


Uma Proposta de Padronização de Aplicações Spark
Aprimorando a forma como desenvolvemos, testamos e mantemos aplicações Spark


Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre Apache Spark.
Após um longo período de hiato, retorno a escrita nesta série com um assunto extremamente relevante para todos que, de certa forma, desenvolvem aplicações Spark para as mais variadas finalidades dentro dos mais variados ambientes. Você costuma escrever códigos em pyspark para execução em um ambiente local? Executa jobs Glue na AWS? Utiliza o EMR para processos de ETL? Se você sequer pensou em responder positivamente para uma dessas perguntas, então certamente este artigo é para você!
Introdução
Dores e Motivações
Em essência, após participar de uma quantidade relativamente grande de iniciativas envolvendo a implantação de aplicações Spark em ambientes de produção (mais especificamente como jobs do Glue na AWS), notei que algumas das principais dores dos usuários giravam em torno dos seguintes tópicos:
- 🤯 Dificuldade em organizar códigos com múltiplas etapas de transformação
Imagine uma aplicação Spark com milhares de linhas de código escritas em um único arquivo main.py. Agora imagine a dificuldade de novos usuários em sustentar ou desenvolver novas features para o job em questão. Complexo, não?
- ❌ Dificuldade em executar testes unitários localmente
O terror dos testes unitários sempre esteve presente em grande parte dos desenvolvedores de aplicações Spark, principalmente se estas utilizam bibliotecas terceiras existentes apenas em ambientes específicos (como as bibliotecas awsglue, por exemplo). A falta de organização e estruturação do código trazia ainda mais complexidade para esta que nunca foi uma tarefa simples para Engenheiros de Dados e Analytics. Além disso, mesmo que alguns casos de testes pudessem ser desenvolvidos diante de todos os desafios dispostos, a cobertura alcançada nunca era suficientemente alta para um threshold mínimo a ser considerado.
Pois bem, diante do cenário caótico acima exemplificado e, após uma extensa jornada de estudos, experimentações e validações práticas, decidi consolidar todo o aprendizado adquirido no processo e materializá-lo neste artigo. O grande objetivo será fornecer uma proposta eficiente sobre como desenvolver, estruturar e organizar uma aplicação Spark para aprimorar a manutenção, facilitar a criação de testes unitários e aumentar a velocidade no desenvolvimento de novas features.
Não, isso não é uma promessa de político (ou pelo menos espero que não o seja). De toda forma, antes de começarmos a mergulhar nessa saga, é preciso apresentar o cenário idealizado para que todos possamos seguir as etapas dessa proposta em todos os seus minuciosos detalhes.
O Cenário Proposto
Para trazer uma visão extremamente prática à esta importante missão, nada mais honesto do que fazer toda a construção da proposta com base em um cenário prático de trabalho.
Assim, para que toda a idealização da nossa futura aplicação Spark possa ser, de fato, materializada na prática, vamos estabelecer o alcance da seguinte meta:
🚨 "Criar e catalogar uma tabela preparada contendo transformações básicas aplicadas em duas tabelas de origem. O ambiente utilizado será o AWS Glue."
A meta estebelcida é apenas uma forma genérica de indicar que a ideia é, de fato, construir um processo de ETL utilizando Spark. Como ambiente alvo, a escolha do Glue se dá pelo fato do mesmo possuir algumas especificidades em torno das bibliotecas necessárias para utilizá-lo, trazendo ainda mais ganho para a proposta de padronização a ser consolidada.
Dessa maneira, além de estabelecermos uma meta bem definida, precisamos também garantir um maior detalhamento sobre os dados de origem utilizados nessa jornada. Para esta tarefa, serão utilizados dois datasets públicos do conjunto Brazilian E-Commerce disponível na plataforma Kaggle:
olist_orders_dataset: conjunto de dados contendo informações sobre pedidos realizados online
olist_order_items_dataset: conjunto de dados contendo informações sobre os itens e produtos em cada um dos pedidos realizados online
Considerando os metadados de cada um dos conjuntos, temos:
Metadados do conjunto olist_orders_dataset:
| Atributo | Descrição |
| order_id | Identificador único de um pedido realizado de maneira online |
| customer_id | Identificador único do cliente realizador do pedido online |
| order_status | Status referente ao pedido realizado |
| order_purchase_timestamp | Horário da realização do pedido de compra online |
| order_approved_at | Horário de aprovação do pedido |
| order_delivered_carrier_date | Horário de coleta do pedido por parte da transportadora |
| order_delivered_customer_date | Horário de entrega do pedido ao cliente |
| order_estimated_delivery_date | Horário de estimativa de entrega do pedido ao cliente |
Metadados do conjunto olist_order_items_dataset:
| Atributo | Descrição |
| order_id | Identificador único de um pedido realizado de maneira online |
| order_item_id | Número sequencial que serve como um índice para os itens que contemplam um determinado pedido |
| product_id | Identificador único de um produto que faz parte de um pedido |
| seller_id | Identificador único do vendedor do determinado pedido |
| shipping_limit_date | Data máxima fornecida pelo vendedor para envio do pedido |
| price | Valor do produto |
| freight_value | Valor do frete do pedido |
No final do dia, a grande ideia por trás da aplicação Spark a ser construída está relacionada a implementação de algumas transformações individuais em cada uma das origens, selecionando, transformando ou agregando alguns atributos, com uma posterior operação de join entre os datasets para criação de uma base única contendo todos os indicadores selecionados e agregados.
O objetivo é gerar um novo dataset contendo as seguintes informações:
| Atributo Preparado | Descrição |
| order_id | Identificador único de um pedido realizado de maneira online |
| qty_order_items | Quantidade de itens presentes no pedido |
| sum_order_price | Valor total de todos os produtos do pedido |
| mean_order_price | Média de valor dos produtos do pedido |
| max_order_price | Valor do produto mais caro do pedido |
| min_order_price | Valor do produto mais barato do pedido |
| mean_order_freight_value | Valor médio calculado entre os itens do pedido |
Em suma, estamos falando sobre criar uma aplicação Spark capaz de realizar a leitura de uma base de dados (disponibilizada como uma tabela no Glue Data Catalog), aplicar alguns processos de transformação e, enfim, gerar uma tabela especializada contendo indicadores estatísticos considerando agrupamentos específicos que provavelmente fazem sentido sob a ótica de extração de valor para o negócio. Aproveitando este gancho, a ideia é coletar dados de itens de pedidos online de modo a extrair indicadores relacionados a preço, frete e outras agregações importantes para a extração de insights.
Em uma versão visual da proposta estabelecida, considere o diagrama abaixo como um guia para corroborar com as as futuras decisões a serem tomadas no decorrer do desenvolvimento da nossa aplicação:

Ainda sobre o esboço do diagrama acima, é possível perceber e analisar alguns detalhes adicionais sobre como os campos da tabela de destino são gerados. Além disso, é possível notar a necessidade de aplicar uma operação de join entre as tabelas de origem pelo campo order_id, permitindo assim gerar a visão esperada de múltiplos campos agregados para cada pedido online realizado.
Ferramentas Auxiliares
Não é intenção do autor deste artigo deixar seus leitores perdidos no deserto. Para iluminar ainda mais o caminho daqueles que insistiram na leitura até aqui, irei deixar alguns links com referências extremamente úteis sobre ferramentas que podem ajudar a configurar um ambiente AWS de modo a garantir a reprodução de todas as etapas a serem consolidadas.
O módulo Terraform datadelivery pode ser utilizado para a obtenção de dados pré catalogados em uma conta AWS
O módulo Terraform terraglue pode ser utilizado para criação de jobs Glue pré configurados em uma conta AWS
A biblioteca Python sparksnake pode ser utilizada para facilitar a criação de aplicações Spark com blocos de código prontos
A 19ª edição do Itaú Data Science Meetup contém uma rica apresentação sobre as três ferramentas acima citadas
Todas as referências acima elencadas são opcionais e servem apenas para fins de explorações adicionais que os leitores mais curiosos possam vir a ter eventualmente. A proposta de padronização de aplicações Spark a ser registrada aqui não depende diretamente destes tópicos, entretanto, possuir o dataset olist_order_items_dataset previamente catalogado em uma conta AWS pode ser um diferencial importante para reproduzir fielmente as etapas deste artigo (e de possíveis outros artigos baseados neste).
