

O Funcionamento do Spark

Olá, caro leitor! Seja bem vindo a mais um artigo desta importante série sobre Apache Spark onde exploramos toda a fundamentação teórica junto a cenários práticos necessários para um completo entendimento deste maravilhoso framework criado na era do Big Data.
Após uma aconchegante introdução trazida pelo primeiro artigo desta série onde foram apresentados alguns elementos essenciais no plano de surgimento do Spark, é chegado o momento de darmos um passo adicional em nossa jornada de aprendizado de modo a compreender, de fato, a dinâmica de funcionamento desta ferramenta. Siga em frente e tenha uma ótima leitura!
Uma ferramenta unificada
No artigo anterior, o Apache Spark foi definido utilizando duas fontes didáticas diretamente ligadas a seus criadores originais e principais desenvolvedores. Nas definições fornecidas, o Spark foi categoricamente descrito como uma ferramenta unificada para processamento paralelo de dados. Mas, o que significa ser uma ferramenta unificada e qual o impacto prático desta característica? Como um primeiro passo fundamental em busca desta resposta, é preciso considerar a premissa de que "unificar" algo, no sentido mais literal da palavra, significa "juntar" ou "integrar" peças distintas em um local centralizado.
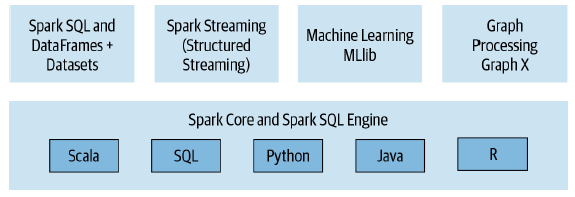
De forma direta, o Spark é composto por quatro componentes distintos que funcionam como verdadeiras bibliotecas capazes de serem utilizadas em diferentes cenários de um projeto de Big Data. Adicionalmente, é possível criar aplicações no Spark utilizando diferentes linguagens de programação, como Scala, Python, R ou Java, proporcionando uma maior liberdade aos usuários para a construção de pipelines de dados. Assim, saindo da visão generalista e entrando agora em um detalhamento mais técnico, estabelecer que o Spark é uma ferramenta unificada significa dizer que seu conteúdo é composto pelos seguintes pilares:
- Spark SQL: módulo utilizado para cargas de trabalho envolvendo dados estruturados. Com SparkSQL, é possível realizar a leitura de dados de uma série de fontes presentes nos mais variados formatos (CSV, texto, JSON, Avro, ORC, Parquet, entre outros) e então construir tabelas temporárias ou permanentes que poderão ser trabalhadas utilizando uma das linguagens de programação aceitas (ou simplesmente SQL).
- Spark MLlib: fatia do Spark responsável por proporcionar uma série de artefatos utilizados para o treinamento de modelos de aprendizado de máquina, desde a transformação dos dados, até algoritmos de treinamento e módulos estatísticos.
- Spark Structured Streaming: componente aplicado em análises de dados em tempo real e baseadas em eventos com origens estabelecidas, por exemplo, no Apache Kafka e outras ferramentas de streaming de dados.
- GraphX: biblioteca para manipulação de grafos em cenários como análises de redes sociais, rotas e pontos de conexão ou topologia de redes.
Se esta característica do Spark ainda não soa poderosa o suficiente, o livro Learning Spark destaca que, em Novembro de 2016, a ACM (Association for Computing Machinery) reconheceu o Apache Spark e conferiu a seus criadores o prestigiado prêmio ACM Award para seu artigo descrevendo o Spark como uma "ferramenta unificada para processamento de Big Data". No artigo vencedor, os autores defendem que o Spark substitui todas as ferramentas isoladas de processamento em batch, streaming, grafos e motores de queries como Storm, Impala, Dremel, Pregel, etc, com um stack unificado de componentes que endereçam diferentes cargas de trabalho em um motor único e distribuído.
De maneira adicional, é correto dizer que qualquer código construído em Spark, seja em um de seus componentes internos (APIs estruturadas) ou escrito em qualquer uma das linguagens de programação aceitas, será integrado e utilizado de maneira unificada dentro de um pipeline único de dados. Em outras palavras, um bloco escrito em Python através do pyspark poderá ser utilizado em conjunto com um código utilizando SparkSQL em uma aplicação única.
E aqui vai a grande sacada: sob uma ótica técnica, isto é possível pois os códigos escritos no Spark são decompostos e convertidos em um formato altamente compacto de bytecode para serem executados em JVMs (Java Virtual Machines) presentes em um cluster de computadores no formato de DAGs (Directed Acyclic Graphs).
Por mais complexo que este último parágrafo possa ter parecido, tudo ficará mais claro daqui em diante.
A aplicação Spark e sua execução distribuída
Até este ponto, o conhecimento adquirido permite dizer que o Spark possui uma série de componentes (muitas vezes referenciados na literatura como bibliotecas ou APIs) que podem ser utilizados em diferentes cenários através de códigos escritos em Scala, Python, R ou Java. Sabendo que tudo isto ocorre no mundo de Big Data, o pipeline criado é executado em um cluster de computadores que, eventualmente, será composto por um gerenciador (YARN, Mesos, etc) e por outros elementos característicos que ativam toda a lógica de processamento paralelo. Este é o primeiro milestone de conhecimento necessário para o entendimento das aplicações Spark.
