

O que é o Apache Hive?

Hive é uma ferramenta capaz de utilizar queries SQL em petabytes de dados no Hadoop, permitindo utilizá-lo como uma espécie de data warehouse. A Hive Query Language (HQL) possui uma semântica estritamente similar ao padrão SQL utilizado em bancos de dados relacionais, possibilitando aos analistas com familiaridade à esta sintaxe atuarem com extrema facilidade. A linguagem HQL também pode ser utilizada em conjunto com diversos motores computacionais, como MapReduce, Tez e Spark.
Trecho adaptado do livro Apache Hive Essentials, de Dayong Du
Introdução e Boas Vindas
Bem-vindos ao primeiro artigo da série Transformando Dados com Apache Hive! Em sua concepção, a série foi idealizada para proporcionar uma visão teórica e prática sobre a utilização do Hive em conjunto com o Hadoop para a solução de problemas de Big Data utilizando a linguagem HQL (Hive Query Language). Com este objetivo em mente, o conteúdo a ser disponibilizado ao longo desta jornada visa consolidar detalhes sobre o funcionamento do Hive, sua instalação em uma máquina virtual Linux para testes práticos, sintaxe DQL, DML, DDL, DCL, otimização de consultas e muitos outros tópicos que, juntos, contribuem para garantir uma completa autonomia no uso desta ferramenta para os mais variados propósitos.
As referências utilizadas ao longo de toda a jornada de aprendizado serão fornecidas sempre ao final de cada artigo, permitindo ao leitor um maior aprofundamento do conhecimento com base em fontes especialmente selecionadas para proporcionar uma experiência incrível.
Como grande recomendação aos leitores, a série Visão Geral do Ecossistema Hadoop, presente neste mesmo blog, pode ser utilizada como grande complemento aos ensinamentos a serem consolidados nesta série sobre o Hive. Afinal, partir para uma jornada Hive sem ter conhecimentos básicos sobre Hadoop pode ser algo relativamente desafiador.
E assim, a série Transformando Dados com Apache Hive tem seu início com um artigo altamente relevante que irá definir o Hive em um contexto histórico.
Uma Breve História
Segundo Dayong Du, no livro Apache Hive Essentials, o surgimento da linguagem SQL (Structured Query Language) trouxe uma extrema simplicidade e facilidade aos usuários que, motivados pelas grandes possibilidades nos âmbitos de organização e transformação dos dados, difundiram o uso da linguagem. Tão logo quanto perceptível, bancos de dados relacionais estavam em todos os lugares!
Com o decorrer dos anos, uma série de dados já haviam sido coletados e, de certa forma, iniciou-se uma preocupação sobre como trabalhar com essa grande quantidade de dados históricos. Assim, o termo "Data Warehousing" surgiu em meados da década de 90 como uma forma de organizar essa necessidade de observar e tratar dados do passado e armazenados, até este ponto, de forma estruturada.
Nos anos 2000, a grande difusão da internet, de tecnologias IoT (Internet of Things) e de uma variedade de outros elementos atuaram para transformar a lógica de análise de dados existente na época. Dados chegavam a todo instante, em uma incrível variedade e em volumes antes jamais experimentados. Neste cenário, tecnologias emergentes como o Hadoop, por exemplo, se mostraram altamente poderosas e, rapidamente, foram adotadas pela comunidade para solucionar os mais variados desafios nesta nova era do Big Data.
Como um grande marco nesta era de transição, em abril de 2011, o Hadoop foi então integrado e lançado pela Apache Software Foundation em sua versão 1.0.0, contendo o HDFS (sistema de armazenamento distribuído) e o MapReduce (modelo de programação paralela). Com a crescente demanda de ferramentas de analytics de Big Data, tão logo o "ecossistema Hadoop" foi sendo construído e alimentado pela comunidade com as mais variadas soluções tecnológicas. Na imagem abaixo, uma ilustração de alguns dos componentes deste ecossistema pode ser visualizada e, como destaque especial, o Hive pode ser encontrado na categoria SQL Over Hadoop junto a soluções como o Apache Drill e o Apache Impala.