Consulte, estude, seja curioso ou apenas continue a leitura do jeito que preferir :)
E aí, bora mergulhar nessa missão e criar uma aplicação Spark que atenda todos esses requisitos seguindo as melhores práticas de desenvolvimento de código, testes unitários e todo o resto? Se sua respsosta foi positiva, aqui então começa a nossa saga.
A Estruturação dos Arquivos da Aplicação
Entendido todo o contexto por trás dos objetivos a serem alcançados, talvez o primeiro passo lógico em busca da padronização de aplicações Spark seja, de fato, a estruturação da árvore dos arquivos que farão parte do todo. Nessa proposta, a árvore abaixo considera todos os elementos e scripts Python necessários para a definição da estrutura da aplicação Spark a ser posteriormente desenvolvida:
└───app
├───src
│ │ main.py
│ └─transformers.py
│
└───tests
│ conftest.py
│ test_transformers.py
│ __init__.py
│
└───helpers
│ user_inputs.py
└─__init__.py
E assim temos algumas definições importantes relacionadas aos principais diretórios considerados nessa árvore de arquivos:
| Diretório | Descrição |
app/ | Diretório da aplicação. Normalmente é posicionado na raíz do repositório e contém todos os insumos da aplicação Spark. |
src/ | Subdiretório contendo os scripts de origem da aplicação, como o próprio script principal e também scripts auxiliares que eventualmente podem fazer sentido dentro da dinâmica de organização estabelecida. |
tests/ | Subdiretório contendo todos os insumos necessários para o desenvolvimento de testes unitários da aplicação, incluindo possíveis scripts auxiliares utilizados para facilitar a criação dos testes. |
Dentro de cada subdiretório definido, arquivos específicos serão posicionados visando estabelecer uma estratégia padrão para facilitar toda a jornada de construção, manutenção e testagem da aplicação Spark. Em termos visuais, a imagem abaixo auxilia no entendimento da organização dos arquivos.
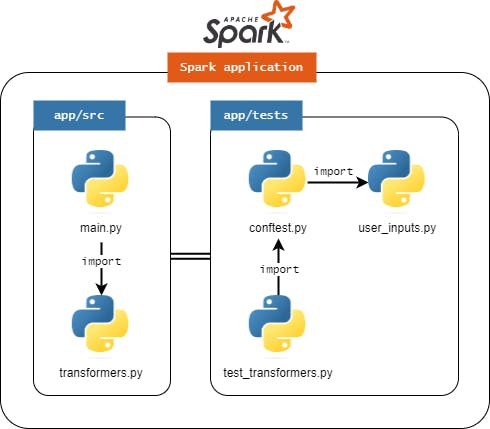
Em termos técnicos, cada um dos arquivos considerados possui um significado e um papel específico na dinâmica da aplicação. Para entender cada uma dessas funções, a tabela abaixo consolida um resumo simplificado de cada arquivo presente:
| Arquivo | Descrição |
src/main.py | Script principal da aplicação. É aqui onde o coração da aplicação Spark existe e faz morada. Nele, todas as bibliotecas, módulos auxiliares e funções são importadas de modo a consolidar toda a lógica e as regras de negócio estabelecidas para a execução do processo. |
src/transformers.py | Para evitar que o script principal da aplicação seja sobrecarregado com milhares de linhas de código, na proposta idealizada por este artigo, o script auxiliar transformers.py comporta todas as transformações Spark definidas dentro do objetivo da aplicação. É aqui onde o usuário irá idealmente criar funções que recebem objetos do tipo DataFrames, aplicam transformações Spark e, por fim, retornam novos objetos do tipo DataFrame. Tudo ficará mais claro nas próximas seções. |
tests/conftest.py | É aqui onde os usuários irão definir todas as fixtures necessárias para a construção dos testes unitários da aplicação. Não sabe o que é uma fixture? Assista a Live de Python #168 do Eduardo Mendes e seja feliz! |
tests/test_transformers.py | Com um script auxiliar bem definido para alocação de todas as transformações Spark, fica fácil separar um script de testes unitários capaz de testar algumas etapas deste processo. Assim, é neste script de testes que o usuário irá definir todos os casos de testes das funções de transformação criadas em src/transformers.py. |
test/helpers/user_inputs.py | Para facilitar a definição de DataFrames mockados que simulam os dados de origem e os resultados das funções de transformação presentes em src/transformers.py, o script tests/helpers/user_inputs.py pode ser preenchido com dicionários Python contendo schemas dos dados utilizados no processo. |
E assim, como principais pontos de destaque desta etapa de estruturação dos arquivos da aplicação, temos:
A aplicação considera um script principal (
main.py) e pelo menos um script auxiliar (transformers.py)O script auxiliar tem por objeto centralizar todas as transformações Spark aplicadas em cada uma das origens do processo
Idealmente, essas transformações podem ser consolidadas no script auxiliar como funções Python que recebem e retornam DataFrames. O conteúdo destas funções é composto por toda a lógica de transformação, seja ela feita em pyspark nativo ou SparkSQL.
Para facilitar a criação de DataFrames a serem utilizados nos testes, o arquivo
user_inputs.pypode ser preenchido com estruturas Python (ex: dicionários) com chaves específicas de modo a simular schemas de DataFrames de origem e de resultado das funções de transformação do processoFixtures podem ser criadas no arquivo
tests/conftest.pyTestes unitários do script auxiliar de transformação podem ser criados em
tests/test_transformers.py
Visando estabelecer uma linha lógica de construção da aplicação Spark, as seguintes etapas serão realizadas nas próximas seções deste artigo:
Construção do script auxiliar com todas as funções de transformação da aplicação (
transformers.py)Construção do script principal da aplicação (
main.py)Consolidação dos schemas dos DataFrames de origem e dos DataFrames resultantes dos processos de transformação (
user_inputs.py)Criação das fixtures para os testes unitários (
conftest.py)Criação dos testes unitários das funções de transformação (
test_transformers.py)
Vamos nessa!
Desenvolvimento da Aplicação
O Script de Transformações Spark
Bom, após um mergulho importante nos detalhes estruturais da nossa aplicação e, sabendo exatamente onde queremos chegar em termos de resultados esperados do processo de ETL idealizado, o primeiro passo de desenvolvimento de código envolve alterações no script transformers.py.
Antes de colocar a mão na massa, é importante reforçar que, na proposta estabelecida, o script transformers.py é o responsável por alocar todas as transformações Spark da aplicação, sendo considerado como o principal elemento do nosso script principal. É aqui onde vamos definir todas as regras de negócio e transformações Spark, sejam elas em pyspark nativo ou SparkSQL.
Idealmente, iremos construir uma função Python de transformação para cada uma das origens da nossa aplicação Spark. Isto é, se estamos trabalhando com múltiplas origens de dados que posteriormente se unem em um processo de join ou union, então a proposta giraria em torno da construção de uma função para cada uma das origens.
No caso do nosso cenário exemplificado, estamos falando da seguinte sequência de operações:
Definir uma função de transformação para as transformações aplicadas na origem olist_order_dataset
Definir uma função de transformação para as transformações aplicadas na origem olist_orders_items_dataset
Definir uma função de transformação para aplicar a junção entre as origens olist_order_dataset e olist_orders_items_dataset com uma subsequente seleção de atributos para gerar a tabela final
Essa proposta acima detalhada poderia ser aplicada em qualquer outro contexto que envolva transformar ou juntar origens de modo a gerar uma tabela resultante. Nela, define-se uma função Python para cada uma das origens e, subsequentemente, uma última função Python que aplica processos de união entre as origens de modo a gerar a tabela final esperada. De toda forma, o usuário encontra-se livre para definir a melhor estratégia dentro de seus objetivos específicos a serem solucionados.
Em caso de dúvidas sobre a estratégia definida para a aplicação das tranformações no script transformers.py, volte algumas seções e analise os metadados das origens e como estes se relacionam em meio ao objetivo final estabelecido.
