




Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark!
Transformar dados em Spark através de suas APIs estruturadas é, sem dúvidas, uma ação fundamental dentro da dinâmica de construção de pipelines em cenários práticos de trabalho. Conhecer os métodos e funções aplicados garante uma autonomia sem precedentes para um verdadeiro mergulho na criação de produtos de dados na era do Big Data.
Entretanto, muito além da codificação da lógica de transformação e da estruturação das instruções em uma linguagem de programação de preferência, é essencialmente importante compreender os detalhes da implantação do pipeline criado em uma dinâmica prática de execução e gerenciamento em um cluster de computadores. Em outras palavras, isto significa subir de nível no que diz respeito à transformação de um código interativo e exploratório em uma verdadeira aplicação Spark capaz de retornar os resultados definidos em um cenário paralelo de processamento de dados.
Dessa forma, esta artigo tem a importante responsabilidade de proporcionar um contato inicial com o utilitário spark-submit como uma ferramenta built-in de linha de comando do Spark capaz de submeter os códigos construídos em um ambiente de produção de acordo com a instalação do Spark existente. Adicionalmente, serão abordados conceitos sobre scripting em Python visando a construção de códigos genuinamente eficientes capazes de serem submetidos como aplicações Spark.
O comando spark-submit
De forma objetiva, o comando spark-submit auxilia os usuários a executarem seus códigos e scripts em um cluster de computadores (ou uma simulação do mesmo, caso o Spark esteja instalado em seu modo local) como verdadeiras aplicações Spark. Em essência, uma aplicação submetida no cluster irá executar até que as tarefas (ou tasks) sejam terminadas ou até que um erro seja encontrado.
Os gerenciadores de clusters (YARN, Mesos) possuem um papel fundamental nesta dinâmica, visto que são eles os responsáveis por garantir os recursos necessários para que a aplicação seja devidamente executada da melhor forma possível.
Considerando uma instalação local do Spark, o utilitário spark-submit pode ser encontrado no diretório de binários presente no local de instalação do Spark. No exemplo abaixo, é possível visualizar uma listagem de todas as ferramentas de linha de comando presentes em uma instalação local do Spark:
ls $SPARK_HOME/bin
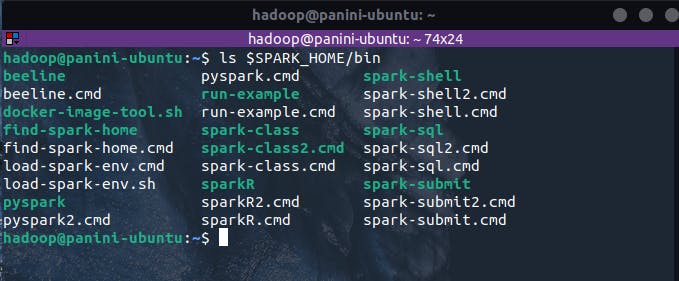
Em linha com todas as possibilidades existentes em um cenário de execução paralela em um cluster de computadores, o spark-submit oferece uma série de opções capazes de serem utilizadas para os mais variados propósitos, desde a especificação de classes auxiliares específicas até a configuração dos recursos a serem utilizados na execução da aplicação. Neste cenário, toda essa configuração pode ser especificada no ato da execução do utilitário como argumentos na linha de comando.
