eventualmente, é possível obter a primeira e última linha de um DataFrame através das funções first e last, respectivamente. No contexto dos dados utilizados, a aplicação prática envolveria a obtenção da primeira e última medição de temperatura realizada pelos dispositivos:
# Importando funções
from pyspark.sql.functions import first, last
# Obtendo primeira e última medição de temperatura
df_iot.select(
first("temp").alias("primeira_temperatura"),
last("temp").alias("ultima_temperatura")
).show()
min e max
Considerando a possibilidade de extrair os extremos de uma dada informação com base em seu valor numérico, as funções min e max auxiliam, de maneira altamente intuitiva, na obtenção dos valores mínimo e máximo de um atributo contínuo de um DataFrame. Considerando a base de dados utilizada, ambas as funções poderiam ser aplicadas em conjunto para obter o pico e o vale de temperatura obtida no histórico de medições. Um filtro de escala foi adicionado na consulta para evitar que uma comparação indevida de valores de temperatura seja realizada:
# Importando funções
from pyspark.sql.functions import min, max
# Obtendo mínimo e máximo de temperatura
df_iot.where(col("scale") == "Celsius")\
.select(
min("temp").alias("min_temp"),
max("temp").alias("max_temp")
).show()
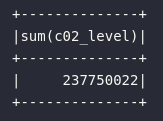
sum
A soma é uma função agregadora bastante comum em uma série de aplicações práticas de análise de dados. Imaginando sua utilização na base de sensores IoT, seria possível obter a somatória total de gás carbônico lida pelos sensores nas fábricas:
# Importando função
from pyspark.sql.functions import sum
# Soma total de nível de gás carbônico
df_iot.select(
sum("c02_level")
).show()
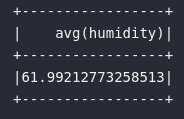
avg
Assim como a soma, a média também é uma função agregadora com papel extremamente representativo em análises reais de dados. Apesar de seu cálculo estar baseado na divisão entre soma e quantidade (sum / count), a utilização da função avg vai direto ao ponto. No contexto dos dados, seria possível aplicar tal função para a obter a umidade média medida pelos sensores:
# Importando função
from pyspark.sql.functions import avg
# Obtendo a umidade média da base
df_iot.select(
avg("humidity")
).show()
var e stddev
Aprofundando ainda mais na dinâmica estatística das análises fornecidas, a variância e o desvio padrão podem ser utilizadas de maneira isolada ou em conjunto para responder algumas questões específicas sobre o modelo de dados utilizado. Na prática, existe uma separação entre a aplicação das funções citadas em uma população ou em uma amostra e isto pode ser devidamente gerenciado pelas funções com sufixo _pop e _samp:
# Importando funções
from pyspark.sql.functions import var_pop, var_samp, \
stddev_pop, stddev_samp
# Obtendo variância e desvio padrão de gás carbônico
df_iot.select(
var_pop("c02_level").alias("var_pop_co2"),
var_samp("c02_level").alias("var_samp_co2"),
stddev_pop("c02_level").alias("stddev_pop_co2"),
stddev_samp("c02_level").alias("stddev_samp_co2")
).show()

Outras funções e formas de agregação
Existem, ainda, uma infindade de funções de agregação que podem ser utilizadas em fluxos de trabalho no Spark. Skewness, kurtosis, covariância e correlação são apenas mais alguns exemplos que seguem a mesma lógica de aplicação demonstrada anteriormente para todas as demais funções. Além disso, o Spark oferece funções capazes de agregar dados para tipos complexos, como o caso de collect_set() e collect_list().
A mensagem a ser passada neste momento é que, independente da necessidade de transformação de dados em um fluxo produtivo de trabalho, fatalmente opções de alto nível no Spark estarão disponíveis ao usuário.
Agrupamento
Na prática, a utilização de funções de agregação, de maneira isolada, contribuem apenas para análises ad-hoc e específicas onde existem necessidades especiais para visualizar pontualmente um valor de uma base de dados.
Considerando a expansão deste processo para a construção de bases agregadas de acordo com um contexto específico, a utilização de métodos de agrupamento permite avançar um nível a mais no processo analítico de dados.