Para seguirmos adiante no processo e, ainda visando esclarecer mais o a etapa da proposta que envolve as transformações Spark aplicadas, o código abaixo represente o próprio conteúdo do arquivo transformers.py com todas as funções Python já definidas. O script contempla também propostas de uma boa documentação, tratamento de exceções, logs e várias outras boas práticas capazes de serem adpatadas em qualquer módulo adicional. Olhe com atenção todos os elementos.
"""Centralizes transformation functions to be applied on the main application.
This module holds functions that builds DAGs for transforming Spark DataFrames
in a Spark application execution. The big idea is to organize the entire
application in order to have business rules applied in one module. With this
approach, this module can be imported in a main script (e.g. main.py) and
its functions can be called to map the DAGs to raw DataFrames to get
transformations applied.
___
"""
# Importing libraries
from sparksnake.utils.log import log_config
from sparksnake.manager import SparkETLManager
from pyspark.sql import DataFrame
from pyspark.sql.functions import col, sum, mean, max, min, count, round
# Setting up a logger object
logger = log_config(logger_name=__file__)
# Transformation method: df_orders
def transform_orders(df: DataFrame) -> DataFrame:
"""Creates a DAG to transform orders data.
This function is responsible for applying the business rules to the
orders DataFrame in order to create a new and prepared DataFrame object.
Here are the steps taken:
1. Cast date attributes presented as string columns on the raw DataFrame
2. Extact date attributes from the order_purchase_ts column in
order to get more information about customers behavior on buying online.
Args:
df (DataFrame): A Spark DataFrame where transformations will be applied
Returns:
A new Spark DataFrame with a mapped transformation DAG.
"""
logger.info("Preparing a transformation DAG for df_orders DataFrame")
try:
# Creating a list of date attributes do be casted
date_cols = [
"order_purchase_ts",
"order_approved_at",
"order_deliv_carrier_dt",
"order_deliv_customer_dt",
"order_estim_deliv_dt"
]
# Defining a common date format
date_fmt = "dd/MM/yyyy HH:mm"
# Iterating over date cols and calling a sparksnake method
df_orders_date_cast = df
for date_col in date_cols:
df_orders_date_cast = SparkETLManager.date_transform(
df=df_orders_date_cast,
date_col=date_col,
date_col_type="timestamp",
convert_string_to_date=True,
date_format=date_fmt
)
# Extracting date attributes from order purchase date
df_orders_prep = SparkETLManager.date_transform(
df=df_orders_date_cast,
date_col="order_purchase_ts",
convert_string_to_date=False,
year=True,
month=True,
dayofmonth=True
)
# Selecting attributes
df_orders_prep = df_orders_prep.selectExpr(
"order_id",
"order_status",
"year_order_purchase_ts",
"month_order_purchase_ts",
"dayofmonth_order_purchase_ts"
)
return df_orders_prep
except Exception as e:
logger.error("Error on preparing a transformation DAG for orders "
f"dataset. Exception: {e}")
raise e
# Transformation method: df_order_items
def transform_order_items(df: DataFrame) -> DataFrame:
"""Creates a DAG to transform order items data.
This function is responsible for applying the business rules to the
order_items DataFrame in order to create a new and prepared DataFrame
object. Here are the steps taken:
1. Group data by order_id to extract some statistics about item's price
Args:
df (DataFrame): A Spark DataFrame where transformations will be applied
Returns:
A new Spark DataFrame with a mapped transformation DAG.
"""
logger.info("Preparing a transformation DAG for df_order_items DataFrame")
try:
# Casting the shipping limit column to timestamp
df_order_items_stats = df.groupBy("order_id").agg(
count("product_id").alias("qty_order_items"),
round(sum("price"), 2).alias("sum_order_price"),
round(mean("price"), 2).alias("mean_order_price"),
round(max("price"), 2).alias("max_order_price"),
round(min("price"), 2).alias("min_order_price"),
round(mean("freight_value"), 2).alias("mean_order_freight_value"),
)
# Selecting attributes
df_order_items_prep = df_order_items_stats.selectExpr(
"order_id",
"qty_order_items",
"sum_order_price",
"mean_order_price",
"max_order_price",
"min_order_price",
"mean_order_freight_value"
)
return df_order_items_prep
except Exception as e:
logger.error("Error on preparing a transformation DAG for order_items "
f"dataset. Exception: {e}")
raise e
# Transformation method: joining datasets
def transform_final_table(**kwargs) -> DataFrame:
"""Creates a DAG to transform the final dataset.
This function is responsible for joining all transformed DataFrames in
order to create a single DataFrame object with all required data. The
transformation step considers applying a join operation using prepared
versions of the raw DataFrames.
In the end, a select statement will ensure that all fields match the
expected schema for the SoT table.
Keyword Args:
df_orders_prep (DataFrame):
A prepared Spark DataFrame for tbl_orders
df_order_items_prep (DataFrame):
A prepared Spark DataFrame for tbl_order_items
Returns:
A new Spark DataFrame with a mapped transformation DAG.
"""
# Getting individual DataFrames from kwargs
df_orders_prep = kwargs["df_orders_prep"]
df_order_items_prep = kwargs["df_order_items_prep"]
logger.info("Preparing a transformation DAG for final DataFrame")
try:
# Joining all the prepared DataFrames
df_prep_join = df_orders_prep.join(
other=df_order_items_prep,
on=[df_orders_prep.order_id == df_order_items_prep.order_id]
).drop(df_order_items_prep.order_id)
# Selecting final attributes
df_prep = df_prep_join.selectExpr(
"order_id",
"order_status",
"year_order_purchase_ts",
"month_order_purchase_ts",
"dayofmonth_order_purchase_ts",
"qty_order_items",
"sum_order_price",
"mean_order_price",
"max_order_price",
"min_order_price",
"mean_order_freight_value"
)
except Exception as e:
logger.error("Error on preparing a transformation DAG for final "
f"dataset. Exception: {e}")
raise e
# Returning the final table
return df_prep
Algumas considerações:
Para uma maior organização, foi criada uma função de transformação para cada uma das origens presentes no processo, sendo uma última função de transformação responsável por aplicar um processo de join entre os DataFrames preparados resultantes das referidas funções.
Os nomes das funções de transformação foram escolhidos com base na identificação das origens do processo (ou do destino, no caso da função de preparação final).
Cada função de transformação pode ser alimentada com lógicas de transformação em Spark, sejam estas codificadas em
pysparknativo ouSparkSQL. O que realmente importa é que tais funções consigam preparar as DAGs de transformação a serem acionadas posteriormente no job.Na proposta aqui consolidada, o uso da biblioteca
sparksnakese faz presente em alguns cenários. Esta é uma biblioteca externa com algumas funções prontas capazes de facilitar a criação de etapas de transformação. Seu uso é totalmetne opcional e o, mais uma vez, o usuário pode alimentar suas funções de transformação com qualquer que seja a forma de criar DAGs em Spark.
Perceba que, considerando os objetivos da nossa aplicação traçados no início do artigo, as funções recebem um objeto do tipo DataFrame Spark e aplicam algumas transformações visando retornar um outro objeto do tipo DataFrame conforme um schema pré estabelecido. Essa é a mais pura essência do script transformers.py. Independente da quantidade de origens e das transformações a serem consolidadas, a ideia é que o usuário desenvolva diferentes funções capazes de consolidar transformações Spark conforme seu senso de organização apontar.
Se esta lógica for aplicada com sucesso, o overhead no script principal será substancialmente reduzido, facilitando a organização do código e posteriores manutenções. Além disso, essa estratégia permite facilitar a construção de testes unitários capazes de validar os schemas dos DataFrames resultantes, garantindo que as transformações estão realmente retornando os dados esperados pelo usuário.
O Script Principal
Uma vez definido o script auxiliar com as transformações da nossa aplicação Spark, é possível adentrar às etapas de definição do script principal main.py. Para isso, vamos importar as bibliotecas e, conforme o ambiente alvo estabelecido (AWS Glue), vamos desenvolver todos os códigos necessários para ler, transformar e escrever dados conforme as especificidades envolvidas.
