




Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark!
O Apache Spark é, indubitavelmente, uma ferramenta extraordinária capaz de proporcionar uma série de funcionalidades à seus usuários de acordo com as mais variadas necessidades de processamento de dados. Através das APIs estruturadas, os desenvolvedores podem construir códigos utilizando componentes de alto nível que abstraem grande parte da complexidade das estruturas distribuídas presentes nesta dinâmica, permitindo transformar conjuntos de dados de diferentes formatos e com uma gigantesca gama de possibilidades. E assim, o código construído é então remodelado em um plano lógico, convertido em um plano físico e, por fim, executado paralelamente ao longo de múltiplas máquinas (ou processos) como operações otimizadas de baixo nível.
O parágrafo acima traz um resumo excepcionalmente simplório sobre a mecânica de utilização do Spark em cenários típicos de processamento de dados. Na prática, muito poderia ser dito sobre cada uma das etapas acima mencionadas em um amplo espaço de discussões e troca de conhecimentos. Entretanto, considerando os objetivos estabelecidos para este artigo, a proposta que se faz presente envolve mergulhar em uma esfera relativamente pouco explorada no âmbito de estudos sobre o Spark: a arquitetura e os principais componentes de uma aplicação Spark submetida para execução.
Embarque nesta jornada!
Componentes de uma aplicação Spark
Em outras grandes oportunidades nesta mesma série, uma aplicação Spark pôde resumidamente ser definida como um programa formado por um conjunto de elementos responsáveis por orquestrar toda a dinâmica de execução das respectivas instruções codificadas em um cluster de computadores.
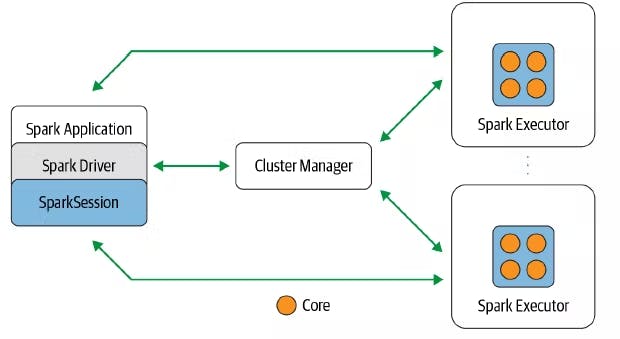
Em linhas gerais, este programa possui um objeto de sessão, conhecido por SparkSession, capaz de proporcionar, aos desenvolvedores, um verdadeiro elo funcional entre a linguagem de programação utilizada (Python, Scala, Java, R) e as APIs Estruturadas (DataFrames, Datasets, SparkSQL, entre outras). É possível então afirmar, com total clareza, que a sessão Spark é um elemento fundamental de qualquer aplicação Spark, dado que, a partir dela, todas as classes, métodos e operações podem ser codificadas de acordo com os propósitos estabelecidos.
Uma vez submetida, a aplicação Spark possuirá, em seu ciclo de vida, componentes fundamentais capazes de criar e manter toda a dinâmica necessária para que o código desenvolvido e alocado seja, de fato, executado de acordo com as especificidades do ambiente utilizado. Em um modelo padrão de trabalho, os componentes existentes são:
Driver: pode ser definido como um processo existente em uma máquina física do cluster que controla toda a execução de uma aplicação Spark, mantendo o estado de todas as tarefas executadas e a saúde dos processos relacionados. Possui uma interface de comunicação estritamente próxima com o cluster manager para garantir a existência dos recursos necessários capazes de serem utilizados para alocação e execução das atividades.
Executors: são os processos responsáveis por executar as tarefas propriamente designadas pelo driver. Seu papel é claro e direto: receber as tarefas, executá-las e então reportar os estados (sucesso ou falha) e os resultados ao driver.
Em um ambiente distribuído, os processos driver e executors existem em máquinas de um cluster de computadores. Para gerenciar toda essa dinâmica, o cluster manager se faz presente como uma forma de manter e coordenar as máquinas físicas responsáveis pela execução de uma aplicação Spark. Assim como a conduta de uma aplicação Spark envolve um processo central e múltiplos "trabalhadores", um cluster manager também possui suas próprias abstrações normalmente conhecidas como master e workers presentes em nós (ou máquinas).
