




Olá, caro leitor! Seja bem vindo à esta tão aguardada série sobre Apache Spark aqui no blog panini-tech-lab.
Após um longo e importante período de estudos, é chegado o momento de compartilhar com a comunidade os valiosos conhecimentos adquiridos nesta saga afim de difundir, no significado mais profundo da palavra, as vantagens em utilizar o Spark nos mais variados fluxos de dados.
Espero sinceramente que essa seja uma jornada de grandes aprendizados e ótimas trocas. Tenha a certeza de que os artigos aqui escritos foram minuciosamente preparados com a mais pura vontade de ensinar. Embarque nessa e se prepare para aprender Spark de uma vez por todas!
O Apache Spark por quem criou e contribuiu
Neste vasto mundo de tecnologia, coisas novas surgem a todo momento e aprender conteúdos inéditos se torna um desafio invariavelmente complexo. Por outro lado, é possível notar um movimento extremamente importante, com principal origem em tecnologias open source, relacionado ao compartilhamento de conteúdo por parte dos próprios criadores, idealizadores e desenvolvedores das soluções. Por mais simples que isto possa parecer, um cenário onde os fundadores das tecnologias se disponibilizam à descrevê-las e à ensiná-las da maneira mais didática e atenciosa possível é altamente poderoso e enriquecedor!
E quanto ao Spark? Bom, este disclaimer inicial é a porta de entrada para a apresentação das duas principais fontes de aprendizado utilizadas na criação dos artigos desta série:

1) O livro Spark: The Definitive Guide é aquele tipo de fonte de estudos que toda tecnologia merecia ter. Criado e lançado por Bill Chambers e Matei Zaharia (dois dos principais nomes por trás da criação do Spark), o livro trás consigo toda a fundamentação teórica e prática sobre o uso produtivo do Spark em diferentes cenários de Big Data.
2) Já o livro Learning Spark - Lightning-Fast Data Analytics, assinado por Jules S. Damji, Brooke Wenig, Tathagata Das e Denny Lee, é uma versão maravilhosamente renovada e atualizada com as mais recentes features do Spark 3.0. Literalmente, uma obra prima.

E assim, por mais que seja possível encontrar diversos artigos, vídeos, cursos, tutoriais e até mesmo páginas de blogs como este, não há nada mais justo do que definir o Apache Spark com as mesmas palavras utilizadas pelos criadores e desenvolvedores diretamente responsáveis pelo seu sucesso:
"O Apache Spark pode ser definido como uma ferramenta computacional unificada que contém um conjunto de bibliotecas para processamento paralelo de dados em clusters de computadores.
Sendo uma ferramenta computacional unificada, o Spark traz consigo uma série de APIs e bibliotecas que podem ser utilizadas para os mais variados propósitos: SQL e dados estruturados (Spark SQL), machine learning (MLlib), streaming de dados (Spark Streaming), análise de grafos (GraphX), entre outros."
Autores do livro Spark: The Definitive Guide
"O Apache Spark é uma ferramenta unificada para processamento de grandes quantidades de dados de maneira distribuída, proporcionado armazenamento em memória para passos computacionais intermediários e tornando-o mais veloz do que sistemas como o MapReduce.
Além disso, incorpora uma série de bibliotecas com poderosas APIs para machine learning (MLlib), SQL para queries interativas (Spark SQL), processamento de streaming de dados (Structured Streaming) e processamento de grafos (GraphX)."
Autores do livro Learning Spark
Nesse momento, é provável que termos técnicos tenham sido apresentados de maneira inédita e isso é completamente normal. Antes de mergulhar em explicações mais detalhadas sobre algumas palavras chave utilizadas para definir o Spark (como processamento paralelo e armazenamento em memória), é importante trazer à tona uma visão histórica de seu surgimento. Afinal, ter conhecimento sobre os problemas e os desafios existentes no contexto de surgimento do Spark é um excelente caminho para um entendimento geral sobre suas capacidades.
Um pouco de história
O projeto de pesquisa do Apache Spark começou na UC Berkeley em 2009 e originou o primeiro paper intitulado Spark: Cluster Computing with Working Sets. Entretanto, antes disso, o universo de Big Data passou por uma série de desafios até que soluções plausíveis fossem implementadas para resolver problemas envolvendo armazenamento e processamento distribuído.
O armazenamento e o processamento de dados
Em grande parte da história, a capacidade de processamento de computadores pôde ser considerada uma grandeza com um aumento linear constante. Em outras palavras, ano após ano, computadores eram capazes de executar um número maior de instruções por segundo, se tornando assim mais velozes. Como consequência, aplicações construídas nestes computadores se aproveitaram diretamente desta tendência e, de maneira análoga, eram capazes de processar maiores volumes de dados sem alterações em sua lógica.