Apenas para reforçar um ponto já abordado brevemente neste artigo, esta proposta de padronização utiliza o sparksnake como principal ferramenta responsável por facilitar todo o desenvolvimento de jobs Glue na AWS. Em uma genuína sugestão de pausa, retire um tempo para navegar pela documentação do
sparksnakee verificar que, de fato, esta pode ser uma opção extremamente poderosa dentro de sua jornada de desenvolvimento de aplicações Spark, especialmente se estas forem utilizadas em serviços AWS, como o Glue ou o EMR.
E assim, nosso script main.py pode ser definido como:
"""An example of Spark application for reading SoR data and creating SoT table.
This scripts uses sparksnake for creating a Spark application to be deployed as
a Glue job on AWS that reads data from SoR layer, transform it and generate a
new SoT table based on Ecommerce public data. The idea is to provide to users
an end to end example on how it's possible to build a Glue job for common
ETL task.
___
"""
# Importing libraries
from sparksnake.manager import SparkETLManager
from sparksnake.utils.log import log_config
from transformers import transform_orders,\
transform_order_items,\
transform_final_table
from datetime import datetime
# Setting up a logger object
logger = log_config(logger_name=__file__)
# Defining the list of job arguments
ARGV_LIST = [
"JOB_NAME",
"OUTPUT_BUCKET",
"OUTPUT_DB",
"OUTPUT_TABLE",
"OUTPUT_TABLE_URI",
"CONNECTION_TYPE",
"UPDATE_BEHAVIOR",
"PARTITION_NAME",
"PARTITION_FORMAT",
"OUTPUT_DATA_FORMAT",
"COMPRESSION",
"ENABLE_UPDATE_CATALOG",
"NUM_PARTITIONS"
]
# Defining a dictionary with all data to be read and used on job
DATA_DICT = {
"orders": {
"database": "db_datadelivery_sor",
"table_name": "tbl_brecommerce_orders",
"transformation_ctx": "dyf_orders",
"create_temp_view": True
},
"order_items": {
"database": "db_datadelivery_sor",
"table_name": "tbl_brecommerce_order_items",
"transformation_ctx": "dyf_order_items",
"create_temp_view": True
}
}
# Creating a sparksnake object with Glue operation mode
spark_manager = SparkETLManager(
mode="glue",
argv_list=ARGV_LIST,
data_dict=DATA_DICT
)
# Initializing the job
spark_manager.init_job()
# Reading Spark DataFrames from Data Catalog
dfs_dict = spark_manager.generate_dataframes_dict()
# Indexing data do get individual DataFrames
df_orders = dfs_dict["orders"]
df_order_items = dfs_dict["order_items"]
# Transforming DataFrame: orders
df_orders_prep = transform_orders(df=df_orders)
# Transforming DataFrame: order_items
df_order_items_prep = transform_order_items(df=df_order_items)
# Joining all DataFrames and preparing the final table
df_prep = transform_final_table(
df_orders_prep=df_orders_prep,
df_order_items_prep=df_order_items_prep,
)
# Defining a variable for holding the partition value
partition_value = int(datetime.now().strftime(
spark_manager.args["PARTITION_FORMAT"]))
# Adding a partition column
df_prep_partitioned = spark_manager.add_partition_column(
df=df_prep,
partition_name=spark_manager.args["PARTITION_NAME"],
partition_value=partition_value
)
# Repartitioning the Dataframe to reduce small files and optimize storage
df_prep_repartitioned = spark_manager.repartition_dataframe(
df=df_prep_partitioned,
num_partitions=spark_manager.args["NUM_PARTITIONS"]
)
# Defining an URI for output table partition
s3_partition_uri = f"{spark_manager.args['OUTPUT_TABLE_URI']}/"\
f"{spark_manager.args['PARTITION_NAME']}={partition_value}"
# Dropping partition on s3 (if it exists)
spark_manager.drop_partition(s3_partition_uri=s3_partition_uri)
# Writing data on S3 and cataloging it on Data Catalog
spark_manager.write_and_catalog_data(
df=df_prep_repartitioned,
s3_table_uri=spark_manager.args["OUTPUT_TABLE_URI"],
output_database_name=spark_manager.args["OUTPUT_DB"],
output_table_name=spark_manager.args["OUTPUT_TABLE"],
partition_name=spark_manager.args["PARTITION_NAME"],
connection_type=spark_manager.args["CONNECTION_TYPE"],
update_behavior=spark_manager.args["UPDATE_BEHAVIOR"],
compression=spark_manager.args["COMPRESSION"],
enable_update_catalog=bool(spark_manager.args["ENABLE_UPDATE_CATALOG"]),
output_data_format=spark_manager.args["OUTPUT_DATA_FORMAT"]
)
Algumas considerações:
O script principal utiliza algumas poderosas features da biblioteca
sparksnakepara facilitar a definição de operações específicas no serviço AWS GlueAs funções de transformação definidas previamente são então importadas do script
transformers.pyconsiderando o módulo auxiliar chamadotransformers(a ser posteriormente adicionado no job do Glue dentro do parâmetro--extra-py-files)Variáveis como
ARGV_LISTeDATA_DICTpodem ser considerados como elementos específicos da dinâmica de uso da bibliotecasparksnakee/ou do próprio GlueProcessos de particionamento e reparticionamento foram codificados de forma opcional utilizando features do
sparksnake
Seguindo esta dinâmica, todas as funções de transformação poderiam ser desenvolvidas no script transformers.py, enquanto o script main.py seria responsável por suas respectivas importações e aplicações no código. Unindo esta dinâmica à utilização do sparksnake como uma biblioteca Python, temos em mãos uma poderosa combinação capaz de dar vida à aplicações Spark organizadas, estruturadas e fáceis de serem testadas e mantidas.
Ainda tem mais por vir e, agora que temos todo o coração da aplicação já definido, podemos voltar nossos esforços às etapas de testagem.
Testando a Aplicação
Chegamos à tão temida etapa de testagem da nossa aplicação Spark! Aqui, vamos explorar todas as etapas necessárias para construir nossos primeiros testes unitários realmente úteis de acordo com os nossos objetivos estabelecidos. Em essência, os testes unitários propostos aqui terão os seguintes objetivos:
Validar a construção de objetos do tipo DataFrame capazes de representarm os dados de origem e os dados de destino de cada função de tranformação
Validar se as funções de transformação estão retornando os atributos esperados pelas regras estabelecidas
Para cumprir tais objetivos, precisamos, em um primeiro momento, definir uma forma de etstabelecer exatamente os atributos dos DataFrames de origem e os atributos esperados dos métodos de transformação. É aqui que utilizamos nosso querido script user_inputs.py.
Definindo Schemas para os DataFrames
Como um primeiro passo na jornada de criação de testes unitários, vamos alimentar nosso script auxiliar em tests/helpers/user_inputs para declarar dicionários Python capazes de representar todas as origens utilizadas no processo e também todos os DataFrames resultantes de funções de transformação consolidadas. O objetivo é criar DataFrames fictícios capazes de serem utilizados como fixtures.
"""Putting together user inputs to help on building fixtures and test cases.
This file aims to put together all variables used on fixture definitions and
test cases that requires user inputs as a way to configure or validate
something.