Em essência, a geração de DataFrames agregados em Spark é realizada através da seguinte dinâmica:
- Primeiro, são especificadas as colunas (ou a coluna) alvo do processo de agregação, gerando assim um objeto do tipo
RelationalGroupedDataset - Na sequência, são aplicadas as funções de agregação, retornando assim um novo objeto do tipo
DataFrame
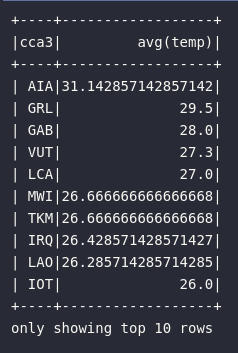
No exemplo abaixo, um bloco de código será estruturado para retornar os países com maior média de temperatura mensurada:
# Importando função
from pyspark.sql.functions import desc
# Retornando os países com maior média de temperatura
df_high_temp = df_iot\
.groupBy("cca3")\
.avg("temp")\
.orderBy(desc("avg(temp)"))
# Visualizando resultado
df_high_temp.show(10)
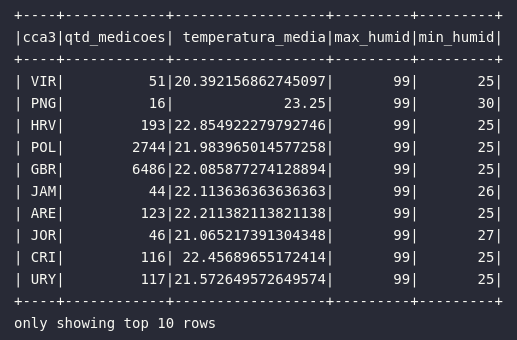
Entretanto, na dinâmica acima exemplificada, existe uma limitação sobre o uso de diferentes funções de agregação em diferentes colunas da base de dados. Em outras palavras, seria impossível calcular a média de temperatura e os valores máximo e mínimo de umidade por país.
Como em Spark quase tudo é possível, o cenário acima poderia ser facilmente codificado através da utilização do método agg() da seguinte forma:
# Coletando temperatura média e picos de umidade por país
df_iot\
.groupBy("cca3").agg(
count("device_name").alias("qtd_medicoes"),
avg("temp").alias("temperatura_media"),
max("humidity").alias("max_humid"),
min("humidity").alias("min_humid")
).orderBy(desc("max_humid")).show(10)
Além de tudo, expressões em Spark também poderiam ser utilizadas para obter resultados idênticos:
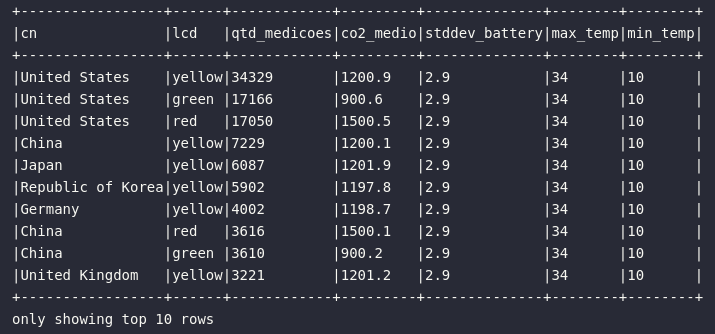
# Agrupando por país e lcd
df_iot.groupby("cn", "lcd").agg(
expr("count(1) AS qtd_medicoes"),
expr("round(avg(c02_level), 1) AS co2_medio"),
expr("round(stddev_pop(battery_level), 1) AS stddev_battery"),
expr("round(max(temp), 1) AS max_temp"),
expr("round(min(temp), 1) AS min_temp"),
).orderBy(desc("qtd_medicoes")).show(10, truncate=False)
Conclusão e encerramento
Adicionar possibilidades de agregação e agrupamento em pipelines de transformação de dados é um ganho extremamente valioso dentro dos objetivos de aprendizado no ramo do Spark. No presente artigo, vimos como as funções de agregação podem ser utilizadas em conjunto com os métodos groupBy() e agg() para construir as mais variadas análises dentro das necessidades existentes.
Adicionalmente, todos os métodos já abordados até aqui podem ser utilizados em conjunto para a criação de planos de transformações cada vez mais ricos em detalhes. Com isto em mente, nos aproximamos aos poucos de um nível de conhecimento suficientemente rico a ponto de nos proporcionar a autonomia necessária para a construção de fluxos de trabalho complexos.
Foi ótimo ter você aqui, caro leitor! Até a próxima!




