




Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark!
Em qualquer ambiente ou ferramenta, trabalhar com tipos primitivos complexos pode ser considerada uma tarefa desafiadora. À primeira vista, ao deparar-se com elementos e atributos alheios ao padrão clássico de tipagem comumente encontrado em fluxos de trabalho, os usuários e entusiastas do mundo de dados podem absorver e adotar uma falsa impressão de que os tipos complexos são, de fato, complexos. Para fornecer uma visão alternativa à este injusto cenário, a proposta deste artigo é esclarecer, desvendar, desmistificar, elucidar e, por que não, dignificar o uso de tipos primitivos complexos para as mais variadas aplicações envolvendo pipelines de transformação de dados com foco no Apache Spark.
Tipos primitivos no Spark
Sob a ótica de processamento de dados em pyspark, os tipos primitivos podem ser associados à classes presentes no módulo pyspark.sql.types capazes de serem importadas em qualquer script ou fluxo de trabalho. Contendo uma série de implementações próprias, tais classes permitem aos usuários usufruir de funcionalidades verdadeiramente eficientes em diferentes situações envolvendo a tipagem de dados, como a utilização de funções e métodos específicos e, principalmente, na definição de schemas para a leitura e obtenção de DataFrames.
Dessa forma, assim como uma linguagem de programação (como o Python) possui seus tipos primitivos básicos representados por inteiros (int), strings (string), booleanos (bool), ponto flutuante (float), entre outros, o Spark também traz consigo classes equivalentes para os propósitos de uso estabelecidos. De maneira análoga, estruturas específicas presentes em tais linguagens, como listas (list) e dicionários (dict), indubitavelmente terão suas respectivas classes em Spark retratadas, em essência, pelo que é conhecido como tipos primitivos complexos.
Classes para tipos primitivos básicos
E assim, na dinâmica comum de armazenamento e processamento de dados, os tipos inteiros, strings, booleanos, doubles, dates e afins formam o pacote de tipos primitivos básicos disponível nas mais variadas ferramentas e linguagens de programação. Em referência ao uso do Spark para englobar tarefas de transformação envolvendo tais tipos, a tabela abaixo apresenta as classes do módulo pyspark.sql.types habilitadas para uso:
| Tipo Primitivo | Equivalente no Python | Instância |
| ByteType | int | DataTypes.ByteType |
| ShortType | int | DataTypes.ShortType |
| IntegerType | int | DataTypes.IntegerType |
| LongType | int | DataTypes.LongType |
| FloatType | float | DataTypes.FloatType |
| DoubleType | float | DataTypes.DoubleType |
| StringType | str | DataTypes.StringType |
| BooleanType | bool | DataTypes.BooleanType |
| DecimalType | decimal.Decimal | DecimalType |
Classes para tipos primitivos complexos
Do outro lado do espectro, é possível encontrar, nas mais variadas jornadas de transformação de dados, estruturas complexas, aninhadas e que se apresentam como estruturas utilizadas em cenários específicos de armazenamento e processamento onde os tipos primitivos básicos não são aplicáveis. Para casos assim, os tipos primitivos complexos se fazem presentes dentro das mais diferentes classes:
| Tipo Primitivo | Equivalente no Python | Instância |
| BinaryType | bytearray | BinaryType() |
| TimestampType | datetime.datetime | TimestampType() |
| DateType | datetime.date | DateType() |
| ArrayType | list, tuple ou array | ArrayType(dataType, [nullable]) |
| MapType | dict | MapType(keyType, valueType, [nullable]) |
| StructType | Lista de tuplas | StructType([fields]) |
| StructField | Correspondente ao tipo do campo | StructField(name, dataType, [nullable]) |
Com esta breve introdução, é chegado o momento de explorar, na prática, a utilização dos tipos primitivos complexos no Spark, suas respectivas funções e aplicações em cenários reais de trabalho.