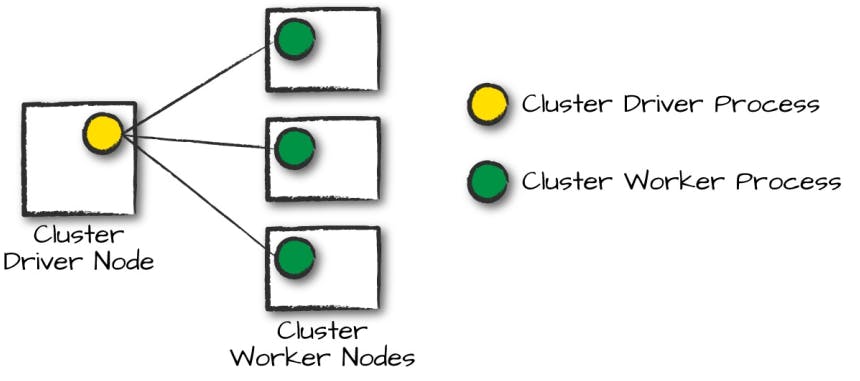
Assim, quando uma aplicação Spark é submetida para execução (via spark-submit ou qualquer outro meio), uma requisição por recursos é realizada ao cluster manager para sua viabilização. Ao longo de sua execução, esse gerenciamento é feito de tal modo a garantir que as máquinas físicas do cluster estejam sempre aptas e prontas para receber as demandas do código submetido.
Por mais nobre que toda esta jornada de execução de uma aplicação Spark seja, nem sempre os usuários estarão submetendo códigos utilizando um cluster de computadores. Em cenários exploratórios e de aprendizado, tudo o que se tem é uma única máquina pessoal de trabalho como recurso. Diante disso, seria impossível então executar aplicações Spark em meio a inexistência de um cluster de computadores? Para responder esta pergunta, é importante entender sobre os modos de execução de uma aplicação Spark.
Modos de execução
A escolha de um modo de execução é, provavelmente, a primeira ação necessária após toda a configuração do ambiente e a codificação de uma aplicação Spark pronta para ser submetida.
Um modo de execução permite determinar a localização dos recursos e processos responsáveis por executar uma aplicação. Ao todo, existem três modos possíveis:
- Cluster mode
- Client mode
- Local mode
Cluster mode
Este é o modo mais comum relacionado à execução de aplicações Spark para processamento de dados. No cluster mode, o script contendo toda a lógica de transformação codificada é submetido ao cluster manager (Apache Mesos, Hadoop YARN ou Standalone) que, por sua vez, inicializa um processo driver em um nó worker dentro do cluster, além dos processos executors. Isto significa que o gerenciador do cluster é responsável por manter todos os processos Spark relacionados à aplicação.
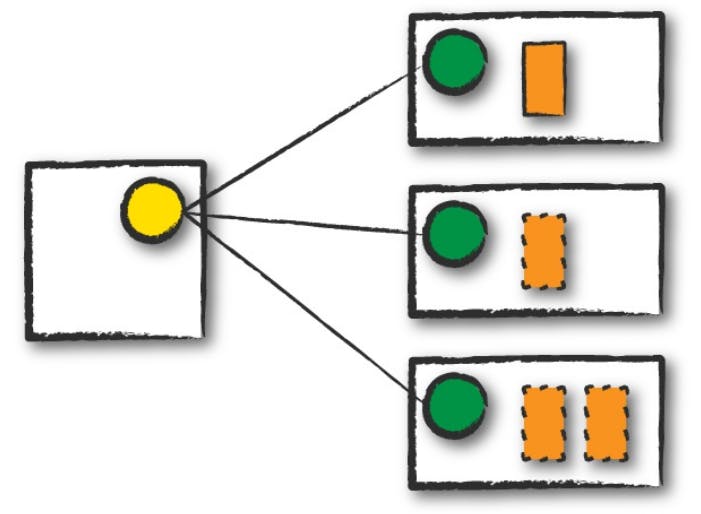
Na figura acima, é possível identificar como o cluster manager possui um papel fundamental na execução de aplicações Spark utilizando o cluster mode. O nó master (representado pelo círculo amarelo) gerencia a inicialização de um processo driver (retângulo laranja contínuo) e múltiplos processos executors (retângulos laranja tracejados) nos nós worker (representados por círculos verde).
