




Table of contents
Inauguração da série
Olá pessoal, bem vindos ao primeiro artigo da série Visão Geral do Ecossistema Hadoop! Espero que todos tenham uma excelente jornada de consumo das informações aqui estabelecidas e que o conteúdo compartilhado realmente mude os ponteiros de aprendizado neste gigantesco universo do Hadoop.
A grande ideia por trás desta série é abordar, de forma simplificada, tópicos relacionados ao ecossistema Hadoop. Englobando teoria e prática, os artigos aqui escritos poderão ser utilizados como guias para os mais variados propósitos, desde um entendimento básico sobre o sistema de armazenamento distribuído do Hadoop, até a utilização de tutoriais práticos de instalação de um cluster Hadoop no modo pseudo-distribuído.
Este é verdadeiramente um assunto que me encanta e, de alguma forma, espero passar todo este entusiasmo pra você que pretende acompanhar as postagens. Minha expectativa é que possamos, ao longo do caminho, aprender muito sobre este universo e explorar conceitos essenciais para um entendimento geral sobre o Hadoop e seus diversos componentes para soluções de Big Data.
Vamos nessa!
Big Data hoje, Big Data amanhã, Big Data sempre!
Seria impossível inaugurar uma série sobre o framework Hadoop sem antes falar a respeito de Big Data. Já há alguns anos, este termo acompanha desenvolvedores, analistas, cientistas de dados, engenheiros e até mesmo entusiastas que estão iniciando suas trilhas de aprendizado.
De fato, falar sobre Big Data nos dias atuais já não é mais um tabu para profissionais ou estudiosos da área. Há muito, o professor Daniel do portal Data Science Academy reforçava aos seus alunos que "os dados são o novo petróleo", indicando que a riqueza de grande parte das operações envolvendo análise, modelagem, estatística e engenharia provém dos dados.
E por mais transparente que seja esta convivência na era moderna, os dados realmente estão em todo lugar. Em uma espécie de metáfora, este mesmo artigo, escrito nesta plataforma, de alguma forma, contribui para a geração de dados que podem eventualmente ser tratados, analisados, transformados e utilizados nas mais variadas operações analíticas. Tudo fica ainda mais interessante ao imaginar quantos artigos estão sendo escritos e lidos neste exato segundo.
Como informado previamente, é imprescindível tecer detalhes sobre esta moderna era do Big Data antes de mergulhar em tópicos relacionados ao framework Hadoop. Ao longo do trajeto, será possível entender que ambos os tópicos estão intimamente ligados.
O que é o Big Data?
A pergunta do milhão. A definição do termo "Big Data" não pode ser dada em apenas uma frase ou um simples trecho textual. Antes, é preciso trazer um leve contexto histórico sobre como a tecnologia e a relação de análise e armazenamento de dados evoluiu (e continuam evoluindo) até os dias atuais.
Até certo tempo na era tecnológica, dados estruturados e em volumes moderados eram basicamente a essência do cenário analítico. De certa forma, os sistemas responsáveis por processar e analisar dados neste contexto suportavam com tranquilidade as simples (sob uma ótica atual) exigências estabelecidas. Afinal, a estruturação dos dados é a principal premissa de bancos de dados relacionais e, de maneira semelhante, os volumes moderados da época eram tranquilamente suportados por um armazenamento em disco padrão em uma única máquina.
Entretanto, ao longo dos anos, as tecnologias emergentes e as relações humanas transformaram o universo de dados como um todo. Em uma espécie de caldeirão temporal, uma série de elementos surgiram de modo a acelerar exponencialmente a forma clássica de geração, armazenamento e análise de dados. Para citar alguns ingredientes, a própria internet e dispositivos IoT (Internet of Things, ou internet das coisas) começaram sua contribuição para uma necessidade brutal: não dava mais para gerenciar essa dinâmica de dados na velocidade exigida com as ferramentas existentes. Alguma coisa precisava ser feita.
A partir deste ponto, o mundo de tecnologia começou a se movimentar para entender a melhor forma de se adequar a este novo cenário, desenvolvendo ferramentas capazes de gerenciar grandes quantidades de dados de maneira sustentável. Ao mesmo tempo, também era importante processar todo o volume obtido ou mesmo desenvolver novas tecnologias para armazenar dados não estruturados.
Para justificar o título desta seção e fornecer ao leitor um contexto formal de definição, o site Wikipedia define Big Data como:
A área do conhecimento que estuda como tratar, analisar e obter informações a partir de conjuntos de dados grandes demais para serem analisados por sistemas tradicionais. O termo big data surgiu em 1997, sendo utilizado para nomear essa quantidade cada vez mais crescente e não estruturada de dados sendo gerados a cada segundo.