Preparando o ambiente
Como forma de proporcionar exemplos reais envolvendo o uso de tipos primitivos complexos no Spark, uma nova sessão será criada no ambiente de trabalho que envolve a utilização do pyspark em um Jupyter Notebook instanciado em uma máquina virtual Linux:
# Importando bibliotecas
from pyspark.sql import SparkSession
# Criando objeto de sessão
spark = SparkSession\
.builder\
.appName("tipos-primitivos-complexos")\
.master("local[1]")\
.getOrCreate()
Com isso, todos os métodos relacionados à API estruturada (DataFrames) poderão ser aplicados a partir do objeto de sessão armazenado na variável spark.
Criando DataFrames com tipos complexos
Diferente dos processos já conhecidos de leitura de fontes externas em Spark, a proposta prática deste artigo gira em torno da criação manual de um DataFrame através da definição explícita de um schema contendo tipos complexos unida à estruturação de elementos de dados a comporem tal coleção distribuída.
Para assegurar um entendimento claro sobre os passos subsequentes, a tabela abaixo serve para apresentar os metadados do conjunto de dados a ser manualmente criado e posteriormente transformado em um objeto do tipo DataFrame no Spark:
| Atributo | Descrição |
| time | Nome do time de futebol alvo da análise |
| qtd_titulos_br | Quantidade de títulos conquistados no Campeonato Brasileiro da série A |
| anos_titulos_br | Lista contendo todos os anos onde o dado time conquistou um Campeonato Brasileiro |
| estadio | Dicionário contendo informações características do estádio do respectivo time, incluindo informações como nome, região e linha do metrô mais próxima |
Clarificada a missão, é possível iniciar a construção manual deste DataFrame a partir da importação dos tipos primitivos complexos a serem utilizados:
# Importando tipos primitivos
from pyspark.sql.types import StructType, StructField,\
IntegerType, StringType, ArrayType, MapType
Diferente dos tipos básicos já trabalhados previamente, a novidade do bloco acima se dá por conta da presença das classes ArrayType e MapType. Considerando a concepção da ideia envolvendo a criação do conjunto de dados, é esperado que ambos os tipos sejam utilizados para a definição dos atributos anos_titulos_br (lista de inteiros) e estadio (conjunto de múltiplas chaves e valores). Para uma definição em código, nada mais direto do que a própria criação do schema destes dados.
# Definindo schema
schema = StructType([
StructField("time", StringType(), nullable=False),
StructField("qtd_titulos_br", IntegerType(), nullable=True),
StructField("anos_titulos_br", ArrayType(IntegerType()), nullable=True),
StructField("estadio", MapType(StringType(), StringType()), nullable=True)
])
E assim, com o layout do conjunto previamente definido, é possível definir os elementos de composição do DataFrame em um formato aninhado de listas no Python respeitando a ordem de definição codificada:
# Criando dados manualmente (python)
data_times_br = [
["Corinthians", 7, [1990, 1998, 1999, 2005, 2011, 2015, 2017], {"nome": "Neo Quimica Arena", "regiao": "Itaquera", "linha_metro": "Vermelha"}],
["Palmeiras", 10, [1960, 1967, 1967, 1969, 1972, 1973, 1993, 1994, 2016, 2018], {"nome": "Allianz Park", "regiao": "Barra Funda", "linha_metro": "Vermelha"}],
["São Paulo", 6, [1977, 1986, 1991, 2006, 2007, 2008], {"nome": "Morumbi", "regiao": "Morumbi", "linha_metro": "Amarela"}],
["Santos", 8, [1961, 1962, 1963, 1964, 1965, 1968, 2002, 2004], {"nome": "Vila Belmiro", "regiao": "Baixada Santista"}]
]
Por fim, para a criação de um objeto do tipo DataFrame em Spark, basta executar o método createDataFrame() do objeto de sessão spark passando, como argumentos, a estrutura data_times_br e o schema previamente codificado:
# Transformando dados em DataFrame
df_times_br = spark.createDataFrame(data_times_br, schema)
# Visualizando dados
df_times_br.printSchema()
df_times_br.show(truncate=True)
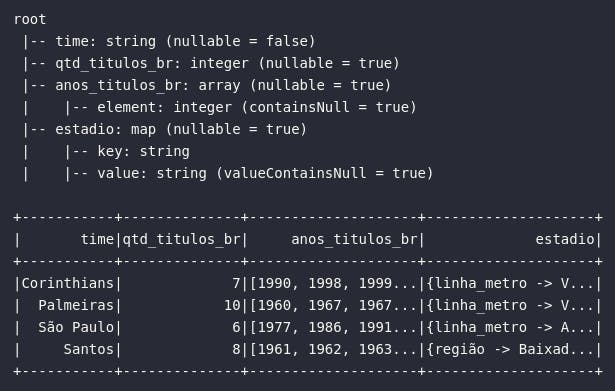
Operações em tipos primitivos complexos
Uma vez preparado o ambiente de exploração, é possível navegar sobre funções, métodos e nuances específicas envolvendo os tipos primitivos complexos em Spark utilizando, como alvo, o DataFrame manualmente criado e armazenado sob a variável df_times_br contendo dados pontuais de alguns times de futebol do estado de São Paulo.