Em grandes companhias e estruturas criadas para processar grandes quantidades de dados, este fatalmente será o modo principal de execução de aplicações Spark. Entretanto, este modo não é absoluto e existem outras variações que podem ser endereçadas de acordo com propósitos específicos.
Client mode
O client mode é essencialmente similar ao cluster mode em quase todos os aspectos, com exceção da localização do processo driver para coordenação das tarefas de uma aplicação Spark.
Neste modo, o processo driver se encontra na máquina responsável por submeter a aplicação (e não em um nó worker do cluster, como no cluster mode). Na prática, isto significa que a máquina do client, localizada fora do cluster, é a responsável por gerenciar o processo driver, enquanto o cluster manager atua no gerenciamento dos processos executors dentro do cluster. A comunicação e a relação entre ambos os processos continua igual.
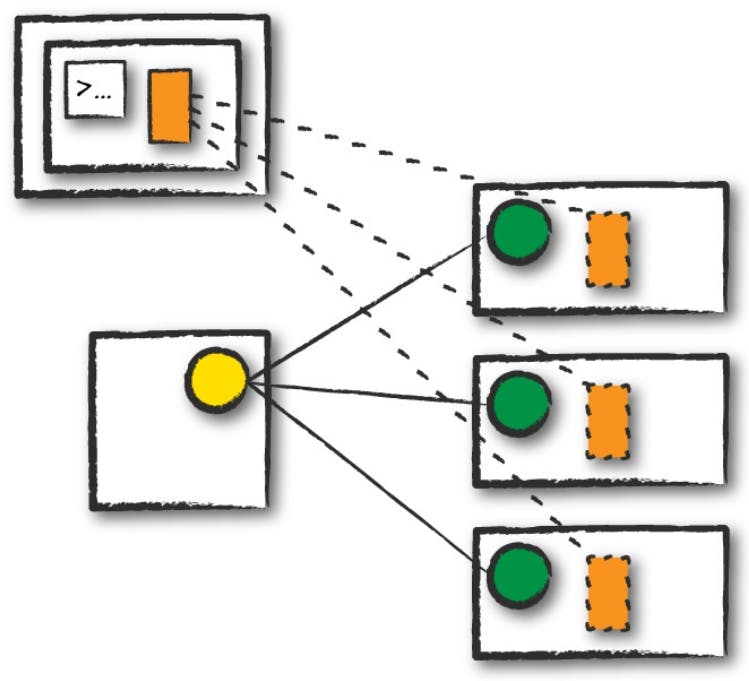
Na figura acima, é possível identificar a máquina client (também chamada de gateway machine ou edge node) em uma posição externa ao cluster e com a presença do processo driver em seu interior. No mais, os nós worker continuam gerenciando os processos executors que, por sua vez, se comunicam diretamente com o driver para reportar os estados e resultados das tarefas de uma aplicação Spark designadas pelo mesmo.
Por fim, é importante ressaltar que tanto o modo cluster quanto o modo client utilizam, como principal ponto de controle, um gerenciador de cluster. De fato, grandes volumes de dados exigem múltiplas máquinas para comportar as exigências que tal cenário exige. Porém, nem sempre aplicações Spark são construídas com base em cenários de Big Data. Em algumas oportunidades, usuários estão apenas explorando as funcionalidades ou mesmo criando aplicações em uma jornada de aprendizado que utiliza uma única máquina pessoal de trabalho como principal fonte computacional de recurso. Felizmente, para estes casos, existe um modo específico de execução capaz de atender tais necessidades.
Local mode
Como introduzido previamente, o local mode pode ser definido como um modo de execução de aplicações Spark totalmente diferente dos modos abordados anteriormente. Nele, toda a execução do código é feita em uma única máquina e o paralelismo é alcançado a partir de threads do sistema operacional.
Esta é uma excelente forma de aprender, testar e experimentar aplicações Spark sem a necessidade de construir um verdadeiro cluster de computadores. Por outro lado, é factível imaginar que o modo local não é indicado para executar aplicações produtivas, dadas as limitações óbvias existentes nesta dinâmica.