Por fim, o Spark proporciona alguns exemplos práticos em seu próprio diretório de instalação ($SPARK_HOME/examples/src/main), permitindo assim que códigos pré existentes possam ser executados pelo usuário utilizando o spark-submit. No exemplo abaixo, o código pi.py será submetido para execução visando retornar o número pi a um certo nível de precisão:
$SPARK_HOME/bin/spark-submit --master local $SPARK_HOME/examples/src/main/python/pi.py 10
Após algumas mensagens de log relacionadas à execução da aplicação, será possível visualizar, no próprio terminal, o resultado o número pi conforme a especificação do script:
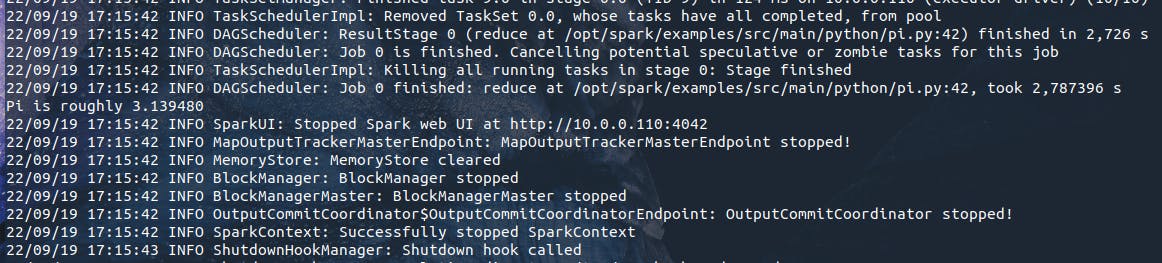
E assim, toda a lógica codificada em pi.py foi submetida para execução como uma aplicação Spark, tendo seu resultado retornado de acordo com as características do script e os argumentos passados pelo usuário. Contribuindo para um entendimento mais claro sobre este processo, a pergunta que se faz é: o que há dentro do código pi.py? Utilizando uma IDE ou um editor de texto, o bloco abaixo representa exatamente o script recém executado para o cálculo do número pi:
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_: int) -> float:
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
Sem a pretensão de entrar nos detalhes computacionais da lógica implementada, é extreamamente interessante visualizar uma aplicação Spark construída no formato de script. Na prática, é neste formato que os códigos exploratórios podem ser transformados para uma posterior execução em um cluster de computadores. Para compreender as particularidades deste processo, é fundamental ter uma noção básica sobre scripting.
O básico sobre a construção de scripts
Construir scripts em uma linguagem de programação é um processo que poderia tranquilamente ser abordado em múltiplos artigos. As possibilidades e as formas de aplicação são gigantescas! Considerando as variadas fontes de aprendizado disponíveis, duas grandes referências podem ser destacadas e consumidas pelos leitores para um mergulho aprofundado neste processo:
A grande verdade é que programadores e desenvolvedores estabelecem um estilo próprio para a criação de seus códigos com base em alguns padrões e boas práticas encontradas em referências didáticas ou mesmo vivenciadas em experiências práticas do dia a dia. Em linhas gerais, os códigos a serem demonstrados neste artigo para posterior submissão via spark-submit utilizam duas principais bibliotecas Python que facilitam a dinâmica de scripting:
| Biblioteca | Descrição |
sys | Permite o gerenciamento de argumentos em um script Python em um formato simples e direto. O método sys.argv possibilita o retorno de todos os argumentos passados em um formato de lista que pode, posteriormente, ser trabalhado, validado e utilizado ao longo do código. |
argparse | Possui um leque de funcionalidades relacionadas ao gerenciamento de argumentos em um script. Através de classes e métodos específicos (ArgumentParser() e add_argument(), por exemplo), é possível construir um objeto parser para obter e manusear os argumentos passados pelo usuário. |
Assim, para uma demonstração prática do poder de ambas as bibliotecas, o bloco de código abaixo pode ser utilizado para a criação de um script Python capaz de imprimir, na saída do sistema, um intervalo sequencial de números com limiar superior definido pelo usuário:
# Importando bibliotecas
import sys
import argparse
# Criando objeto para obtenção dos argumentos
parser = argparse.ArgumentParser(
prog=sys.argv[0],
usage="python script-teste.py <range>",
description="Imprime um intervalo sequencial de inteiros"
)
# Adicionando argumento: --range
parser.add_argument(
"-r", "--range",
dest="range",
type=int,
help="Número do limiar superior do intervalo a ser impresso",
required=True
)
# Coletando argumento
args = parser.parse_args()
# Criando programa principal
if __name__ == "__main__":
for i in range(args.range + 1):
print(i)
O código acima utiliza a classe ArgumentParser() da biblioteca argparse para a criação de um objeto capaz de gerenciar toda a dinâmica de argumentos do script. Através do método add_argument(), novos argumentos podem ser adicionados utilizando a notação completa (ex: --range) ou reduzida (ex: -r), além de proporcionar uma série de outras informações relevantes, como tipo primitivo, descrição de ajuda e o nome do atributo onde o argumento poderá posteriormente ser acessado no código. Por fim, o método parse_args() cria um objeto com as informações necessárias para a implementação da lógica do script. Este e outros detalhes estão presentes na documentação da biblioteca argparse fornecida anteriormente na tabela acima.