___
"""
# Defining a dictionary with all source data used on the Glue Job
SOURCE_DATAFRAMES_DICT = {
"tbl_brecommerce_orders": {
"name": "tbl_brecommerce_orders",
"dataframe_reference": "df_orders",
"empty": False,
"fake_data": False,
"fields": [
{
"Name": "idx",
"Type": "int",
"nullable": True
},
{
"Name": "order_id",
"Type": "string",
"nullable": True
},
{
"Name": "customer_id",
"Type": "string",
"nullable": True
},
{
"Name": "order_status",
"Type": "string",
"nullable": True
},
{
"Name": "order_purchase_ts",
"Type": "string",
"nullable": True
},
{
"Name": "order_approved_at",
"Type": "string",
"nullable": True
},
{
"Name": "order_deliv_carrier_dt",
"Type": "string",
"nullable": True
},
{
"Name": "order_deliv_customer_dt",
"Type": "string",
"nullable": True
},
{
"Name": "order_estim_deliv_dt",
"Type": "string",
"nullable": True
}
],
"data": [
(1, "e481f51cbdc54678b7cc49136f2d6af7", "9ef432eb6251297304e76186b10a928d", "delivered", "02/10/2017 10:56", "02/10/2017 11:07", "04/10/2017 19:55", "10/10/2017 21:25", "18/10/2017 00:00"),
(2, "53cdb2fc8bc7dce0b6741e2150273451", "b0830fb4747a6c6d20dea0b8c802d7ef", "delivered", "24/07/2018 20:41", "26/07/2018 03:24", "26/07/2018 14:31", "07/08/2018 15:27", "13/08/2018 00:00"),
(3, "47770eb9100c2d0c44946d9cf07ec65d", "41ce2a54c0b03bf3443c3d931a367089", "delivered", "08/08/2018 08:38", "08/08/2018 08:55", "08/08/2018 13:50", "17/08/2018 18:06", "04/09/2018 00:00"),
(4, "949d5b44dbf5de918fe9c16f97b45f8a", "f88197465ea7920adcdbec7375364d82", "delivered", "18/11/2017 19:28", "18/11/2017 19:45", "22/11/2017 13:39", "02/12/2017 00:28", "15/12/2017 00:00"),
(5, "ad21c59c0840e6cb83a9ceb5573f8159", "8ab97904e6daea8866dbdbc4fb7aad2c", "delivered", "13/02/2018 21:18", "13/02/2018 22:20", "14/02/2018 19:46", "16/02/2018 18:17", "26/02/2018 00:00"),
(6, "a4591c265e18cb1dcee52889e2d8acc3", "503740e9ca751ccdda7ba28e9ab8f608", "delivered", "09/07/2017 21:57", "09/07/2017 22:10", "11/07/2017 14:58", "26/07/2017 10:57", "01/08/2017 00:00"),
(7, "136cce7faa42fdb2cefd53fdc79a6098", "ed0271e0b7da060a393796590e7b737a", "invoiced", "11/04/2017 12:22", "13/04/2017 13:25", "09/05/2017 00:00", "", ""),
(8, "6514b8ad8028c9f2cc2374ded245783f", "9bdf08b4b3b52b5526ff42d37d47f222", "delivered", "16/05/2017 13:10", "16/05/2017 13:22", "22/05/2017 10:07", "26/05/2017 12:55", "07/06/2017 00:00"),
(9, "76c6e866289321a7c93b82b54852dc33", "f54a9f0e6b351c431402b8461ea51999", "delivered", "23/01/2017 18:29", "25/01/2017 02:50", "26/01/2017 14:16", "02/02/2017 14:08", "06/03/2017 00:00"),
(10, "e69bfb5eb88e0ed6a785585b27e16dbf", "31ad1d1b63eb9962463f764d4e6e0c9d", "delivered", "29/07/2017 11:55", "29/07/2017 12:05", "10/08/2017 19:45", "16/08/2017 17:14", "23/08/2017 00:00")
]
},
"tbl_brecommerce_order_items": {
"name": "tbl_brecommerce_order_items",
"dataframe_reference": "df_order_items",
"empty": False,
"fake_data": False,
"fields": [
{
"Name": "order_id",
"Type": "string",
"nullable": True
},
{
"Name": "order_item_id",
"Type": "bigint",
"nullable": True
},
{
"Name": "product_id",
"Type": "string",
"nullable": True
},
{
"Name": "seller_id",
"Type": "string",
"nullable": True
},
{
"Name": "shipping_limit_date",
"Type": "string",
"nullable": True
},
{
"Name": "price",
"Type": "double",
"nullable": True
},
{
"Name": "freight_value",
"Type": "double",
"nullable": True
}
],
"data": [
("a4591c265e18cb1dcee52889e2d8acc3", 1, "060cb19345d90064d1015407193c233d", "8581055ce74af1daba164fdbd55a40de", "2017-07-13 22:10:13", 147.9, 27.36),
("ad21c59c0840e6cb83a9ceb5573f8159", 1, "65266b2da20d04dbe00c5c2d3bb7859e", "2c9e548be18521d1c43cde1c582c6de8", "2018-02-19 20:31:37", 19.9, 8.72),
("e481f51cbdc54678b7cc49136f2d6af7", 1, "87285b34884572647811a353c7ac498a", "3504c0cb71d7fa48d967e0e4c94d59d9", "2017-10-06 11:07:15", 29.99, 8.72),
("e69bfb5eb88e0ed6a785585b27e16dbf", 1, "9a78fb9862b10749a117f7fc3c31f051", "7c67e1448b00f6e969d365cea6b010ab", "2017-08-11 12:05:32", 149.99, 19.77),
]
}
}
# Defining a dictionary with all the expected results of transformation methods
EXPECTED_DATAFRAMES_DICT = {
"tbl_brecommerce_orders": {
"dataframe_reference": "df_orders_prep",
"empty": True,
"fake_data": False,
"fields": [
{
"Name": "order_id",
"Type": "string",
"nullable": True
},
{
"Name": "order_status",
"Type": "string",
"nullable": True
},
{
"Name": "year_order_purchase_ts",
"Type": "int",
"nullable": True
},
{
"Name": "month_order_purchase_ts",
"Type": "int",
"nullable": True
},
{
"Name": "dayofmonth_order_purchase_ts",
"Type": "int",
"nullable": True
}
],
"data": []
},
"tbl_brecommerce_order_items": {
"dataframe_reference": "df_order_items_prep",
"empty": True,
"fake_data": False,
"fields": [
{
"Name": "order_id",
"Type": "string",
"nullable": True
},
{
"Name": "qty_order_items",
"Type": "bigint",
"nullable": True
},
{
"Name": "sum_order_price",
"Type": "double",
"nullable": True
},
{
"Name": "mean_order_price",
"Type": "double",
"nullable": True
},
{
"Name": "max_order_price",
"Type": "double",
"nullable": True
},
{
"Name": "min_order_price",
"Type": "double",
"nullable": True
},
{
"Name": "mean_order_freight_value",
"Type": "double",
"nullable": True
}
],
"data": []
},
"tbl_prep": {
"dataframe_reference": "df_prep",
"empty": True,
"fake_data": False,
"fields": [
{
"Name": "order_id",
"Type": "string",
"nullable": True
},
{
"Name": "order_status",
"Type": "string",
"nullable": True
},
{
"Name": "year_order_purchase_ts",
"Type": "int",
"nullable": True
},
{
"Name": "month_order_purchase_ts",
"Type": "int",
"nullable": True
},
{
"Name": "dayofmonth_order_purchase_ts",
"Type": "int",
"nullable": True
},
{
"Name": "qty_order_items",
"Type": "bigint",
"nullable": True
},
{
"Name": "sum_order_price",
"Type": "double",
"nullable": True
},
{
"Name": "mean_order_price",
"Type": "double",
"nullable": True
},
{
"Name": "max_order_price",
"Type": "double",
"nullable": True
},
{
"Name": "min_order_price",
"Type": "double",
"nullable": True
},
{
"Name": "mean_order_freight_value",
"Type": "double",
"nullable": True
}
],
"data": []
}
}
Observando o código acima, é possível destacar a criação de duas principais variáveis a serem posteriormente importadas em scripts de testes e de criação de fixtures, sendo elas:
SOURCE_DATAFRAMES_DICT: descreve detalhes sobre todos os objetos do tipo DataFrame a serem criados para simular todas as origens de dados presences no processo de ETLEXPECTED_DATAFRAMES_DICT: descreve detalhes sobre todos os objetos do tipo DataFrame a serem criados para simular todos os DataFrames resultantes dos processos de transformação, sejam intermediários ou final.