Para proporcionar um rápido exemplo de utilização do modo local, o código abaixo utiliza o pyspark e pode ser salvo em um arquivo chamado local-mode-example.py em qualquer máquina pessoal de trabalho que possua o Spark instalado. Seu conteúdo comporta basicamente a criação de um DataFrame a partir de um intervalo de valores no seguinte formato:
# Importando bibliotecas
from pyspark.sql import SparkSession
# Inicializando sessão
spark = SparkSession\
.builder\
.appName(__file__)\
.master("local[*]")\
.getOrCreate()
# Criando DataFrames
df1 = spark.range(0, 5)
df2 = spark.range(5, 10)
df = df1.union(df2)
# Mostrando e coletando dados no driver
df.show()
print(df.collect())
# Encerrando sessão
spark.stop()
Assim, considerando uma instalação local do Spark, o código acima pode ser então submetido como uma aplicação Spark através do comando:
spark-submit --master local ./local-mode-example.py
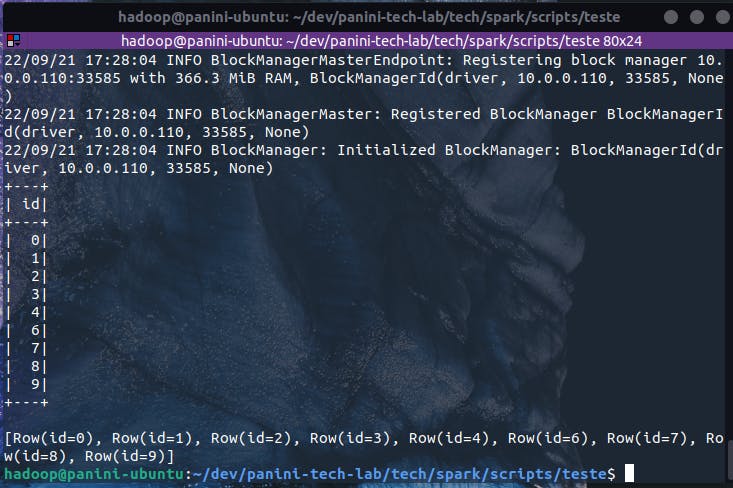
E assim os processos driver e executors foram inicializados na mesma máquina de trabalho para execução da aplicação submetida, simulando toda uma dinâmica de paralelismo comumente encontrada em clusters de computadores.
O interior de uma aplicação Spark
Até este momento, foi possível navegar sobre as principais peças responsáveis por garantir a execução de uma aplicação Spark submetida e como estas se organizam conforme o modo de execução selecionado. A partir de agora, uma nova roupagem ao universo interior das aplicações será fornecida para exemplificar os elementos constituintes dessa dinâmica de execução. Afinal, muito além da interação entre cluster manager, driver e executors, é fundamental entender como um plano físico constituído por múltiplas manipulações em RDDs de baixo nível é recebido, organizado e, por fim, executado.
No geral, aplicações Spark são formadas por métodos e funções aplicadas à conjuntos de dados e dividas em duas principais categorias: transformações e ações. Ao estabelecer a execução de um código construído, as operações desenvolvidas passam por todo o processo conhecido de remodelagem e conversão de planos até que uma série de instruções de baixo nível estejam mapeadas e prontas para serem, de fato, inicializadas nos processos. Diante disso, é correto afirmar que aplicações Spark submetidas para execução são compostas por três principais elementos: jobs, stages e tasks.
Jobs: no geral, há um job para cada ação, visto que toda a ação engatilha processos de transformação e retornam resultados. Cada job é formado por uma série de stages.
Stages: sob a ótica do Spark, os stages representam grupos de tasks que representam operações idênticas e que podem ser executadas em conjunto. Na prática, o Spark empacotará o maior volume de trabalho possível, isto é, o maior número de transformações quanto possível dentro de um mesmo stage. Por natureza, cada novo processo de shuffle inicia um novo stage.
Um shuffle representa um processo de "reparticionamento" de dados no ambiente físico do cluster. Operações como ordenação e agrupamento de dados de uma fonte externa, por exemplo, necessitam que os dados trafeguem entre nós, configurando assim a criação de novos stages. Para um melhor entendimento sobre este contexto, basta procurar por termos como narrow e wide transformations.
- Tasks: uma task pode simplesmente ser definida como uma unidade computacional aplicada à uma unidade de dado (partição). Em outras palavras, cada task é composta por uma combinação de blocos de dados e um conjunto de transformações que serão executadas em um único processo executor. Se o conjunto de dados é composto por 1 única partição, então uma única task será responsável por aplicar dada transformação. Por outro lado, se o conjunto é formado por 1000 partições, então 1000 tarefas serão designadas para o trabalho.