Selecionando tipos primitivos complexos
Para aprender a transformar, é importante saber como selecionar um atributo complexo em uma coleção distribuída em Spark. Arrays são como listas e, dessa forma, podem ser indexados para retornar os elementos desejados. No exemplo de código abaixo, uma consulta é realizada para retornar o primeiro e o segundo ano de conquista de títulos do Campeonato Brasileiro:
# Importando funções
from pyspark.sql.functions import col, expr
# Visualizando primeiro e segundo título brasileiro
df_titulos_br = df_times_br.select(
expr("time"),
col("anos_titulos_br")[0].alias("ano_primeiro_titulo"),
expr("anos_titulos_br[1] AS ano_segundo_titulo")
)
# Visualizando dados
df_titulos_br.show()
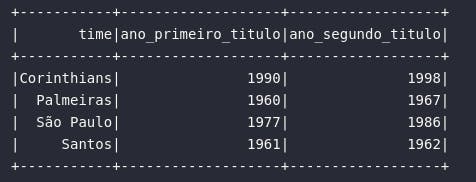
No caso do tipo Map, os dados estão dispostos como conjuntos de chave e valor em um âmbito análogo ao de dicionários em Python. Para acessar um elemento específico dentro desta estrutura, é preciso aplicar uma sintaxe semelhante ao acesso de atributos de uma classe. De modo a proporcionar um exemplo prático, o bloco de código abaixo extrai algumas informações dos estádios dos times disponíveis na base:
# Visualizando detalhes dos estádios dos times
df_estadios = df_times_br.select(
col("time"),
col("estadio").nome,
col("estadio").regiao.alias("regiao_estadio"),
expr("estadio.linha_metro AS metro_prox_estadio")
)
# Visualizando dados
df_estadios.show()
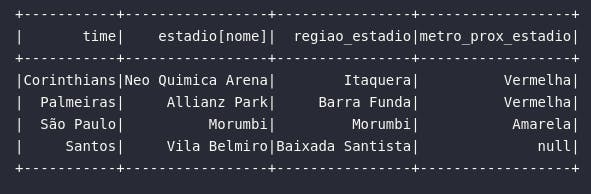
Propositalmente, o bloco acima foi construído com base em diferentes abordagens de seleção e referenciamento de colunas, proporcionando assim uma visão clara de que existem diferentes formas de criar expressões para selecionar atributos do tipo Map. Além disso, analisando as informações do estádio do Santos (última linha do conjunto de retorno), é possível perceber que, na base original, não há informações de metrô próximo, fazendo assim com que o Spark retorne um valor nulo para esta tentativa de acesso de atributo.
Em cenários específicos, algumas funções auxiliares podem ser utilizadas para proporcionar uma maior gama de possibilidades em frente a tipos primitivos complexos em uma coleção distribuída de dados em Spark. Na sequência, algumas destas funções serão apresentadas e exemplificadas utilizando os tipos ArrayType e MapType disponíveis no DataFrame criado.
element_at()
A primeira função abordada é a element_at que, por sua vez, permite retornar um elemento de um array com base em um índice. Sua aplicação é praticamente análoga ao processo de indexação e seleção de arrays mostrado anteriormente com algumas particularidades interessantes: com element_at, é possível selecionar a última posição de um array com base no índice -1. No exemplo abaixo, uma análise sobre os títulos brasileiros dos times será fornecida ao usuário com base em uma consulta.