Nessa proposta, ambas as variáveis são materializadas por dicionários Python e possuem uma construção com chaves e valores específicos para a configuração das características dos processos de criação dos DatFrames. Para dar uma maior clareza a este processo, a padronização destes dicionários consideram as seguintes chaves:
| Chave do Dicionário | Descrição |
| name | Nome ou identificador da tabela a ser "mockada" |
| dataframe_reference | Nome ou referência para o DataFrame alvo a ser criado com base nas informações mockadas da tabela |
| empty | Flag booleana que indica se o usuário deseja criar um DataFrame vazio para a dada tabela |
| fake_data | Flag booleana que indica se o usuário deseja criar um DataFrame com dados fictícios para a dada tabela (dados gerados a partir da biblioteca Faker) |
| fields | Listagem de todos os campos da tabela a ser mockada e materializada como um DataFrame Spark. Por padrão, esta chave recebe uma lista de cicionários contendo, cada um, informações que representam o nome do atributo (chave "Name"), seu tipo primitivo (chave "Type") e se o atributo aceita dados nulos (chave "nullable"). |
| data | Caso o usuário não queira criar um DataFrame vazio ("empty": False) e nem usar dados fictícios para popular o DataFrame ("fake_data": False), então a chave "data" pode ser utilizada para o input manual de registros a serem considerados no ato da criação do DataFrame. Aqui, o usuário pode utilizar uma amostra já extraída de suas origens para fornecer exemplos mais próximos à realidade e que possam facilitar a criação de testes unitários. Por fim, a chave "data" é formada por uma lista de tuplas, facilitando assim a criação de objetos do tipo DataFrame Spark. |
Dessa forma, o preenchimento do arquivo user_inputs.py, nesse caso, represente as seguintes operações sob a ótica de testes da nossa aplicação Spark:
A variável
SOURCE_DATAFRAMES_DICTé composta por definições sobre as duas origens presentes no processo referenciadas por "tbl_brecommerce_orders", e "tbl_brecommerce_order_items"As informações preenchidas no dicionário
SOURCE_DATAFRAMES_DICTindicam a criação de dois objetos DataFrame utilizando registros fornecidos manualmente na chave "data"Já a variável
EXPECTED_DATAFRAMES_DICTé alimentada com informações sobre todos os objetos DataFrame resultantes (e esperados) de processos de transformação. Nesse caso, temos três funções de transformações definidas emtransformers.pye, sendo assim, três conjuntos de dados foram consolidados (preparação da base de pedidos, preparação da base de itens de pedidos e, por fim, a base final gerada a partir da junção entre as duas bases já citadas).
Eu sei, algumas coisas ainda podem parecer confusas até aqui. A criação do arquivo user_inputs.py é, de fato, algo novo proposto para facilitar a criação de fixtures representadas por objetos DataFrame existentes no nosso processo de ETL. Se, até aqui, isso pode parecer confuso, na próxima seção vamos criar, de fato, as fixtures prometidas para tentar dar mais transparência a tudo o que estamos fazendo até o momento.
Criando Fixutres
Uma vez definida todos os detalhes dos objetos DataFrames a serem validados na etapa de teste através do arquivo user_inputs.py, é chegado o momento de usar nosso arquivo conftest.py para criação das fixtures necessárias para facilitar a criação das funções de teste.
Para saber mais detalhes sobre fixtures, indico grandemente a Live de Python #168 do Eduardo Mendes. Certamente, um conteúdo excelente e que explica praticamente tudo o que você precisará saber sobre fixtures no contexto do pytest.
Pois bem, é hora de colocar a mão na massa! Para criar as fixtures necessárias para nossa aplicação Spark, insira conteúdo abaixo no arquivo conftest.py. Como de costume, explicações e comentários adicionais serão fornecidos logo em seguida.
"""Confest file for managing pytest fixtures and other components.
This file will handle essential components and elements to be used on test
scripts along the project, like features and other things.
___
"""
# Importing libraries
import pytest
import findspark
from sparksnake.tester.dataframes import generate_dataframes_dict
from pyspark.sql import SparkSession, DataFrame
from tests.helpers.user_inputs import SOURCE_DATAFRAMES_DICT,\
EXPECTED_DATAFRAMES_DICT
from src.transformers import transform_orders,\
transform_order_items,\
transform_final_table
# Getting the active SparkSession object (or creating one)
findspark.init()
spark = SparkSession.builder.getOrCreate()
# Returning the SparkSession object as a fixture
@pytest.fixture()
def spark_session(spark: SparkSession = spark) -> SparkSession:
return spark
# Executing a sparksnake's function to read all predefined DataFrames for test
@pytest.fixture()
def dataframes_dict(spark_session: SparkSession):
# Creating a empty dictionary to hold all source and expected DataFrames
dataframes_dict = {}
# Getting all source DataFrame objects
dataframes_dict["source"] = generate_dataframes_dict(
definition_dict=SOURCE_DATAFRAMES_DICT,
spark_session=spark_session
)
# Getting all expected DataFrame objects
dataframes_dict["expected"] = generate_dataframes_dict(
definition_dict=EXPECTED_DATAFRAMES_DICT,
spark_session=spark_session
)
return dataframes_dict
""" ------------------------------------------------
Fixture block for df_orders DataFrame
------------------------------------------------ """
# A DataFrame object for the source df_orders DataFrame
@pytest.fixture()
def df_orders(dataframes_dict: dict) -> DataFrame:
return dataframes_dict["source"]["df_orders"]
# A DataFrame object with the expected schema for df_orders
@pytest.fixture()
def df_orders_expected(dataframes_dict: dict) -> DataFrame:
return dataframes_dict["expected"]["df_orders_prep"]
# A DataFrame object that is the result of the df_orders transformation
@pytest.fixture()
def df_orders_prep(df_orders: DataFrame) -> DataFrame:
return transform_orders(df=df_orders)
""" ------------------------------------------------
Fixture block for df_order_items DataFrame
------------------------------------------------ """
# A DataFrame object for the source df_order_items DataFrame
@pytest.fixture()
def df_order_items(dataframes_dict: dict) -> DataFrame:
return dataframes_dict["source"]["df_order_items"]
# A DataFrame object with the expected schema for df_order_items
@pytest.fixture()
def df_order_items_expected(dataframes_dict: dict) -> DataFrame:
return dataframes_dict["expected"]["df_order_items_prep"]
# A DataFrame object that is the result of the df_orders transformation
@pytest.fixture()
def df_order_items_prep(df_order_items: DataFrame) -> DataFrame:
return transform_order_items(df=df_order_items)
""" ------------------------------------------------
Fixture block for df_prep DataFrame
------------------------------------------------ """
# A DataFrame object with the expected schema for df_prep
@pytest.fixture()
def df_prep_expected(dataframes_dict: dict) -> DataFrame:
return dataframes_dict["expected"]["df_prep"]
# A DataFrame object that is the result of the df_sot transformation
@pytest.fixture()
def df_prep(
df_orders_prep: DataFrame,
df_order_items_prep: DataFrame
) -> DataFrame:
return transform_final_table(
df_orders_prep=df_orders_prep,
df_order_items_prep=df_order_items_prep,
)
Em linhas gerais, grande parte do segredo por trás da criação das fixtures acima está vinculado a utilização da função generate_dataframes_dict() da biblioteca sparksnake. A documentação desta função pode ser encontrada no seguinte link.
Basicamente, a função generate_dataframes_dict() utiliza um dicionário previamente definido e configurado com informações específicas para gerar múltiplos objetos do tipo DataFrame e salvá-los em um outro dicionário de retorno. E aqui temos a primeira grande justificativa da criação das variáveis SOURCE_DATAFRAMES_DICT e EXPECTED_DATAFRAMES_DICT no script user_inputs.py: com a facilidade proporcionada pelo uso da função generate_dataframes_dict(), os dicionários acima citados servem como uma base sólida de definição de todas as estruturas de dados de origem do nosso processo de ETL, bem como todas as estruturas esperadas de etapas intermediárias de transformação ou mesmo da estrutura final de dados do processo.
Com isso, a fixture dataframes_dict nasce como um novo dicionário Python contendo todos os elementos de origem (definidos em SOURCE_DATAFRAMES_DICT) e também todos os elementos de saída (definidos em EXPECTED_DATAFRAMES_DICT). Todos esses elementos são, em essência, objetos do tipo Spark DataFrame capazes de serem utiliados para criação de novas fixtures capazes de realmente simular as entradas e as saídas da nossa aplicação Spark.