E assim, por mais que o termo "Big Data" seja muitas vezes traduzido em seu formato literal como "grandes conjuntos de dados", sua essência é maior e engloba mais elementos. Em muitas literaturas, estudiosos encontraram uma forma de definir o Big Data através dos famosos "V's", explorados em detalhes na próxima seção.

Os famosos "V's" em Big Data
Em muitas literaturas e fontes de consulta, é possível observar o Big Data definido em número distinto com 3, 4, 5, 9 ou até mesmo 12 "V's". Para esclarecer melhor as coisas, os "V's" aqui citados são, literalmente, palavras iniciadas com a letra "V". Esta ideia surgiu justamente para facilitar o entendimento geral do termo em meio a palavras-chave que identificam e descrevem características essenciais dessa era moderna de dados.
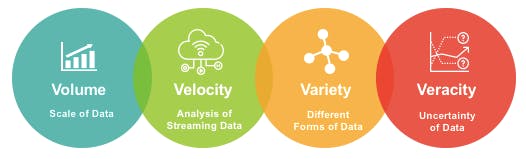
Neste artigo, serão abordados os 4 "V's" que definem o Big Data, sendo eles:
Volume: este pilar indica exatamente a grande quantidade de dados presente no universo do Big Data. Uma empresa de e-commerce, uma instituição financeira, uma montadora de veículos e muitas outras companhias de vários segmentos distintos, de big techs à startups, geram e precisam lidar com grandes quantidades de dados na casa dos petabytes, exabytes, zettabytes ou outra grandeza definida e agrupada aqui ou em um futuro próximo.
Variedade: na mesma linha de raciocínio, uma empresa de comércio online certamente gera dados nos mais variados formatos, sejam vídeos, imagens, arquivos de áudio, textos, planilhas e muito mais. Dessa forma, o mundo do Big Data também é caracterizado por essa pluralidade de dados existentes e tem, em seu pilar de variedade, um forte viés de que os dados não necessariamente estarão presentes sempre em um formato estruturado, mas sim em formatos não estruturados ou semi estruturados.
Velocidade: em uma rede social, um número gigantesco de usuários gera dados a uma taxa incrivelmente alta. Para dar forma a este cenário, basta imaginar todas as interações ocorridas em apenas algumas horas nesta vasta rede de conexões. Além disso, cenários que envolvem a utilização de sensores IoT também são excelentes exemplos de grandes quantidades de dados sendo geradas a uma velocidade incrível.
Veracidade: este pilar indica a confiabilidade dos dados gerados no universo de Big Data. Por maiores que sejam os volumes, por mais plural que sejam os formatos e por mais alta que seja a taxa de geração, se estes dados não forem confiáveis, não há aproveitamento a ser extraído dos mesmos.
Assim, para uma definição genérica de Big Data baseada na ideia dos 4 "V's", os conjuntos de dados, neste cenário, possuem altos volumes (acima de terabytes em um viés relativo), uma alta variedade (formatos estruturado, semi estruturado e não estruturado), uma alta velocidade (clickstream, real time, IoT) e veracidade (confiabilidade).
Alguns fatos sobre Big Data
Conhecida a definição de alguns dos principais pilares que caracterizam dados no universo do Big Data, é possível avançar em alguns exemplos práticos para a consolidação do conhecimento.
No curso Big Data Fundamentos 3.0 disponível na plataforma Data Science Academy, são apresentados alguns fatos interessantes que podem ser utilizados para entender melhor os conceitos até aqui abordados. Ao lado de cada fato, será disposto um dos "V's" definidos.
Volume: "Neste exato momento, 2.5 quintilhões de bytes por dia são gerados para nortear indivíduos, empresas e governos. Esta quantidade está dobrando a cada dois anos."
Velocidade: "Cerca de 90% de todos os dados gerados no planeta foram gerados nos últimos 2 anos."
Variedade: "Aproximadamente 80% dos dados são não-estruturados ou estão em diferentes formatos."
Veracidade: "Toda vez que fazemos uma compra, uma ligação ou interagimos nas redes sociais, estamos produzindo dados."