Entretanto, esta tendência teve seu fim decretado em 2005: por conta de limitações físicas no processo de dissipação de calor, o mundo tecnológico não mais disponibilizava de processadores únicos mais velozes a cada ano, mas sim de arquiteturas que contemplavam múltiplas unidades de processamento trabalhando em paralelo a uma mesma velocidade. Esta mudança teve um impacto substancial no modo como os dados eram processados e, assim sendo, aplicações que antes puderam se aproveitar dos avanços na era do single core agora precisavam passar por modificações para se adequarem ao novo mundo do processamento paralelo.
Obstante às dificuldades encontradas no ramo de processamento de dados, o ritmo de avanço em tecnologias de armazenamento de dados não diminuiu em 2005. Cada vez mais, armazenar dados se tornava algo mais barato para organizações de todos os tamanhos e, em certo momento, decidir não armazenar logs de aplicações poderia até ser considerado algo negligente em uma companhia.
Provavelmente o efeito mais prático deste cenário pode ser exemplificado por câmeras de smart phones que, a cada novo lançamento, continuam a entregar maiores resoluções a um custo por pixel relativamente estável e mais barato em comparação ao passado. Considerando que câmeras são objetos de coleta de dados também utilizados em vários outros ramos da ciência e tecnologia, como astronomia (telescópios) e biologia (máquinas de sequenciamento de genes), a diminuição dos custos se aplicam igualmente à estas áreas.
Dessa forma, o resultado final é um mundo onde coletar grandes quantidades de dados pode ser considerada uma tarefa de baixo custo, mas processá-los é algo que requer grandes sistemas de computação paralela normalmente criados com auxílio de clusters de computadores com múltiplas máquinas. Este é o mundo onde tecnologias como o Spark abrem as cortinas do palco.
Big Data e o processamento paralelo no Google
Muito do que se conhece hoje em Big Data teve início no Google e no esforço emplacado para implementar uma solução viável em sua famosa ferramenta de pesquisa, o Google Search. A necessidade de retornar resultados rápidos em um vasto conjunto de documentos instigou a criação de ferramentas como Google File System (GFS), MapReduce (MR) e Big Table. Grande parte deste trabalho gerado pelo Google foi proprietário e restrito à própria empresa, porém as ideias inovadoras por trás destes sistemas foram extremamente relevantes para a comunidade open source, especialmente no Yahoo!
Hadoop no Yahoo!
Os desafios computacionais expressados no sistema Google File System (GFS) foram inspirações para a criação do Hadoop Distributed File System (HDFS), incluindo a implementação do MapReduce como framework para computação distribuída. Em 2006, o framework Hadoop foi doado à Apache Software Foundation (ASF) e, a partir deste ponto, o Apache Hadoop, composto pelos elementos Hadoop Common, HDFS, MapReduce e YARN, ganhou o mundo! Comunidades open source e até mesmo empresas proprietárias (Cloudera e Hortonworks) adotaram o Hadoop como principal framework de Big Data. Entretanto, a jornada de uso do MapReduce indicava à comunidade alguns “problemas” que precisavam ser endereçados à medida que a evolução das necessidades se fazia presente.
Limitações do MapReduce
Por mais significativo que tenha sido o surgimento de um modelo de programação capaz de processar Big Data de forma paralela como o MapReduce, os avanços tecnológicos e o aumento da complexidade de fluxos se mostraram como grandes desafios ao modelo amplamente utilizado na comunidade. Na época, as principais limitações encontradas no MapReduce giravam em torno de:
1) Lentidão em fluxos com múltiplos jobs de MapReduce devido ao alto tráfego I/O em disco
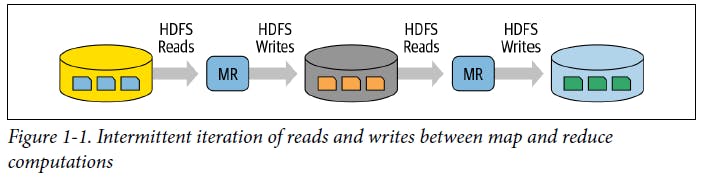
Na figura acima, é ilustrado um exemplo de job de MapReduce com múltiplas fases de mapeamento e redução em um cenário típico encontrado em fluxos complexos de transformação de dados. A criticidade neste ponto está intimamente relacionada à necessidade de escrita dos dados em disco a cada finalização de tarefa com sua subsequente leitura no início da tarefa seguinte, aumentando substancialmente o tráfego de entrada e saída do disco e impactando negativamente no tempo de processamento dos dados.