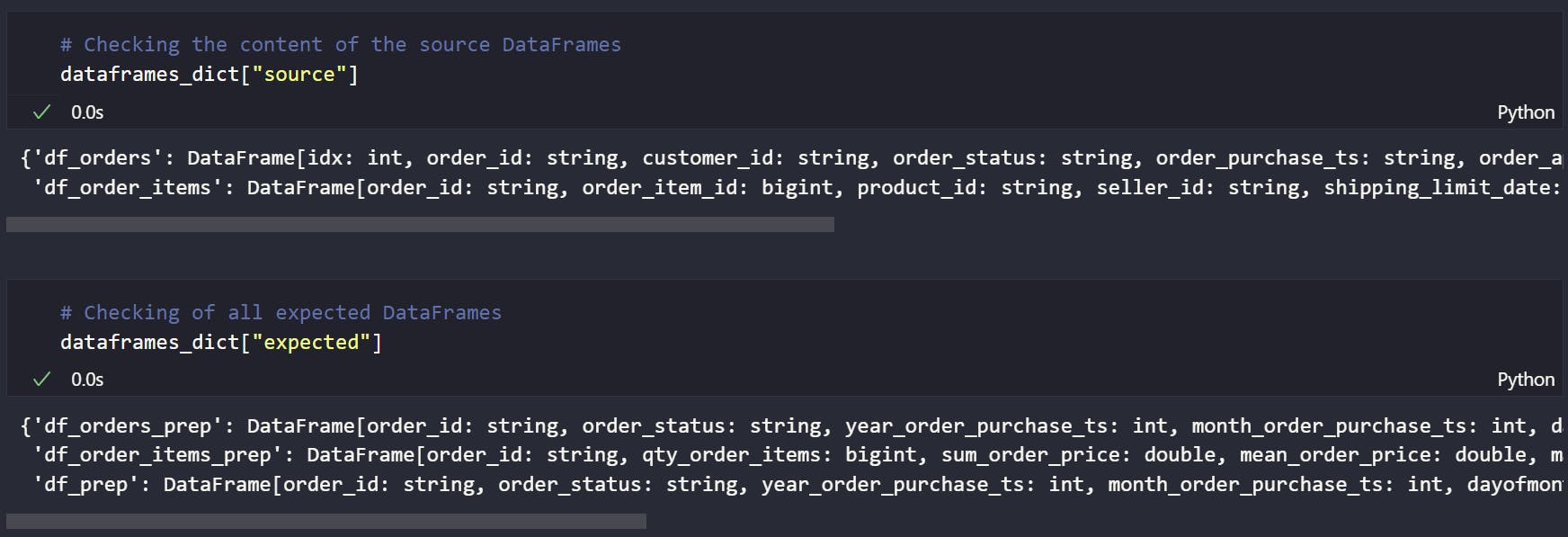
Dica importante: caso queira entender mais essa proposta de criação de fixtures através da definição de dicionários específicos aplicados a uma função de criação e simulação de DataFrames, instale a biblioteca sparksnake e utilize um Jupyter Notebook para importar e aplicar a função
generate_dataframes_dict()de modo a observar seu resultado. Na imagem abaixo, temos uma representação da fixturedataframes_dictinclusa na proposta como parte do processo de criação de DataFrames Spark a serem utilizados em novas fixtures capazes de representarem as entradas e as saídas de todo o processo de ETL.
Ao analisar o conteúdo do dicitonário
dataframes_dict, vemos que, tanto para as entradas (chave"source") quanto para as saídas (chave"expected"), o conteúdo representa objetos DataFrame criados com base nos dicionários de definição preenchidos pelo usuário para cada uma das respectivas finalidades (variáveisSOURCE_DATAFRAMES_DICTeEXPECTED_DATAFRAMES_DICT).
Cada elemento deste dicionário é indicado por uma chave que representa o próprio DataFrame e foi previamente informada pelo usuário no dicionário de definição de DataFrames. Veja você mesmo a grande sacada por trás dessa abordagem e use isso para associar o conhecimento sobre como realmente as fixtures estão sendo abordas nessa proposta.

Assim, entendido o cenário de criação e simulação de DataFrames através da fixture dataframes_dict, entramos em um bloco individual de fixtures para cada objeto DataFrame a ser simulado nos testes que envolve três diferentes cenários, sendo eles:
Uma fixture que representa o próprio DataFrame a ser simulado como uma entrada/origem do processo de ETL (ex:
df_orders)Uma fixture que representa o próprio DataFrame a ser simulado como o resultado esperado do processo de transformação associado ao mesmo (ex:
df_orders_expected)Uma fixture que representa o próprio DataFrame a ser simulado como resultado de um processo de transformação associado ao mesmo (ex:
df_orders_prep)
Enquanto os dois primieros cenários envolvem basicamente indexações na fixture dataframes_dict de modo a retornar os objetos DataFrame simulados nos dicionários de definição de origem e de saída, o terceiro cenário envolve a importação da função de transformação definida no script auxiliar transformers.py e aplicá-la ao DataFrame de origem, gerando assim um resultado capaz de ser validado posteriormente em testes unitários. Isto permite responder perguntas como: "o DataFrame resultante do meu método de transformação está realmente batendo com o esperado?"
E assim, com as fixtures definidas nesta proposta, podemos finalmente iniciar a construção dos testes unitários capazes de validar alguns blocos fundamentais relacionados aos objetos da aplicação e as etapas de transforamação devidamente codificadas. Antes disso, visando reforçar algumas características esencialmente válidas nessa proposta que nos ajudaram a chegar até aqui da forma mais organizada possível:
A importância de termos segregado as funções de transformação em scripts diferentes da aplicação principal permitem validar localmente algumas regras de negócio sem a necessidade de importar o script principal com o risco de incorrer a erros de uso de bibliotecas específicas (ex:
awsglue)A importância de termos em mãos objetos do tipo DataFrame capazes de serem utilizados nos mais variados cenários de testes.
Desenvolvendo Testes Unitários
Agora que já temos em mãos todos os insumos necessários dentro do objetivo de testagem da nossa aplicação, é possível iniciar a jornada de construção dos testes unitários responsáveis por adicionar uma camada de confiabilidade ao nosso processo de ETL.
Dentro da proposta estabelecida por este artigo, os testes unitários irão se resumir a:
Validar se as funções de transformação estão retornando os objetos esperados (ex: Spark DataFrames)
Validar se as funções de transformação estão retornando DataFrames com o schema esperado pelo usuário
Validar possíveis exceções eventualmente codificadas nas funções de transformação
Neste momento, é importante admitir um débito técnico relacionado a completude de testes desenvolvidos nesta proposta de padronização. Em outras palavras, teríam uma série de outras validações que poderiam ser realizadas em termos de testes unitários e, por questões de objetividade, os três tópicos apontados acima foram selecionados para uma visão inicial sobre o que pode ser feito em relação aos testes.
Ainda neste ponto, também vale estabelecer que os usuários consumidores deste artigo continuam com total liberdade para adaptar, incrementar ou até refatorar a proposta aqui apresentada. Mais uma vez, no final do dia, a responsabilidade por aquilo que está sendo entregue é do próprio desenvolvedor.
Assim, aproveitando tudo o que já foi consolidado ao longo deste arquivo, vamos preencher nosso arquivo test_transformers.py com o seguinte conteúdo:
"""Test cases for DAG transformation functions in transformer.py module
This file handles all unit tests to check if the transformations coded on
transformers.py src module are working properly. The idea is to ensure that
transformations are generating the expected result based on the output
DataFrame schemas.