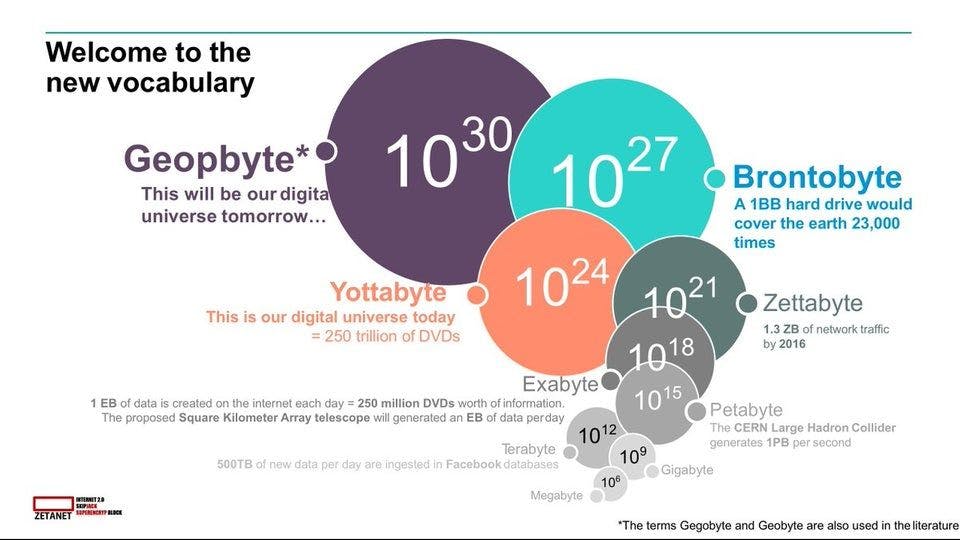
Como curiosidade, o artigo escrito por Edwin Pradeep traz uma relação de grandeza entre escalas de volume de dados. Alguns termos são realmente "esplendorosos" e parecem fugir completamente da realidade atual, como os recém definidos Geopbytes.
| Escala | Valor |
| 1 Bit | Dígito binário |
| 8 Bits | 1 Byte |
| 1024 Bytes | 1 Kilobyte (KB) |
| 1024 Kilobytes | 1 Megabyte (MB) |
| 1024 Megabytes | 1 Gigabyte (GB) |
| 1024 Gigabytes | 1 Terabyte (TB) |
| 1024 Terabytes | 1 Petabytes (PB) |
| 1024 Petabytes | 1 Exabyte (EB) |
| 1024 Exabytes | 1 Zettabyte (ZB) |
| 1024 Zettabyte | 1 Yottabyte (YB) |
| 1024 Yottabytes | 1 Brontobyte (BB) |
| 1024 Brontobytes | 1 Geopbyte |
Os principais desafios do Big Data
Ao apresentar as principais características de grandes conjuntos de dados, é essencial pontuar o quanto o volume presente neste contexto pode impactar significativamente a forma com que o assunto é abordado e gerenciado nas diferentes áreas de tecnologia. Mesmo nos dias atuais, os HDs de computadores possuem volumes na escala de Terabytes. Considerando a tabela apresentada logo ao final da seção anterior, conjuntos de dados na era do Big Data podem alcançar escalas muito maiores do que Terabytes o que, de forma direta, inviabiliza a utilização de HDs ou máquinas individuais para seu armazenamento.
Dessa forma, o primeiro grande desafio da era de Big Data é justamente gerenciar o armazenamento desse gigantesco volume.
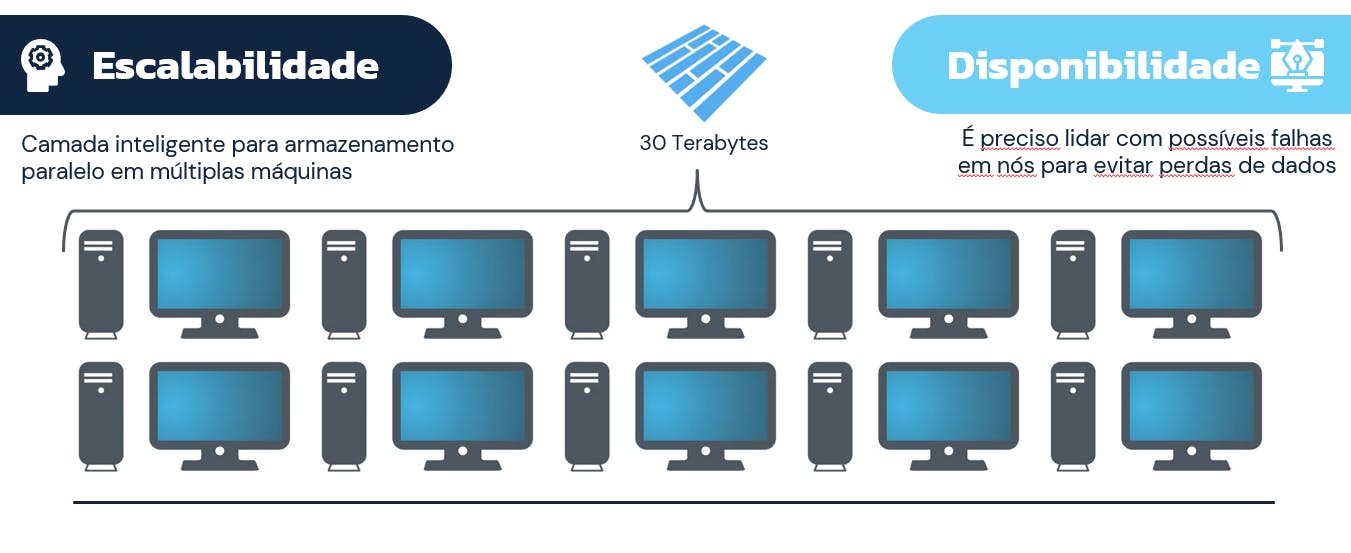
Armazenamento Distribuído
Em linhas gerais, na incapacidade de armazenar os dados em um único HD ou em um único computador, a solução mais intuitiva possível é, de fato, utilizar múltiplos computadores e múltiplos discos rígidos para armazenar grandes volumes de dados.