2) Complexidade na integração de novos workloads, como Machine Learning, streaming e SQL
De fato, o Hadoop em sua essência não contava com soluções específicas para todas as áreas de dados e, para endereçar este ponto, engenheiros desenvolveram sistemas sob medida, como Apache Hive, Apache Storm, Apache Impala, Apache Drill, Apache Mahout, entre outros. Cada um deles possuía sua própria API e sua própria configuração de cluster, impactando em um aumento da complexidade do ecossistema Hadoop dentro da curva de aprendizado de desenvolvedores.
Neste momento, a principal questão que se fez presente na comunidade foi: “Existe uma forma de tornar o Hadoop e MapReduce mais simples e mais rápido?” Neste contexto, voltamos ao primeiro paper do Spark publicado em 2009 e referenciado no início desta seção.
O surgimento do Spark
E assim, quando o time de pesquisadores no AMPlab realmente coletou e analisou as principais dores reportadas por grandes usuários de Hadoop e MapReduce, estava estruturada a ideia de construção de uma ferramenta capaz de atuar em grande parte dos pontos estratégicos levantados, visando não apenas aprimorar a experiência de uso, mas também garantir uma melhor performance, interatividade e facilidade: nascia então o Spark.
Entre os principais pontos de vantagem do Spark, é possível citar:
- Alto nível de tolerância à falhas
- Armazenamento e compartilhamento de dados em memória de resultados intermediários entre passos computacionais
- Disponibilidade de APIs em múltiplas linguagens de forma unificada.
Mesmo no início dos estudos, artigos e análises reportaram que o Apache Spark poderia ser uma solução de processamento paralelo alternativa ao MapReduce com um ganho entre 10 a 20 vezes em termos de velocidade! Hoje em dia, o ganho de velocidade é de muitas ordens de magnitude.
Em 2013, o Spark expandiu sua base de usuários e alguns de seus criadores originais doaram o projeto para a Apache Software Foundation e formaram uma companhia chamada Databricks. Nos anos subsequentes, novas versões do Spark emergiram e sua adoção aumentou cada vez mais entre engenheiros de dados, cientistas de dados, analistas de dados ou mesmo entre entusiastas que, de alguma forma, precisam solucionar problemas atrelados ao processamento de grandes quantidades de dados.
Fato é que, desde seu primeiro lançamento, o Spark tem evoluído constantemente em busca de se tornar uma ferramenta unificada com um escopo que abrange a grande maioria das necessidades analíticas de fluxos de trabalho. Mesmo sabendo que este próximo indicador fatalmente estará defasado em poucas semanas, a página oficial do Spark no GitHub conta com quase 4 mil colaboradores e pouco mais de 33 mil commits já realizados. Números totalmente incríveis e que seguem crescendo conforme a adoção da comunidade à esta poderosa ferramenta.
Os pilares do Spark
Após uma curiosa e necessária jornada histórica no surgimento do Spark e nos principais desafios atrelados à sua existência, é possível mergulhar em um nível maior de detalhes sobre sua filosofia segundo os próprios criadores. Em linhas gerais, é possível estabelecer que as funcionalidades do Spark estão dividas em 4 principais pilares:
Pilar 1: Velocidade
- O Spark consegue se aproveitar dos recentes avanços de performance de CPUs e memória
- As computações são feitas como uma DAG de instruções (Directed Acyclic Graph), permitindo a construção de eficientes grafos computacionais
- Com os resultados intermediários dos fluxos mantidos em memórias ao invés de escritos em disco, há uma redução de entradas e saídas (I/O) e um impacto diretamente positivo na performance
Pilar 2: Facilidade de uso
- Abstração da complexidade através de APIs de alto nível (DataFrames e Datasets)
- Transformações, ações e operações são fornecidas em um modelo simples de programação
- Possibilidade de construção de fluxos em linguagens familiares (Python, Scala, R, Java)
Pilar 3: Modularidade
- Bibliotecas unificadas em linguagens familiares
- APIs bem documentadas
- Possibilidade de criar workloads usando SparkSQL, Spark Streaming, Spark MLlib e GraphX em uma única engine computacional
Pilar 4: Extensibilidade
- Foco em processamento e não no armazenamento
- Possibilidade de operar com uma infinidade de fontes e formatos de dados
- Objetos
DataFrameReadereDataFrameWritercom vasta aplicabilidade
Conclusão e encerramento
Aprender sobre o Apache Spark é, sem dúvidas, uma jornada extremamente recompensadora para qualquer um imerso no universo de Big Data e que, de certa forma, necessita analisar ou transformar dados dentro dos mais variados cenários. Como visto nos tópicos acima, o Spark proporciona uma série de vantagens à seus usuários e, não à toa, é uma das ferramentas mais utilizadas no ramo.
Ao longo desta série, serão apresentados conceitos teóricos e uma enxurrada de exemplos práticos focados em situações reais de trabalho com as principais APIs estruturadas do Spark.
Foi ótimo ter você aqui, caro leitor! Até a próxima!