

Leitura de Fontes Externas com DataFrameReader
Explorando as nuances do processo de leitura e obtenção de dados oriundos de fontes externas

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! Após uma longa e fundamental jornada de entendimento em tópicos essenciais como aplicações Spark, objeto de sessão, distribuição dos dados e DataFrames como APIs estruturadas, podemos dizer, com extrema alegria, que alcançamos um ponto no aprendizado que nos permite mergulhar em interações majoritariamente práticas!
Neste artigo, será proposta uma consolidação dos assuntos abordados até o momento com um direcionamento específico em uma temática primordial na grande maioria dos pipelines de dados: a leitura de dados presentes em fontes externas.
De modo a proporcionar exemplos práticos capazes de serem utilizados em qualquer fluxo de trabalho real, os códigos aqui escritos visam fornecer um panorama completo sobre como ler dados oriundos de fontes externas em seus mais variados formatos. Quer saber como utilizar o Spark para ler arquivos csv, json, orc, avro ou parquet? Embarque nessa jornada!
Sobre as fontes utilizadas
Para a exploração prática proposta, será utilizado um conjunto de dados contendo informações sobre vôos retirados do Bureau estatístico de transportes dos Estados Unidos. Obtido através do GitHub oficial do livro Spark: The Definitive Guide, o conjunto de dados possui versões em diferentes formatos de arquivos (csv, json, avro, orc e parquet), permitindo construir exemplos que abrangem grande parte dos cenários práticos.
Cada registro das bases, independente do formato, representa a quantidade de vôos realizados partindo de uma determinada origem até um determinado destino. Para maiores detalhes, a tabela abaixo pode ser utilizada como metadados do conjunto:
| Coluna | Tipo Primitivo | Descrição |
| DEST_COUNTRY_NAME | string | País de destino da viagem |
| ORIGIN_COUNTRY_NAME | string | País de origem da viagem |
| count | integer | Quantidade de viagens realizadas da origem para o destino |
Para a obtenção dos arquivos a serem utilizados nas demonstrações subsequentes, bastas clonar o repositório oficial referenciado acima através do seguinte comando:
git clone https://github.com/databricks/Spark-The-Definitive-Guide.git
Uma vez conhecidas as bases de dados, é preciso preparar o ambiente para receber os códigos em Spark.
Criando sessão e variáveis adicionais
O âmbito prático de trabalho envolve um ambiente virtual Python pré configurado com pyspark e Jupyter Notebook. Assim, como um primeiro passo preparatório, será proposto:
- Importação das bibliotecas e módulos necessários
- Configuração de um objeto de sessão do Spark
- Definição das variáveis de referência de acordo com a localização dos arquivos
# Importando bibliotecas
from pyspark.sql import SparkSession
import os
# Inicializando sessão
spark = (SparkSession
.builder
.appName("art05-leitura-e-escrita")
.getOrCreate())
# Definindo variáveis de diretório para leitura dos arquivos
parent_dir = ''.join(os.path.pardir + "/") * 3
flights_dir = os.path.join(parent_dir, 'data/flights-data/summary-data')
# Definindo variáveis de leitura para cada formato
csv_data_path = os.path.join(flights_dir, 'csv/2015-summary.csv')
json_data_path = os.path.join(flights_dir, 'json/2015-summary.csv')
orc_data_path = os.path.join(flights_dir, 'orc/2010-summary.orc/part-r-00000-2c4f7d96-e703-4de3-af1b-1441d172c80f.snappy.orc')
avro_data_path = os.path.join(flights_dir, 'avro/part-00000-tid-7128780539805330008-467d814d-6f80-4951-a951-f9f7fb8e3930-1434-1-c000.avro')
parquet_data_path = os.path.join(flights_dir, 'parquet/2010-summary.parquet/part-r-00000-1a9822ba-b8fb-4d8e-844a-ea30d0801b9e.gz.parquet')
Considerando o download das bases de dados através do link fornecido na seção acima, além do desejo dos leitores em simular os códigos aqui apresentados em seus próprios ambientes, é preciso atentar-se à configuração das variáveis que referenciam os locais dos arquivos a serem lidos.
Para a criação dos exemplos, os arquivos de leitura foram posicionados à três níveis anteriores em relação ao diretório onde o Jupyter Notebook foi instanciado. Em outras palavras, o caminho ../../../data/flights-data/ foi escolhido para armazenamento dos dados e, no bloco de código acima, as variáveis que representam essa informação são parent_dir e flights_dir. Altere-as conforme o local escolhido para o armazenamento dos conjuntos de dados em sua máquina.