Spark UI e a visualização de jobs
Uma forma extremamente interativa de visualizar e acompanhar a execução de uma aplicação Spark é através da Spark UI (ou Spark User Interface) que, em uma instalação local, pode ser acessada através da porta 4040 do localhost. Assim, para demonstrar um exemplo prático de acompanhamento dos passos de uma aplicação Spark, o primeiro passo necessário será instanciar o shell do pyspark no terminal de trabalho simplesmente digitando o comando:
pyspark
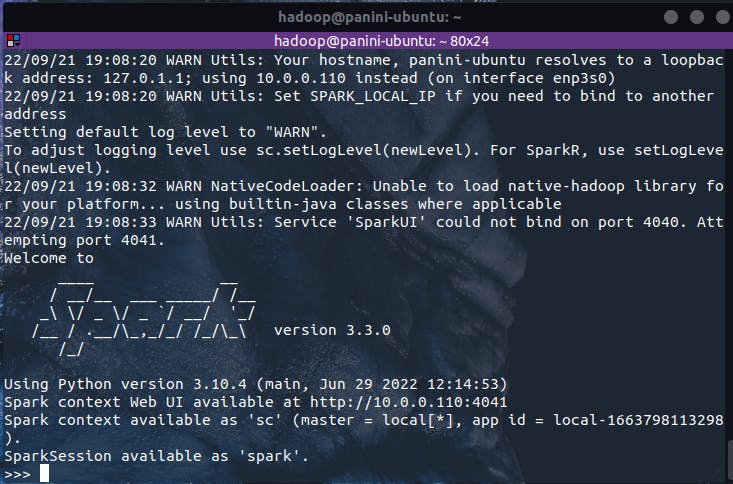
Com isso, um objeto de sessão se encontra disponível sob a variável spark durante a operação no shell. Ao acessar o Spark UI, é possível identificar que, por enquanto, não há nenhum job ou stages em execução. Ao expandir o dropdown "Event Timeline", informações mais detalhadas poderão ser visualizadas.
De volta ao terminal, vamos inicializar um DataFrame sintético a partir de um intervalo de valores (semelhante ao exemplo anteriormente fornecido, porém com um número maior de elementos para que haja tempo suficiente de visualização das etapas na UI):
df1 = spark.range(1, 10000)
Neste momento, apenas uma instrução de criação de um conjunto distribuído de dados foi fornecida ao Spark. Ao navegar pela Spark UI, nada pode ser visualizado pois, de fato, nenhum gatilho de ação foi implementado. Dessa forma, vamos informar ao Spark o desejo de lançar a execução desta operação de criação de DataFrame definida a partir de uma ação:
df1.show(5)
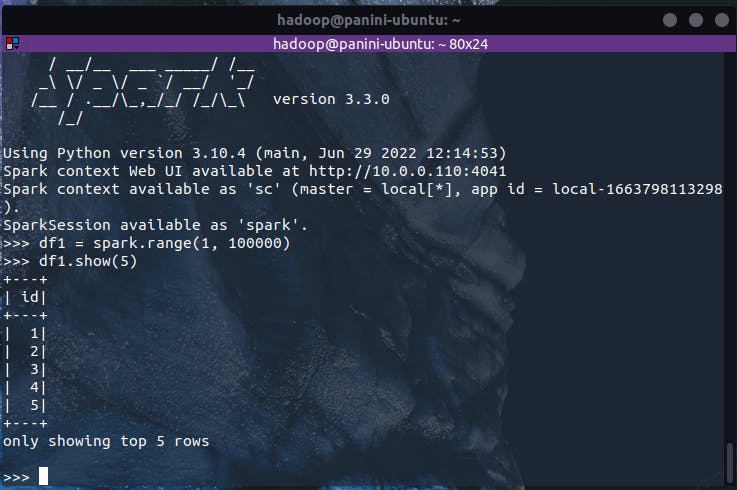
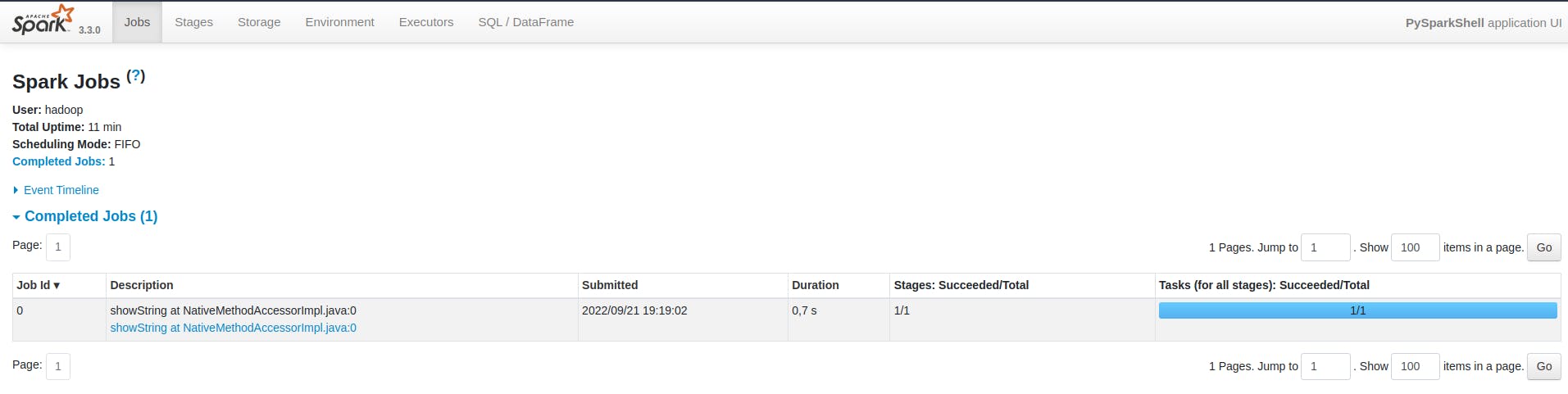