___
"""
# Importing libraries
import pytest
from pyspark.sql import DataFrame
from sparksnake.tester.dataframes import compare_schemas
from src.transformers import transform_orders,\
transform_order_items,\
transform_final_table
@pytest.mark.transform_orders
def test_df_orders_transformation_generates_a_spark_dataframe_object(
df_orders_prep
):
"""
G: Given that users want to transform the df_orders DataFrame
W: When the function transform_orders() is called
T: Then the return must be a Spark DataFrame
"""
assert type(df_orders_prep) is DataFrame
@pytest.mark.transform_orders
def test_df_orders_transformation_generates_the_expected_schema(
df_orders_prep,
df_orders_expected
):
"""
G: Given that users want to transform the df_orders DataFrame
W: When the function transform_orders() is called
T: Then the schema of the returned DataFrame must match the expected
"""
assert compare_schemas(
df1=df_orders_prep,
df2=df_orders_expected,
compare_nullable_info=False
)
@pytest.mark.transform_orders
def test_error_on_calling_transform_orders_function():
"""
G: Given that users want to transform the df_orders DataFrame
W: When the function transform_orders() is called with an invalid
argument (i.e. an object different than a Spark DataFrame)
T: Then an Exception must be raised
"""
with pytest.raises(Exception):
_ = transform_orders(df=None)
@pytest.mark.transform_order_items
def test_df_order_items_transformation_generates_a_spark_dataframe_object(
df_order_items_prep
):
"""
G: Given that users want to transform the df_order_items DataFrame
W: When the function transform_order_items() is called
T: Then the return must be a Spark DataFrame
"""
assert type(df_order_items_prep) is DataFrame
@pytest.mark.transform_order_items
def test_df_order_items_transformation_generates_the_expected_schema(
df_order_items_prep,
df_order_items_expected
):
"""
G: Given that users want to transform the df_order_items DataFrame
W: When the function transform_order_items() is called
T: Then the schema of the returned DataFrame must match the expected
"""
assert compare_schemas(
df1=df_order_items_prep,
df2=df_order_items_expected,
compare_nullable_info=False
)
@pytest.mark.transform_order_items
def test_error_on_calling_transform_order_items_function():
"""
G: Given that users want to transform the df_order_items DataFrame
W: When the function transform_order_items() is called with an invalid
argument (i.e. an object different than a Spark DataFrame)
T: Then an Exception must be raised
"""
with pytest.raises(Exception):
_ = transform_order_items(df=None)
@pytest.mark.transform_final_table
def test_df_prep_transformation_generates_a_spark_dataframe_object(
df_prep
):
"""
G: Given that users want to transform the df_prep DataFrame
W: When the function transform_final_table() is called
T: Then the return must be a Spark DataFrame
"""
assert type(df_prep) is DataFrame
@pytest.mark.transform_final_table
def test_df_prep_transformation_generates_the_expected_schema(
df_prep,
df_prep_expected
):
"""
G: Given that users want to transform the df_prep DataFrame
W: When the function transform_final_table() is called
T: Then the schema of the returned DataFrame must match the expected
"""
assert compare_schemas(
df1=df_prep,
df2=df_prep_expected,
compare_nullable_info=False
)
@pytest.mark.transform_final_table
def test_error_on_calling_transform_final_table_function():
"""
G: Given that users want to transform the df_prep DataFrame
W: When the function transform_final_table() is called with an invalid
argument (i.e. an object different than a Spark DataFrame)
T: Then an Exception must be raised
"""
with pytest.raises(Exception):
_ = transform_final_table(
df_orders_prep=None,
df_order_items_prep=None
)
Observando o bloco de código acima, é possível observar que os casos de teste da suíte seguem os três pontos elencados previamente. Se tomarmos como exemplo aquilo que ocorre com a origem representada pelo DataFrame df_orders, temos os seguintes casos:
test_df_orders_transformation_generates_a_spark_dataframe_object(): função que testa se a fixturedf_orders_prep, isto é, o objeto resultante da função de transformaçãotransform_orders()definido como uma fixture no arquivoconftest.pyé, de fato, um objeto do tipo DataFrame.test_df_orders_transformation_generates_the_expected_schema(): função que testa se o resultado do método de transformaçãotransform_orders()gera um DataFrame com um schema esperado pelo usuário dentro das regras de negócio aplicada. O resultado esperado pelo usuário foi previametne definido no dicionárioEXPECTED_DATAFRAMES_DICTno arquivouser_inputs.py.test_error_on_calling_transform_orders_function(): por fim, esta função testa se a funçãotransform_orders()realmente lança uma Exceção ao ser chamada com um argumento inválido (como por exemplo, um valor vazio para o argumentodf_ordersesperado pela função como sendo um objeto do tipo DataFrame).
E assim, esse combo pode se repetir para todas as origens e etapas de transformação de uma aplicação Spark a ser implantada em qualquer ambiente. Esta estratégia pode garantir alguns resultados interessantes aos usuários, como a validação de que as funções de transformação estão operando corretamente, retornando os objetos esperados e com atributos previamente definidos.
Para executar a suíte de testes localmente, basta ter o pytest instalado e executar o seguinte comando:
pytest -vv
Nesse caso em específico, como estamos falando de uma aplicação Spark a ser implantada como um job Glue na AWS, temos uma barreira específica de utilização das bibliotecas do Glue em ambientes locais. Dessa forma, tentar importar o script principal ocasionaria em exceções de módulos não encontrados (ModuleNotFound Exception) por conta dessa ausência. Uma alternativa seria utilizar uma imagem Docker com as bibliotecas do Glue previamente instaladas para a execução de testes mais específicos que envolvam operações consolidadas no script principal da aplicação.
Mas aqui temos uma situação vantajosa de toda a abordagem adotada nessa proposta: pelo fato de termos segregado praticamente todas as operações de transformação Spark em um script apartado e independente de bibliotecas específicas, podemos construir uma boa suíte de testes que valida os resultados finais e intermediários dessas transformações, garantindo que os resultados esperados da aplicação possam ser devidamente validados.
Conclusões e Comentários Finais
Caros leitores, após uma longa jornada de detalhamento de todas as etapas de construção de uma aplicação Spark de acordo com uma proposta criada e aqui divulgada por um eterno aprendiz, chegamos nos momentos finais onde resumimos tudo o que alcançamos até este ponto.
Em suma, a proposta de padronização de uma aplicação Spark sob a ótica deste mero escritor, envolve:
A definição de uma estrutura de arquivos específica capaz de facilitar o desenvolvimento dos códigos
A criação de um módulo auxiliar representado por um arquivo chamado
transformers.pyresponsável por alocar todas as transformações Spark da aplicação materializadas em funções Python que podem ser definidas de acordo com estratégias específicas (uma por origem, uma por etapa, etc)A criação de um script principal da aplicação denominado
main.pycomo sendo o grande responsável por importar os módulos auxiliares (funções de transformação) e todas as demais bibiotecas necessárias. O script principal é onde grande serão alocadas as lógicas de leitura, execução das funções de transformação e escrita dos dados para alcançar os objetivos da aplicação Spark.A criação de um arquivo auxiliar chamado
user_inputs.pypara consolidar todos os schemas dos objetos DataFrame das origens da aplicação Spark e dos resultados esperados pelas etapas de transformação. Tais schemas são consolidados no referido arquivo através de dicionários Python que seguem uma estrutura específica conforme a funçãogenerate_dataframes_dict()da bibliotecasparksnakeA criação de um arquivo chamado
conftest.pypara alocação de todas as fixtures necessárias para a construção dos testes unitários. As fixtures são representadas, em essência, por objetos do tipo DataFrame representando as origens do processo e os resultados das etapas intermediárias de transformação.Finalmente, finalizamos a proposta com a criação de um script de testes chamado
test_transformers.pycom a responsabilidade de alocar casos de testes aplicados às funções de transformação definidas no script auxiliartransformes.py. O objetivo é validar se as funções de transformação estão retornando os objetos esperados e com os schemas esperados pelo usuário dentro das regras de negócio estabelecidas.
Mais uma vez, é importante reforçar que as etapas acima fazem parte de uma proposta de padronização de uma aplicação Spark criada com base em experiências reais dentro de um escopo reduzido de trabalho. Com toda a humildade do mundo, existem grandes chances de que essa proposta de padronização não se aplique à todas as realidades de desenvolvimento de aplicações Spark existentes. As possibilidades são gigantescas e seria uma pretensão injusta estabelecer que tudo o que foi consolidado neste artigo deveria ser a fonte da verdade para todos os problemas. Não é e nunca será.
Portanto, a mensagem que eu deixo aos usuários e leitores que venceram essa luta e chegaram até o final deste artigo é: entenda aquilo que você está desenvolvendo e use este conhecimento para adaptar e propor novas ideias que facilitem suas próprias construções.
Como uma dica adicional, deixo o link da aplicação Spark escrita para ser o exemplo implantado no
terragluequando configurado no "learning mode": terraglue/app at main · ThiagoPanini/terraglue (github.com)Aqui, vocês vão ver toda essa filosofia de padronização em uma escala maior, com mais origens, mais funções de transformação, mais fixtures e mais casos de teste. Aproveitem!
É isso e espero que tenham curtido essa jornada. Muito obrigado!