Adicionalmente, foi criada uma variável para representação de cada caminho individual dos arquivos para cada formato específico, facilitando assim as demonstrações. Estas variáveis não precisam ser modificadas pelo leitor (a não ser que os responsáveis pelo compartilhamento público dos dados realizem modificações nos mesmos)
Um pouco de teoria: a classe DataFrameReader
Como de costume, é sempre importante ter em mente algumas explicações sobre como as coisas realmente funcionam na dinâmica do Spark. Para a leitura de dados, o Spark uma classe central denominada DataFrameReader que, por sua vez, disponibiliza uma série de atributos, métodos e configurações adicionais que podem ser programadas de modo a parametrizar a leitura de fontes externas conforme as características existentes no processo.
Em outras palavras, a leitura de um arquivo CSV pode ser extremamente semelhante à leitura de um arquivo JSON, com a diferença de um ou mais parâmetros de configuração a serem passados nas chamadas do DataFrameReader. Nada mais explicativo do que visualizar na prática.
Como informado anteriormente, o Spark utiliza o elemento DataFrameReader para leitura de fontes externas de dados. De maneira geral, uma versão simplificada da sintaxe utilizada pode ser visualizada abaixo:
DataFrameReader.format(args).option("key", "value").schema(args).load(path)
Para um entendimento mais claro de como este processo funciona, é importante analisar separadamente cada elemento que compõem a sintaxe acima exemplificada.
| Bloco de código | Descrição | Exemplo |
.format(args) | Referencia o tipo de fonte de dados a ser lida no objeto DataFrameReader | .format("csv") |
.option("key", "value") | Configura opções de leitura que podem ser características do formato da fonte de dados a ser lida. Em outras palavras, arquivos no formato CSV podem conter a informação de cabeçalho na primeira linha, diferente de arquivos em outros formatos. Na prática, para cada formato, uma série de opções podem ser sequencialmente chamadas de modo a configurar a leitura da forma esperada pelo usuário. | .option("header", "true") |
.schema(args) | Define um schema explícito para a leitura da fonte de dados. Por mais recomendado que seja utilizar este bloco, principalmente em fluxos produtivos, seu uso é opcional e pode ser substituído pela opção .option("inferSchema", "true" que possibilita que o Spark faça seu melhor para inferir o schema dos dados por conta própria | .schema(data_schema) onde data_schema pode ser uma variável do tipo StructType com os campos e tipos primitivos bem definidos |
.load(path) | Por fim, este é o bloco responsável pela leitura e que aponta para o caminho dos dados a serem lidos | .load('../data.csv') |
Tecnicamente, a classe DataFrameReader funciona como uma interface para a leitura de dados de fontes externas e seu acesso pode ser obtido através módulo SparkSession.read. Os métodos associados podem receber uma série de argumentos que dependem da fonte de dados utilizada.
De acordo com a documentação oficial da classe, uma série de outros blocos podem ser utilizados na chamada e é sempre importante consultar as opções para adequar os comandos às reais necessidades de um fluxo de dados.
Mãos à obra: exemplos de leitura de dados
Agora que o conhecimento adquirido permite entender a fundo os processos de leitura de fontes externas no Spark, é chegado o aguardado momento de colocar a mão na massa e codificar alguns exemplos envolvendo a leitura de arquivos nos mais variados formatos.
Considerando a preparação prévia fornecida no início deste artigo para criação da sessão e definição de variáveis utilizadas para leitura dos dados, cada subtópico abaixo irá alocar exemplos práticos para leitura de arquivos em um formato específico.
Leitura de arquivo CSV
O bloco de código abaixo pode ser utilizado para realizar a leitura de um arquivo CSV no Spark:
# Realizando a leitura de arquivo CSV com opções características
df_csv = (spark.read.format("csv")
.option("inferSchema", "true")
.option("header", "true")
.load(csv_data_path))
# Visualizando resultado
df_csv.show(10)
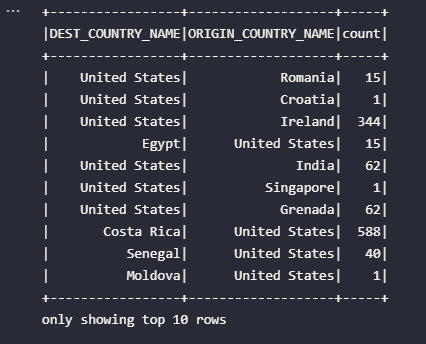
Por ser o primeiro exemplo fornecido, vale registrar algumas explicações adicionais:
- O objeto de sessão é representado pela variável
spark - A classe
DataFrameReaderé invocada neste bloco a partir do métodospark.read - O resultado do comando de leitura é um objeto do tipo
DataFrame - A opção
.option("header", "true")indica que o arquivo alvo possui a informação de header na primeira linha, evitando assim que o DataFrame obtido registre essa informação como uma linha indesejada - A opção
.option("inferSchema", "true")permite que o Spark realize a inferência do schema dos dados por conta própria a partir da leitura de uma pequena parcela da base
A partir destes pontos de destaque, em especial o último, é possível então verificar o schema do DataFrame obtido através do processo de leitura:
df_csv.printSchema()
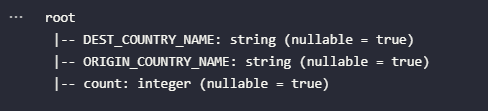
Considerando o conhecimento prévio no conteúdo do arquivo a partir de seus metadados já fornecidos, é possível concluir que o Spark fez um bom trabalho ao inferir o schema por conta própria. Geralmente, os resultados são sempre fiéis ao conteúdo das fontes externas, mas em cenários onde possíveis falhas na geração dos dados possam ocorrer, é sempre importante definir um schema explícito e adicionar esta configuração no bloco de leitura, garantindo assim que o processo não irá propagar possíveis erros (ex: colunas indesejadas, tipos primitivos incorretos, colunas faltantes, entre outros). O próximo exemplo de leitura de arquivos irá considerar uma definição explícita de schema com tipos primitivos do Spark para leitura de um arquivo JSON.