E assim, na dinâmica atual de implementação de soluções específicas dentro dos anseios tecnológicos na era do Big Data, engenheiros, arquitetos, cientistas, analistas, estudantes ou até mesmo entusiastas do universo de dados utilizam, desenvolvem e contribuem para a difusão de componentes e ferramentas realmente capazes de proporcionar um impacto positivo na comunidade. De acordo com os propósitos deste artigo, é imprescindível pontuar o Apache Hive como uma dessas ferramentas responsáveis por uma grande mudança na forma como usuários construíam pipelines de transformação de dados. Afinal, possibilitar a utilização da linguagem SQL para manusear dados em sistemas de armazenamento distribuído abriu caminho para uma grande gama de possibilidades analíticas.
Porém, antes de definir exatamente como essa relação entre SQL, Big Data e sistemas de armazenamento distribuído realmente funciona, é importante realizar algumas comparações práticas para fixar o entendimento da linguagem HiveQL.
RDMBS x Armazenamento em Big Data
Como mencionado anteriormente, até certo ponto da história, bancos de dados relacionais atuavam como soluções fixas e determinísticas para todo e qualquer projeto envolvendo armazenamento, organização e transformação de dados através da linguagem SQL. Dessa forma, visando exemplificar o funcionamento do Hive como uma ferramenta capaz de utilizar uma linguagem similar ao SQL para processar dados armazenados em sistemas distribuídos, é importante trazer à tona alguns conceitos clássicos envolvendo bancos de dados relacionais.
Assim, considerando o ato de criação de uma tabela (CREATE TABLE) em um RBDMS (Relational Database Management System), as ações realizadas pelo sistema giram em torno dos seguintes tópicos:
- É realizada uma verificação de consistência das chaves estrangeiras
- São estabelecidos os arquivos e os índices necessários para armazenar a tabela
- Todos os detalhes adicionais da tabela são então armazenados em uma parte especial do banco de dados chamado de dicionário de dados
Neste contexto, a dinâmica de operação em um sistema de gerenciamento de bancos de dados relacionais exige a utilização de SQL para toda e qualquer operação a ser realizada. Algumas referências técnicas e fontes de consulta associam este comportamento ao termo "always think in SQL" pois, de fato, os dados são escritos, lidos e acessados sempre através de queries SQL. O dicionário de dados atua como um elemento altamente acoplado às tabelas presentes no banco de dados, gerenciando toda e qualquer alteração nos formatos estruturados dos dados nelas armazenados.

Já no contexto do Big Data, uma série de novos fatores são inclusos para disponibilizar um sistema capaz de gerenciar os massivos volumes de dados estruturados e não estruturados em uma organização chamada de Data Lake. Nesse cenário, não há um dicionário de dados altamente acoplado à estrutura dos dados pois sequer há o conceito de "tabela" como conhecido previamente em bancos de dados relacionais.
De forma simplificada, os dados estão normalmente posicionados em um sistema de armazenamento distribuído e detalhes sobre seus respectivos conteúdos são organizados em uma camada altamente desacoplada chamada de metastore. Dessa forma, ferramentas como Hive e Impala conseguem se aproveitar deste modelo organizacional para compreender os metadados presentes nos arquivos fisicamente armazenados no cluster de computadores e utilizar linguagens similares ao SQL para retornar, transformar e gerenciar os dados. Além disso, neste sistema organizacional, como os dados estão armazenados em blocos espalhados em diferentes nós de um cluster, ferramentas externas são capazes de acessar os dados para a realização de operações adicionais.