Nessa dinâmica, uma aplicação Spark é composta por uma série de elementos responsáveis por "fazer a mágica acontecer". De forma ilustrativa, a figura abaixo traz uma visão simplificada sobre como o código escrito pelo usuário é gerenciado e executado no cluster.
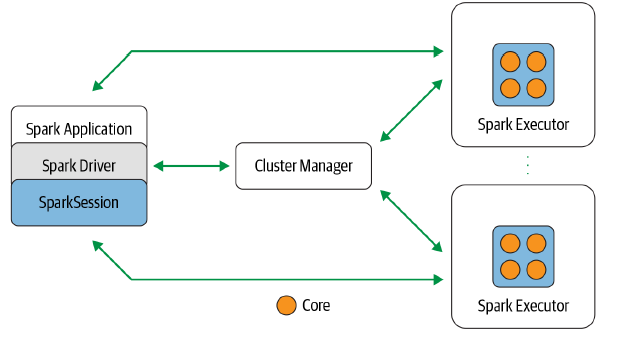
E é justamente neste momento que alguns termos cruciais na conjuntura de uso de Spark se fazem presentes:
| Elemento | Descrição |
| Spark Application | Uma aplicação Spark é basicamente um conjunto de elementos responsáveis por orquestrar toda a dinâmica de submissão do código escrito pelo usuário no cluster de computadores. É composta por um programa driver e uma série de programas chamados de executores. |
| Spark Driver | É o principal programa de uma aplicação Spark e é nele que o elemento de sessão SparkSession é criado. O driver é responsável por manter uma comunicação com o gerenciador do cluster para requisição de recursos computacionais (CPU, memória, etc), além de transformar as operações codificadas pelo usuário em DAGs a serem agendadas para os executores. |
| SparkSession | A partir do Spark 2.0, o elemento SparkSession atua como um ponto central de entrada para componentes antes utilizados individualmente e de maneira isolada (como SparkContext, SQLContext, HiveContext, SparkConf, entre outros). Com a sessão do Spark ativa, é possível definir DataFrames, Datasets, ler dados de diversas fontes, acessar o catálogo de metadados,executar queries SQL e muito mais. De maneira geral, a sessão é definida como um conduíte de entrada para todas as funcionalidades do Spark. |
| Spark Executors | São os responsáveis por executar toda a carga de trabalho direcionada pelo programa driver nos nós de trabalho (workers) do cluster de computadores. Além disso, os executores reportam o status da computação diretamente ao driver para que um melhor gerenciamento da aplicação possa ser aplicado. |
De forma alternativa, a imagem abaixo traz uma outra visão sobre esta mesma dinâmica exemplificada na tabela acima.
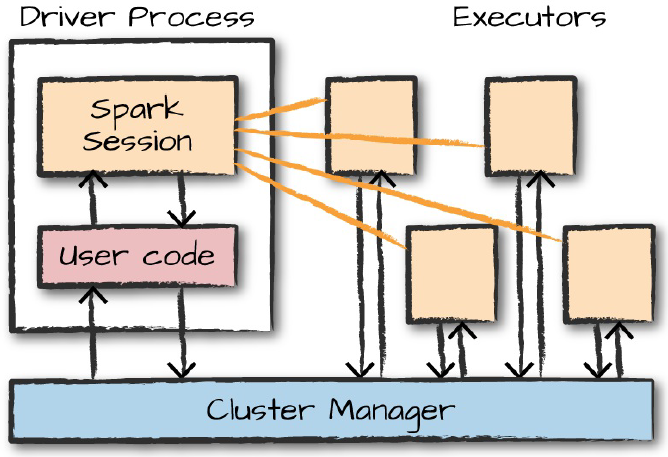
Em linhas gerais, uma aplicação Spark comporta uma série de elementos que, juntos, são responsáveis pela execução do código, orquestração do cluster e por todo o gerenciamento necessário para que os resultados sejam retornados ao usuário. Na visão do desenvolvedor, engenheiro ou cientista de dados, basta conhecer as formas de se trabalhar com tais elementos (principalmente a sessão SparkSession) em uma API estruturada (SparkSQL, Structured Streaming, MLlib ou GraphX) para programar processos, jobs ou qualquer atuação relevante do Spark.
Fato é que, no estado evolutivo em que o Spark se encontra atualmente, há uma boa abstração da dinâmica pesada de orquestração de elementos, o que oportuniza a seus usuários um uso direto de todo seu leque de ferramentas a partir de portas únicas de entradas em APIs estruturadas.
Conclusão e encerramento
Ainda sob um viés fortemente teórico, chega ao fim o segundo artigo sobre o Apache Spark. Por mais denso que o conteúdo aqui consolidado possa ter se apresentado ao leitor, é importante ressaltar que os conhecimentos demonstrados são de suma importância para que uma proficiência no uso do Spark seja adquirida futuramente. A partir destes tópicos, o usuário sentirá a confiança e terá a autonomia necessária para desenvolver suas próprias aplicações Spark utilizando um maravilhoso leque de recursos disponíveis em meio a toda esta dinâmica de funcionamento.
Nos próximos artigos, uma maior proximidade às atividades práticas de uso do Spark será alcançada e, até lá, tópicos como a instalação e configuração do Spark, distribuição de dados em um cluster de computadores e um foco na API estruturada SparkSQL com seus DataFrames e Datasets serão detalhados.
Foi ótimo ter você aqui, caro leitor! Até a próxima!