Leitura de arquivo JSON
No decorrer dos exemplos fornecidos, será possível perceber que a estrutura dos blocos de código utilizados possuem grande semelhança umas com as outras. As mudanças estão basicamente atreladas à opções distintas que podem existir e fazer sentido para um formato, mas não para outro. Exemplificando, definir a opção .option("header", "true") pode não ser aplicável à arquivos JSON pela própria construção do formato, diferente de arquivos CSV onde o cabeçalho eventualmente pode existir na primeira linha dos arquivos.
Diante disso, visando explorar o máximo de possibilidades existentes, sempre que um novo exemplo for codificado, algum cenário específico e diferente do anterior será também adicionado.
Neste caso, a proposta do bloco de código abaixo é realizar a leitura de um arquivo JSON, porém com uma definição explícita de schema, sendo esta realizada através dos seguintes passos:
- Importação de tipos primitivos nativos do Spark através do módulo
pyspark.sql.types - Criação de uma variável de schema através de uma lista de objetos do tipo
StructType - Aplicação do comando de leitura via
DataFrameReadercom o método.schema()vinculado
# Importando tipos primitivos
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
# Definindo schema
flights_schema = StructType([
StructField("DEST_COUNTRY_NAME", StringType(), nullable=True),
StructField("ORIGIN_COUNTRY_NAME", StringType(), nullable=True),
StructField("count", IntegerType(), nullable=True)
])
# Realizando a leitura de arquivo JSON com schema explícito
df_json = (spark.read.format("json")
.schema(flights_schema)
.load(json_data_path))
# Verificando schema
print(df_json.printSchema())
# Visualizando resultado
df_json.show(10)
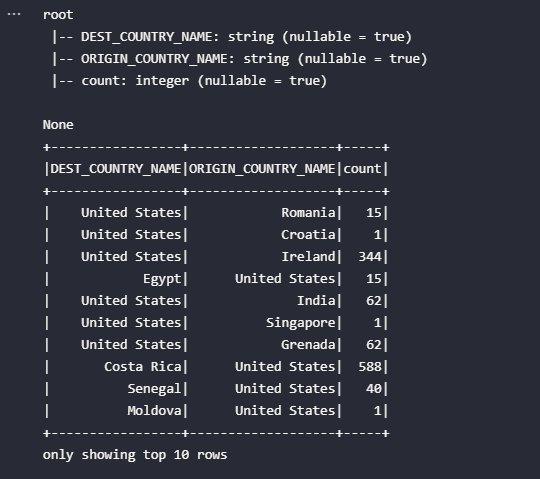
O resultado obtido permite validar que o processo de leitura foi realizado com sucesso. O schema definido de maneira explícita foi aplicado e corresponde ao conteúdo do arquivo alvo. Entretanto, nem sempre o mundo real é de tal forma amigável. Alguns problemas de leitura de arquivos fatalmente poderão ocorrer em cenários do dia a dia.
Assim, de modo a exemplificar possíveis cenários reais onde nem tudo funciona da melhor maneira possível, será proposta uma sutil modificação na variável flights_schema para considerar propositalmente a alteração do nome da coluna count para contagem. O que pode se esperar do resultado após essa modificação?