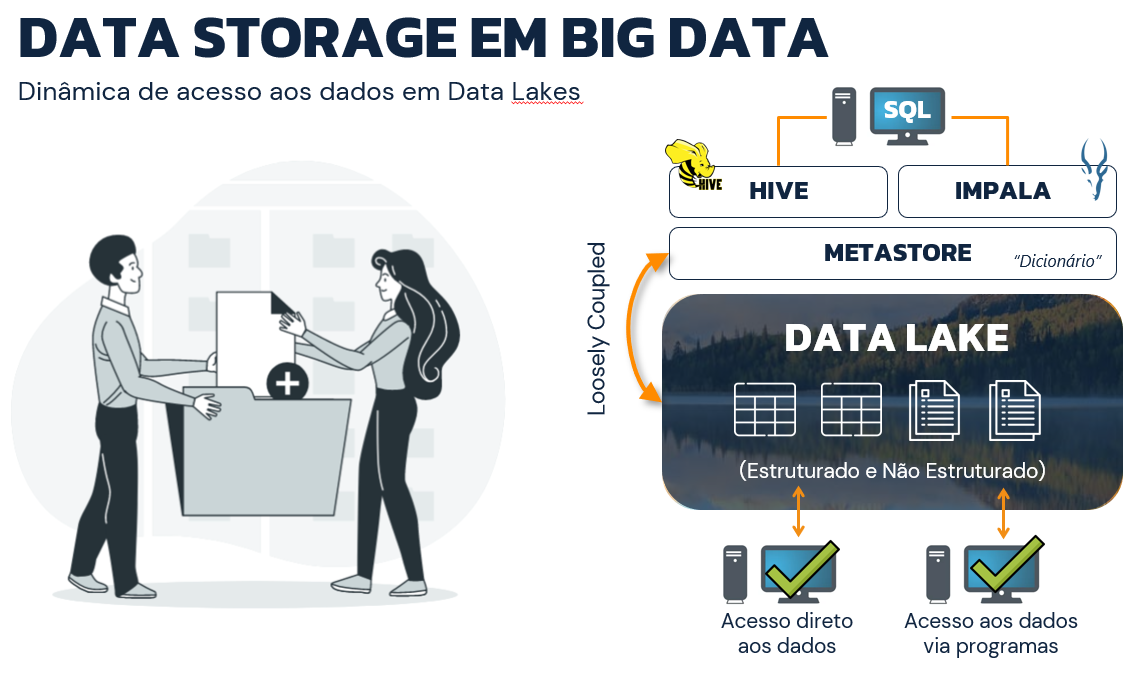
Com isso, pode-se então obter uma visão clara sobre as principais diferenças entre bancos de dados relacionais e a dinâmica de utilização de Data Lakes em cenários de Big Data. No livro Apache Hive Essentials, Dayong Du defende que a estrutura de metadados do Hive é normalmente o schema no conceito de schema-on-read do Hadoop. Em outras palavras, isto significa que os usuários não precisam necessariamente definir o schema no Hive antes de armazenar os dados no HDFS, cenário este totalmente distinto da dinâmica encontrada em bancos de dados relacionais.
Hive: Definição e Aplicação
Por maiores que tenham sido os pontos destacados sobre o Hive até este momento, é importante referenciar definições oficiais sobre esta importante ferramenta para que se tenha uma visão clara de quem esteve diretamente envolvido em sua construção e difusão.
"O Hive é uma solução de Data Warehousing que facilita a leitura, escrita e gerenciamento de dados em larga escala presentes em sistemas de armazenamento distribuído utilizando linguagem SQL."
Trecho retirado do site oficial hive.apache.org
Muitos dos termos presentes na definição oficial do Hive foram, de fato, abordados em seções anteriores neste artigo, justificando assim a importância da introdução e do contexto fornecido previamente.
Indo além, a definição abaixo foi retirada de uma página da AWS e traz, da forma mais objetiva possível, a atuação do Hive em cenários práticos de Big Data:
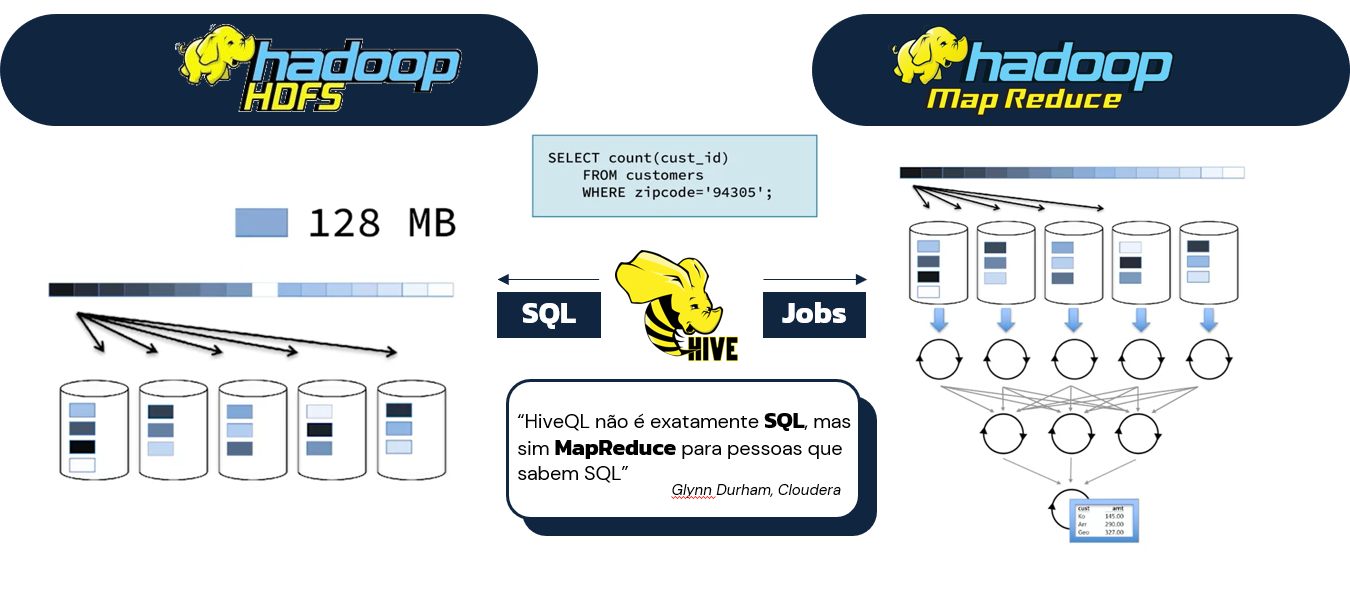
"O Hive transforma queries escritas em HiveQL em jobs MapReduce ou Tez que são executados no framework Hadoop através do YARN."