# Importando função
from pyspark.sql.functions import element_at
# Visualizando primeiro e último título brasileiro
df_titulos_br = df_times_br.select(
col("time"),
element_at(col("anos_titulos_br"), 1).alias("ano_primeiro_titulo"),
element_at(col("anos_titulos_br"), -1).alias("ano_ultimo_titulo"),
expr("year(current_date()) - element_at(anos_titulos_br, -1) AS anos_sem_titulos")
)
# Visualizando dados
df_titulos_br.show()
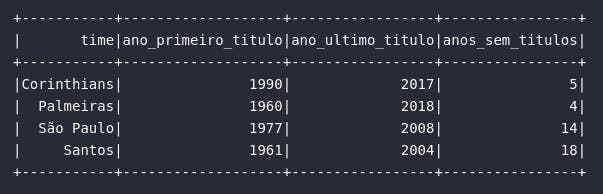
slice()
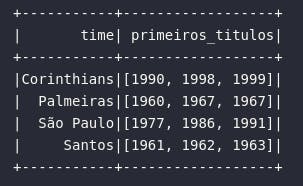
Para "fatiar" um array, a função slice() pode ser aplicada. Neste contexto, o retorno da função é dado por um elemento do tipo Array que, posteriormente, pode ser trabalhado e analisado das mais variadas formas. No exemplo de código abaixo, a função slice() é aplicada para retornar os primeiros 3 títulos brasileiros de cada time:
# Importando função
from pyspark.sql.functions import slice
# Selecionando primeiros títulos
df_prim_titulos = df_times_br.select(
col("time"),
slice(col("anos_titulos_br"), 1, 3).alias("primeiros_titulos"),
)
# Visualizando dados
df_prim_titulos.show()
size()
Para retornar o "tamanho" de um atributo do tipo array, a função size() pode ser utilizada. Neste momento, é válido citar que a aplicação da função size() pode ser unida à diversas outras análises, como a indexação, por exemplo. No exemplo abaixo, será proposta uma consulta para analisar a quantidade total de títulos brasileiros de cada time vinculada ao retorno do último título brasileiro conquistado.
# Importando função
from pyspark.sql.functions import size
# Aplicando consulta sobre títulos br
df_titulos = df_times_br.select(
col("time"),
col("qtd_titulos_br"),
size(col("anos_titulos_br")).alias("qtd_titulos_br_size"),
col("anos_titulos_br")[size(col("anos_titulos_br")) - 1].alias("ano_ultimo_titulo"),
expr("size(estadio) AS qtd_infos_estadio")
)
# Visualizando dados
df_titulos.show()
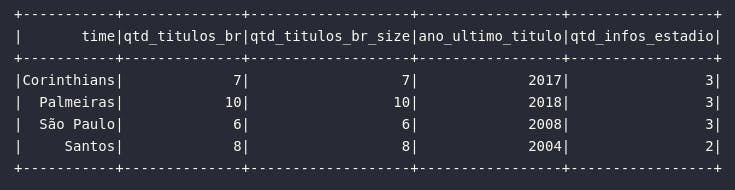
Como elemento adicional, a função size() também pode ser aplicada à atributos do tipo Map, retornando assim a quantidade de conjuntos de chave e valor. No exemplo acima, é possível perceber que, no atributo estadio, o time Santos possui apenas 2 informações registradas (nome e região), diferente dos demais times onde estão presentes 3 conjuntos de chave e valor (nome, região e linha do metrô).
array_contains()
Para verificar se um atributo do tipo array em Spark possui um determinado elemento em sua composição, a função array_contains() se faz presente. No exemplo de código abaixo, uma consulta é aplicada aos dados de times de futebol para verificar qual deles possui títulos nos anos de 2015 e 2018:
# Importando função
from pyspark.sql.functions import array_contains
# Analisando títulos em ano específico
df_campeoes = df_times_br.select(
col("time"),
array_contains(col("anos_titulos_br"), 2015).alias("campeao_2015"),
expr("array_contains(anos_titulos_br, 2018) AS campeao_2018")
)
# Visualizando dados
df_campeoes.show()
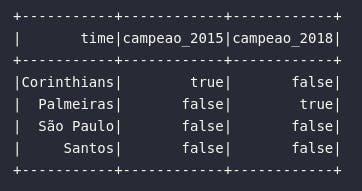
Analisando o retorno da consulta acima, é possível avaliar que o Corinthians foi campeão em 2015 e que o Palmeiras conquistou o título de 2018.