# Novo schema (com erro proposital)
flights_schema = StructType([
StructField("DEST_COUNTRY_NAME", StringType(), nullable=True),
StructField("ORIGIN_COUNTRY_NAME", StringType(), nullable=True),
StructField("contagem", IntegerType(), nullable=True) # Alteração no nome da coluna
])
Após executar novamente a célula, o DataFrame obtido possui o seguinte formato:
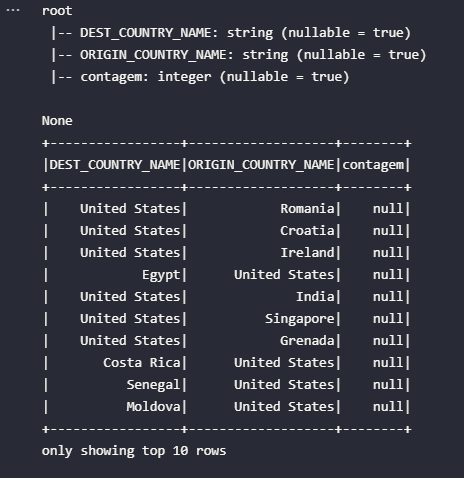
Em primeiro lugar, o resultado do método printSchema() permite dizer que o schema dos dados considerado pelo Spark foi, de fato, o mesmo definido pela variável flights_schema após a alteração proposital. Isto pois a última coluna possui o nome de contagem e não mais count, como anteriormente.
Por outro lado, como não é possível encontrar uma coluna chamada contagem no interior do arquivo JSON utilizado como alvo, o Spark simplesmente trouxe uma coluna preenchida totalmente com dados nulos. Em cenários reais, isto poderia causar erros cruciais de difícil mensuração de impacto.
Problemas como este evidenciado acima são característicos de fluxos de trabalho que dependem de um schema bem definido na origem. Mas, e se fosse possível utilizar fontes de dados que já considerassem esse elemento de maneira interna ao próprio arquivo?
Leitura de arquivos ORC e PARQUET
Arquivos nos formatos ORC e PARQUET são utilizados em larga escala em fluxos de dados no universo de Big Data. O objetivo deste artigo não é entrar em detalhes em características específicas destes dois formatos mas, em linhas gerais, é possível destacar uma propriedade interessante sobre os mesmos que influencia diretamente o comando utilizado para suas respectivas leituras no Spark: o conceito de schema builti-in.
Na prática, arquivos ORC e PARQUET possuem as definições de schema já inclusas por natureza, o que elimina qualquer necessidade de inferência automática de schema por parte do Spark ou mesmo definições explícitas por parte do usuário. Dessa forma, o bloco abaixo configura exemplos para leitura dos dados de vôos presentes nos formatos ORC e PARQUET:
# Lendo arquivo ORC
df_orc = spark.read.format("orc").load(orc_data_path)
# Lendo arquivos parquert
df_parquet = spark.read.format("parquet").load(parquet_data_path)
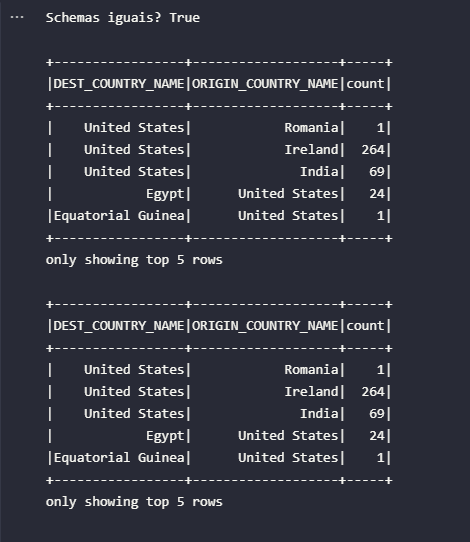
Para validar a propriedade de schema built-in mencionada, o bloco de código abaixo é responsável por comparar os schemas de ambos os DataFrames gerados. Na sequência, uma amostra de 5 registros será mostrada para cada formato lido.
# Validando schema
print(f'Schemas iguais? {df_orc.schema == df_parquet.schema}\n')
# Amostra orc
df_orc.show(5)
# Amostra parquet
df_parquet.show(5)
E assim, o objetivo em demonstrar alguns comandos em Spark para realizar a leitura de arquivos nos mais variados formatos foi concluído! Ao longo do processo de aprendizado, novos exemplos poderão ser alocados neste mesmo artigo para futuras consultas.
Conclusão e encerramento
Como informado anteriormente, a leitura de dados presentes em fontes externas é uma ação primordial em grande parte dos fluxos de trabalho no universo de Big Data. Atuando muitas vezes como a primeira etapa de cadeiras de transformação, a obtenção dos dados é fundamental para a aplicação do processo de ETL e análises em geral.
Em um ambiente Spark, as APIs estruturadas de alto nível proporcionam uma abstração magistral para o usuário, facilitando seu uso para as mais variadas operações. Neste caso, a classe DataFrameReader existe e pode ser amplamente utilizada para o propósito temático deste artigo.
Espero que o conteúdo aqui consolidado tenha sido aproveitado tanto quanto possível. Aguardo vocês no próximo artigo!