Trecho retirado de artigo disponibilizado na AWS
O trecho acima possui uma carga técnica um pouco mais avantajada sobre o Hive provocando o entendimento de que, ao mesmo tempo que o Hive possui uma dinâmica eficiente de acessar e manusear dados em uma linguagem similar ao SQL, ele também possui significativas diferenças em seu modo de operação, atuando diretamente com modelos de programação que não fazem parte do cotidiano da própria linguagem SQL. Para reforçar este ponto, a definição simplificada abaixo traz uma visão disruptiva sobre a forma de atuação do Hive e de sua linguagem de programação.
"HiveQL não exatamente SQL, mas sim MapReduce para pessoas que sabem SQL."
Glynn Durham, instrutor da Cloudera e um dos pontos focais na especialização Modern Big Data Analysis with SQL do Coursera
Assim, considerando sua aplicação prática nos cenários trazidos pelas definições acima, o Hive está diretamente relacionado aos conceitos de armazenamento e processamento distribuído, atuando substancialmente na possibilidade de trazer uma forma amigável, fácil e eficiente aos usuários para que estes possam extrair valor de dados armazenados em um cluster de computadores.
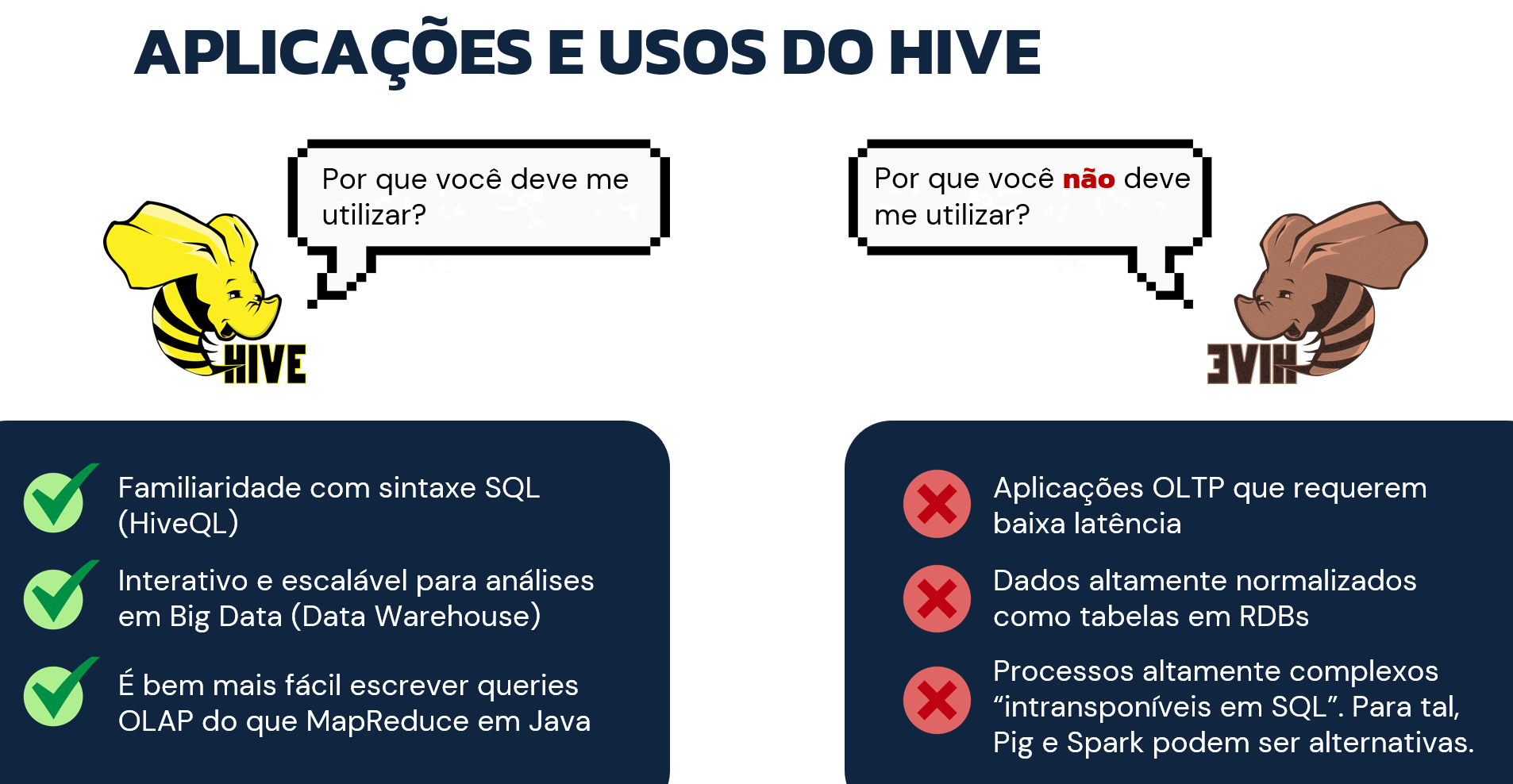
Por fim, considerando todos os elementos fornecidos para definir o Hive até aqui, a imagem abaixo atua como um grande resumo sobre onde o Hive realmente pode ser utilizado com um impacto positivo e também onde seu uso não é o mais indicado.
Detalhes Técnicos do Hive
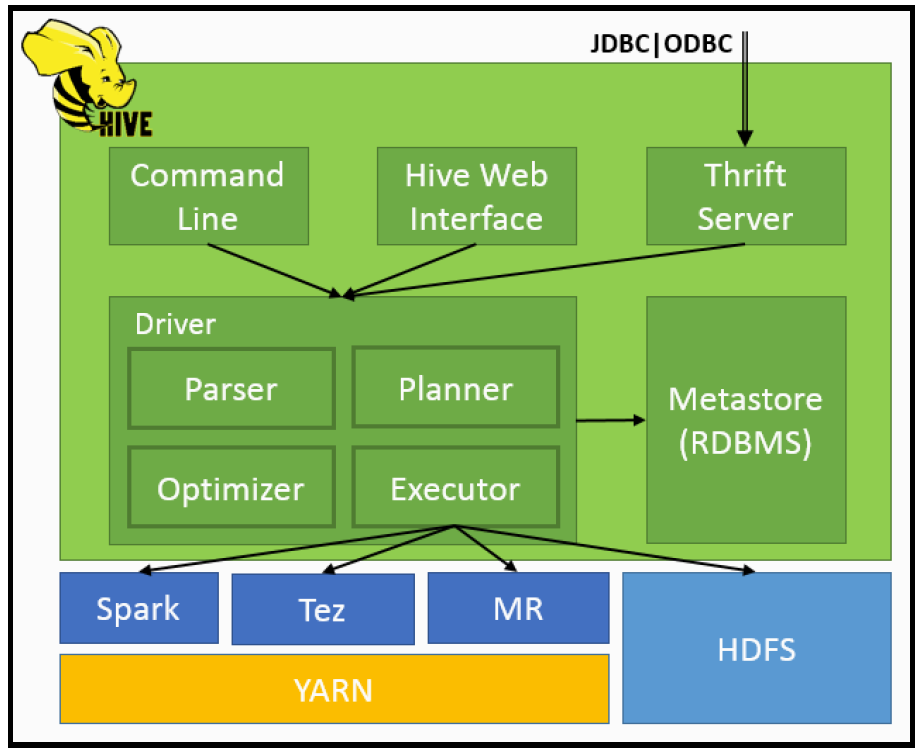
Sob o ponto de vista de arquitetura, o Hive possui uma série de componentes responsáveis por gerenciar seu funcionamento. O sistema de armazenamento de metadados (conhecido popularmente como Hive metastore) pode utilizar bancos de dados locais ou remotos. Em sua última versão, o Hive conta com o servidor hiveserver2 capaz de gerenciar múltiplos clients, autenticação via Kerberos, LDAP e opções para conexões JDBC e ODBC, especialmente para acesso aos metadados. De forma ilustrativa, a imagem abaixo foi extraída do livro Apache Hive Essentiais de Dayong Du e demonstra os componentes de arquitetura do Hive.