explode()
A função explode() é, provavelmente, uma das mais desafiadoras funções aplicadas a tipos primitivos complexos. Sua vasta aplicabilidade nos mais variados cenários de transformações permite extrair diferentes conjuntos de dados para diferentes propósitos. Em linhas gerais, "explodir" um tipo primitivo complexo significa transfomá-lo em um conjunto de dados não aninhado. Em outras palavras, o processo de explosão permite analisar o conteúdo de tipos primitivos complexos de uma forma verticalizada em um DataFrame resultante.
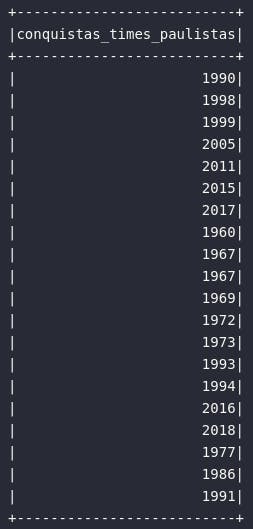
Para validar este conceito na prática, o exemplo abaixo comporta a aplicação do método explode() no atributo anos_titulos_br para analisar, de maneira vertical, todos os elementos de composição de todos os arrays deste atributo:
# Importando função
from pyspark.sql.functions import explode
# Analisando todos os anos de títulos dos times paulistas
df_conquistas_sp = df_times_br.select(
explode(col("anos_titulos_br")).alias("conquistas_times_paulistas")
)
# Visualizando resultados
df_conquistas_sp.show()
Da mesma forma, a função explode() pode ser aplicada a elementos do tipo Map, transformando assim seu conteúdo em um novo DataFrame composto pelas colunas key e value contendo, respectivamente, as informações de cada chave e de cada valor presente em cada um dos Maps alvo da "explosão":
# Analisando informações de estádios
df_info_estadios = df_times_br.select(
col("time"),
expr("explode(estadio)")
)
# Visualizando dados
df_info_estadios.show()

split()
Do outro lado do espectro, a função split() pode ser aplicada para "separar" um atributo simples (como uma cadeia de caracteres, por exemplo) em um tipo complexo representado por um Array. No bloco de código abaixo, de forma totalmente ilustrativa, a função split() é aplicada ao atributo que armazena os nomes do times para uma separação desta cadeia de caracteres com base no espaço (" ").
# Importando função
from pyspark.sql.functions import split
# Separando nomes de times
df_times = df_times_br.select(
split(col("time"), " ")
)
# Visualizando dados
df_times.show()
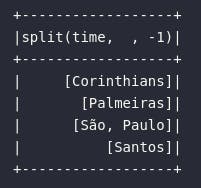
Analisando o resultado, percebe-se que, mesmo que algumas entradas para a coluna de times não possuam o caractere separador, o retorno fornecido é um objeto do tipo array contendo um único elemento. Para os casos onde o caractere separador existe (São Paulo, por exemplo), o retorno é dado por um array de múltiplos elementos. Em um exemplo relativamente mais complexo, os processos de "explosão" e "separação" são combinados para analisar o primeiro termo que nomeia os estádios dos times:
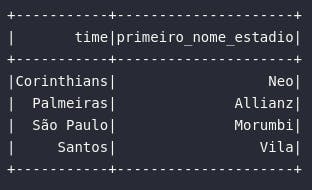
# Analisando primeiro termo que nomeia os estadios
df_estadio_nome = df_times_br.selectExpr(
"time",
"explode(estadio) AS (chave, valor)"
).where(expr("chave = 'nome'")).selectExpr(
"time",