A partir deste ponto, a Spark UI irá informar ao usuário que um job foi devidamente lançado e, se tudo correr bem, executado com sucesso. Considerando o conteúdo absorvido neste artigo, é possível identificar alguns elementos importantes, tais como a quantidade de stages (1) e tasks (1) do código submetido. De fato, por se tratar de algo simples, o Spark pôde compactar as operações necessárias em um único bloco formado um stage e uma task.
Navegando pela aba Stages da UI e clicando no hyperlink de detalhes do único stage disponível, é possível observar detalhes extremamente ricos de execução em um universo de baixo nível. Neste mesmo local, é possível até obter uma análise visual da DAG de instruções computacionais considerada para o stage:

Em geral, este tipo de análise é específica para desenvolvedores interessados nos detalhes mais internos de uma aplicação, permitindo encontrar pontos de melhoria de performance ou até mesmo auxiliando em processos de debug.
Retornando ao terminal, vamos implementar algo relativamente mais complexo envolvendo a criação de um segundo DataFrame e o reparticionamento de ambas as estruturas:
df2 = spark.range(1, 50000)
df1_repartitioned = df1.repartition(5)
df2_repartitioned = df2.repartition(6)
Ainda assim, nada de inédito deve ser encontrado na UI, visto que nenhuma ação de gatilho foi executada e apenas instruções foram definidas (você já deve estar craque nisso). Vamos então aplicar um processo de union() entre os dois DataFrames definidos e uma ação de show() para inicializar a DAG. O que se espera encontrar na Spark UI após isso?