Como complemento, o livro Programming Hive de Jason Rutherglen, Dean Wampler e Edward Capriolo reforça que existem diferentes formas de se interagir com o Hive em um ambiente prático de trabalho. Normalmente, ferramentas de interface de comando, com o Hive CLI e o beeline são a porta de entrada para novos usuários. Entretanto, componentes visualmente amigáveis e interfaces open source como o Apache Ambari ou o HUE também desempenham um papel extremamente importante em sua utilização.
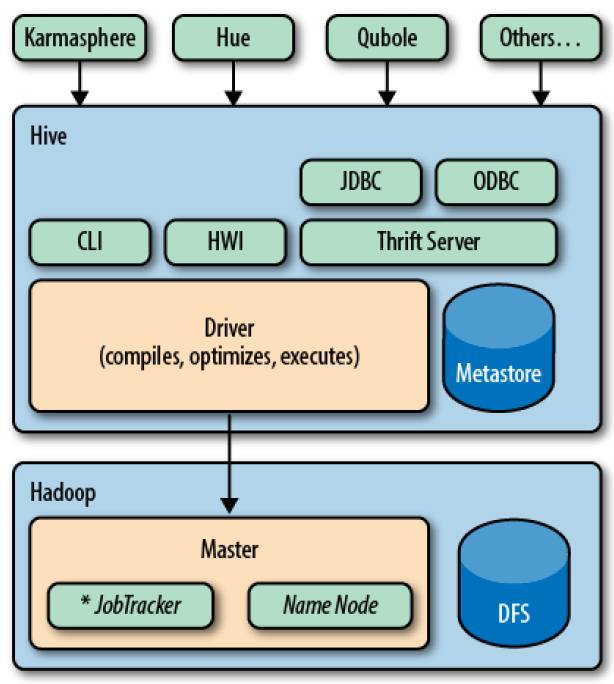
Considerando seu uso prático, sempre que uma query é executada em HiveQL, todo o esforço de compilação é realizado no driver que, por sua vez, é responsável por tratar a solicitação, otimizar a computação requerida e executar os passos demandados normalmente como jobs de MapReduce, Tez ou Spark. Neste caso, o Hive não gera programas de MapReduce nativos em Java, mas sim utiliza módulos built-in de mapeamento e redução.
E assim o Hive demonstra seu poder como uma solução efetiva para transformação e análise de dados em um cenário OLAP (Online Analytical Process) de Big Data. Sua ampla utilização na cadeia produtiva de dados reforça o importante papel fundamentado pelo Hive no ecossistema Hadoop.
Conclusão
Ao longo deste artigo, foram apresentados tópicos essenciais sobre o Apache Hive dentro dos âmbitos técnico, teórico e prático. A partir desta leitura, foi possível compreender como os anseios do universo tecnológico de dados evoluíram a ponto de demandar soluções capazes de gerenciar dados em cenários antes jamais experimentados. Neste contexto, o Hive surge como uma solução eficiente e amigável capaz de proporcionar, à seus usuários, o uso de uma linguagem similar ao SQL para transformar e analisar dados no cenário do Big Data.
Por fim, entre alguns tópicos fundamentais que podem ser consolidados e resumidos sobre as principais características do Hive, é possível citar:
- É muito mais fácil construir uma query em HQL do que um job em MapReduce
- HQL e SQL possuem sintaxes similares
- É possível executar o Hive em diferentes frameworks. MapReduce, Tez e Spark são alguns dos exemplos mais comuns.
- O Hive suporta queries ad hoc no HDFS e no HBase
- O Hive suporta UDFs (User Defined Functions) escritas em Java ou Scala como extensão de suas funcionalidades
- Drivers JDBC e ODBC expõem o Hive à aplicações que desejam manipular dados, como por exemplo, ferramentas de visualização
- O Hive permite usuários a ler dados em formatos arbitrários utilizando serializadores e desserializadores (SerDes)
- O Hive é uma ferramenta de processamento em batch