À este tipo de atuação dá-se o nome de armazenamento paralelo ou distribuído, onde um cluster de computadores atua em conjunto para proporcionar um pool de armazenamento "particionado" de um volume de dados que certamente não seria suportado por uma única máquina.
Ao longo dos anos, uma série de soluções foram desenvolvidas para comportar o alto volume de dados disponíveis, tendo como principal benchmark o HDFS (Hadoop Distributed File System), alvo de um detalhamento conciso em artigos futuros desta série.
Processamento Paralelo
Uma vez armazenados os dados, um outro paradigma se faz presente: o processamento. Ter os dados disponíveis é apenas uma das etapas do fluxo de extração de valor de grandes quantidades de dados pois, sem o devido processamento, não é possível obter insights relevantes ou mesmo tomar decisões estratégicas dentro de um ambiente corporativo.
Assim como no caso anterior, as tecnologias tradicionais utilizadas para processar dados em disco eram insuficientes para gerenciar o alto volume exigido, tornando assim sua utilização inviável. Como referência, os indicadores consolidados na imagem abaixo foram extraídos da excelente especialização Modern big Data Analysis, disponível na plataforma Coursera e trazem, de forma provocativa, o tempo necessário para processar algumas quantidades de dados utilizando tecnologias atuais.

Para superar este obstáculo, tecnologias de processamento distribuído (ou processamento paralelo) se fizeram presentes para garantir que um cluster de computadores pudesse ser utilizado como principal ferramenta de extração de valor dos dados. Certamente, este desafio traz consigo uma complexidade relevante dentro das premissas necessárias para garantir o correto processamento dos dados e, de certa forma, evoluções neste âmbito estão sendo desenvolvidas até os dias atuais.
Como principal referência, o modelo de programação baseado em MapReduce foi uma tecnologia que realmente alterou a forma de gerenciar grandes quantidades de dados. A partir dela, uma série de outras tecnologias puderam ser desenvolvidas e aprimoradas, garantindo avanços altamente expressivos neste universo de dados.
Em que momento falaremos de Hadoop?
Para não sobrepor alguns assuntos que serão abordados em uma maior riqueza de detalhes nesta série, esta última seção do artigo visa apenas propor uma noção geral sobre onde o Hadoop pode ser integrado em todo este contexto de Big Data.
De maneira direta, o Hadoop possui soluções expressamente criadas neste contexto e para este contexto. Em seu funcionamento principal, as soluções HDFS e MapReduce se tornaram referência no armazenamento e processamento de dados distribuídos, respectivamente.
Assim, falar de Big Data é literalmente um anúncio para falar sobre Hadoop. Nesta série, não será diferente: a partir de agora, com o conhecimento teórico adquirido nas principais vertentes que caracterizam o universo de Big Data, será possível mergulhar nos componentes do ecossistema Hadoop que, ao longo do tempo, foi ficando cada vez maior e completo, englobando elementos e tecnologias capazes de atender às mais variadas necessidades de dados.
Considerações Finais
É com grande felicidade que inauguramos mais uma série aqui no blog! Para reforçar os pontos já estabelecidos, abordar assuntos relacionados ao Hadoop é de extrema relevância dentro do conjunto de aprendizado no universo de dados.
Até mesmo soluções recentes com a mais alta tecnologia, como provedores cloud ou empresas dedicadas, possuem ferramentas do Hadoop integradas. A AWS com o EMR (Elastic Map Reduce) e a Cloudera com o CDP (Cloudera Data Platform) são apenas alguns exemplos que podem ser citados.
Portanto, espero sinceramente que esta seja mais uma jornada maravilhosa de aprendizado neste framework maravilhoso conhecido como Hadoop!