df_union = df1_repartitioned.union(df2_repartitioned)
df_union.show(5)
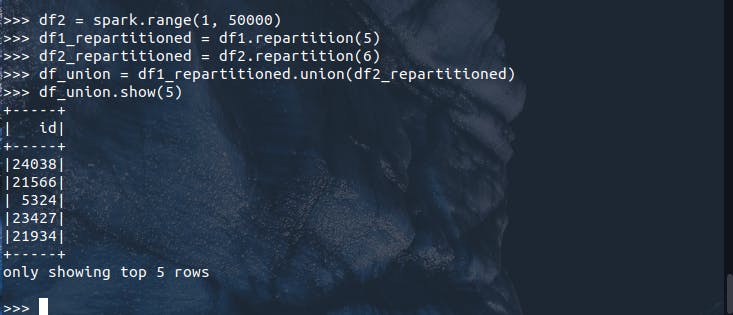
De início, apenas com o resultado da ação show(), é possível visualizar os efeitos do reparticionamento e da união de múltiplos conjuntos distribuídos de dados. Os cinco primeiros elementos aparecem em uma ordem essencialmente aleatória, dadas as características físicas de localização destes registros. Navegando agora pela Spark UI, é possível identificar a presença de três novos jobs representados pelos IDs 1, 2 e 3 na imagem abaixo:
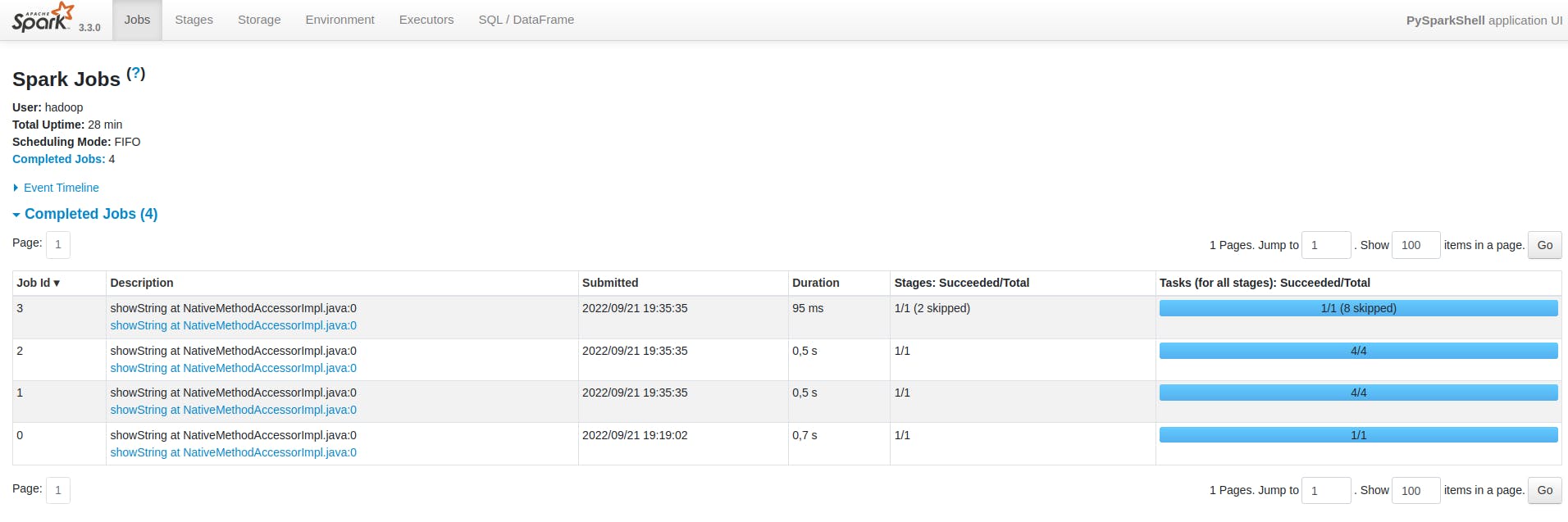
Ao lado de cada job, é possível analisar o número de stages e tasks envolvidas que, por sua vez, dependem das operações definidas e de como o Spark está configurado para operação. É possível que este número seja diferente de acordo com a forma de instalação do Spark existente ou de como o usuário aplicou modificações pontuais nos padrões de uso da ferramenta.
E assim, a medida que novas etapas de transformação são codificadas no script, novos jobs, stages e tasks podem ser considerados ao submeter a aplicação para execução.
Conclusão e encerramento
Conhecer os detalhes internos de composição e execução de uma aplicação Spark traz ganhos absurdamente valiosos para todos os entusiastas e usuários desta magnífica ferramenta. Muito além de saber codificar e construir um script com operações em Spark, é importante ter uma cristalina noção sobre as peças da engrenagem que fazem a mecânica de processamento de dados acontecer.
Neste artigo, foi possível abordar os processos driver e executors como agentes responsáveis por toda a dinâmica organizacional de execução de uma aplicação. Adicionalmente, os modos de execução representados por cluster mode, client mode e local mode também tiveram sua grande participação teórica em se apresentar como diferentes sabores de utilização do Spark. Por fim, os pormenores de uma aplicação puderam ser definidos como jobs, stages e tasks, finalizando assim todo o pacote operacional de manuseio do Spark em cenários práticos de trabalho.
Foi ótimo ter você aqui, caro leitor! Te vejo na próxima!