"element_at(split(valor, ' '), 1) AS primeiro_nome_estadio"
)
# Visualizando dados
df_estadio_nome.show()
create_map()
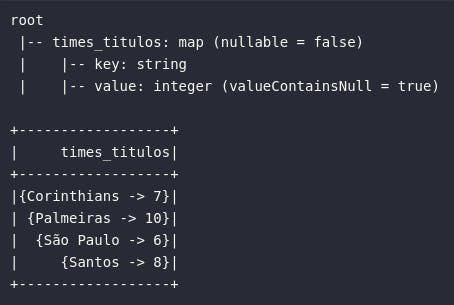
Existem, ainda, algumas funções específicas no pool do Spark que auxiliam na construção de tipos primitivos complexos com base em múltiplos atributos básicos de um DataFrame. Neste cenário, a função create_map() pode ser aplicada para combinar múltiplas colunas para a consolidação de um atributo complexo único. No exemplo abaixo, as informações de times e de quantidade de títulos são unidas em um único campo:
# Importando função
from pyspark.sql.functions import create_map
# Gerando mappings
df_complex_map = df_times_br.select(
create_map(col("time"), col("qtd_titulos_br")).alias("times_titulos")
)
# Visualizando dados
df_complex_map.printSchema()
df_complex_map.show()
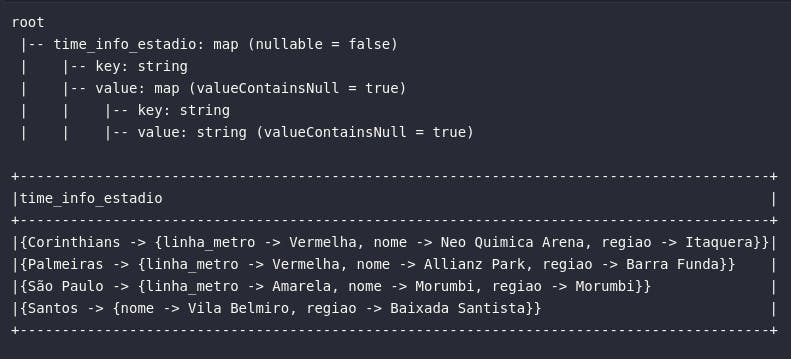
Adicionalmente, é importante citar que um tipo primitivo Map pode ser composto, em seus valores, por outros atributos do tipo Map em uma dinâmica de "maps dentro de maps". Para proporcionar um exemplo prático de algo nesse sentido, o código abaixo une as informações de time com as informações de estádio de cada time:
# Criando map aninhado
df_times_estadio = df_times_br.select(
create_map(col("time"), col("estadio")).alias("time_info_estadio")
)
# Visualizando dados
df_times_estadio.show(truncate=False)
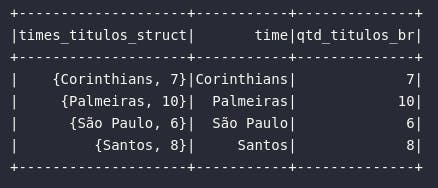
Ainda sobre a construção de tipos primitivos complexos, a geração de atributos do tipo StructType pode ser realizada pela simples colocação de dois ou mais atributos em uma tupla no ato da consulta:
# Gerando dados do tipo struct
df_times_br.selectExpr(
"(time, qtd_titulos_br) AS times_titulos_struct",
"(time, qtd_titulos_br).time AS time",
"(time, qtd_titulos_br).qtd_titulos_br AS qtd_titulos_br"
).show()
Conclusão e encerramento
Considerando a jornada de exploração de funções de transformação aplicadas à tipos primitivos complexos, é possível notar que este é um mundo com uma vasta gama de possibilidades analíticas. Em muitas ocasiões, modificar os dados de modo a encaixá-los em um cenário específico dentro de estruturas aninhadas pode ser a resposta ideal para solucionar problemas complexos. Nessa linha, entender as nuances e, literalmente, perder o medo em se trabalhar com esse tipo de estrutura pode, sem dúvidas, habilitar conhecimentos antes não explorados e de grande valiosidade.
No universo de Big Data, é comum encontrar conjuntos de dados armazenados de maneira desnormalizada, aumentando assim a eficiência de consultas através da redução de possíveis operações de joins normalmente encontradas em ambientes normalizados. Em ocasiões do tipo, os tipos primitivos complexos podem ser uma saída altamente satisfatória para compor tais bases.
Espero que este artigo tenha sido de grande valia para você, caro leitor. Até a próxima!