Assim, ao chamar o script da maneira adequada, o usuário poderá então visualizar o resultado especificado através dos números sequenciais:
python3 ./script-teste.py -r 10
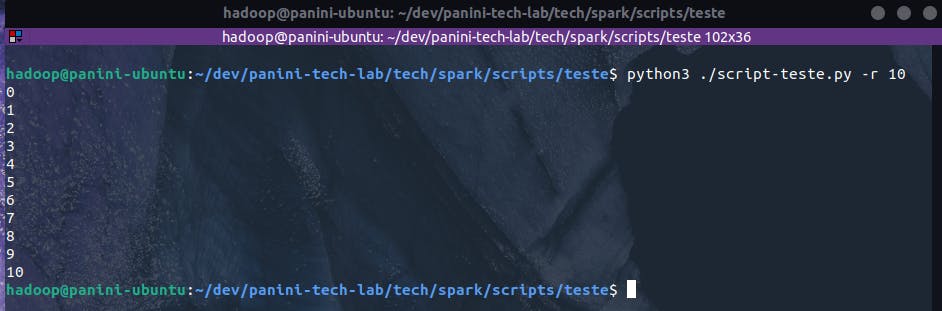
Existem uma série de outras possibilidades, padrões e boas práticas de criação de scripts em Python e, como informado previamente, para que todas as nuances deste processo pudessem ser devidamente abordadas, uma nova série de artigos específica para este assunto poderia ser criada. Com as referências fornecidas e, contando com a curiosidade do leitor aqui presente, este certamente não será um empecilho para as implementações futuras a serem apresentadas nos próximos tópicos.
A seguir, será proposta a construção completa de uma aplicação Spark a ser posteriormente executada em seu modo local, permitindo assim uma visão definitiva sobre o processo end to end de implantação de scripts em ambientes produtivos. O exemplo considera a criação de um código capaz de ler, transformar e escrever dados presentes no Amazon S3 em uma aplicação que simula a junção de múltiplas fontes de dados para a construção de uma tabela única particionada e armazenada no formato PARQUET.
Exemplo: criando uma tabela especializada no S3
Uma vez apresentado o spark-submit como uma ferramenta de linha de comando capaz de ser utilizada para submeter aplicações Spark em uma dinâmica de execução paralela em um cluster de computadores e, considerando também a abordagem dos tópicos sobre a criação de scripts em Python, é possível navegar em um exemplo realmente completo sobre a construção de uma primeira aplicação Spark a ser submetida em uma instância local do Spark presente em uma máquina virtual Linux.
Os objetivos desta aplicação giram em torno da utilização da API estruturada de DataFrames do Spark para a coleta de múltiplas fontes de dados contendo informações sobre vendas online (Brazilian E-Commerce), originalmente normalizadas através de chaves primárias e estrangeiras, e a subsequente desnormalização dos dados, gerando assim um conjunto único contendo uma série de atributos relacionados ao e-commerce brasileiro. Os dados brutos serão ingeridos no S3 para posterior leitura através de um script auxiliar. Após a leitura e especialização, a tabela final gerada será também escrita no S3 considerando uma partição mensal pela data da compra registrada.
Conforme informado, os dados originais estão presentes em múltiplos arquivos no formato CSV que se relacionam da seguinte maneira:
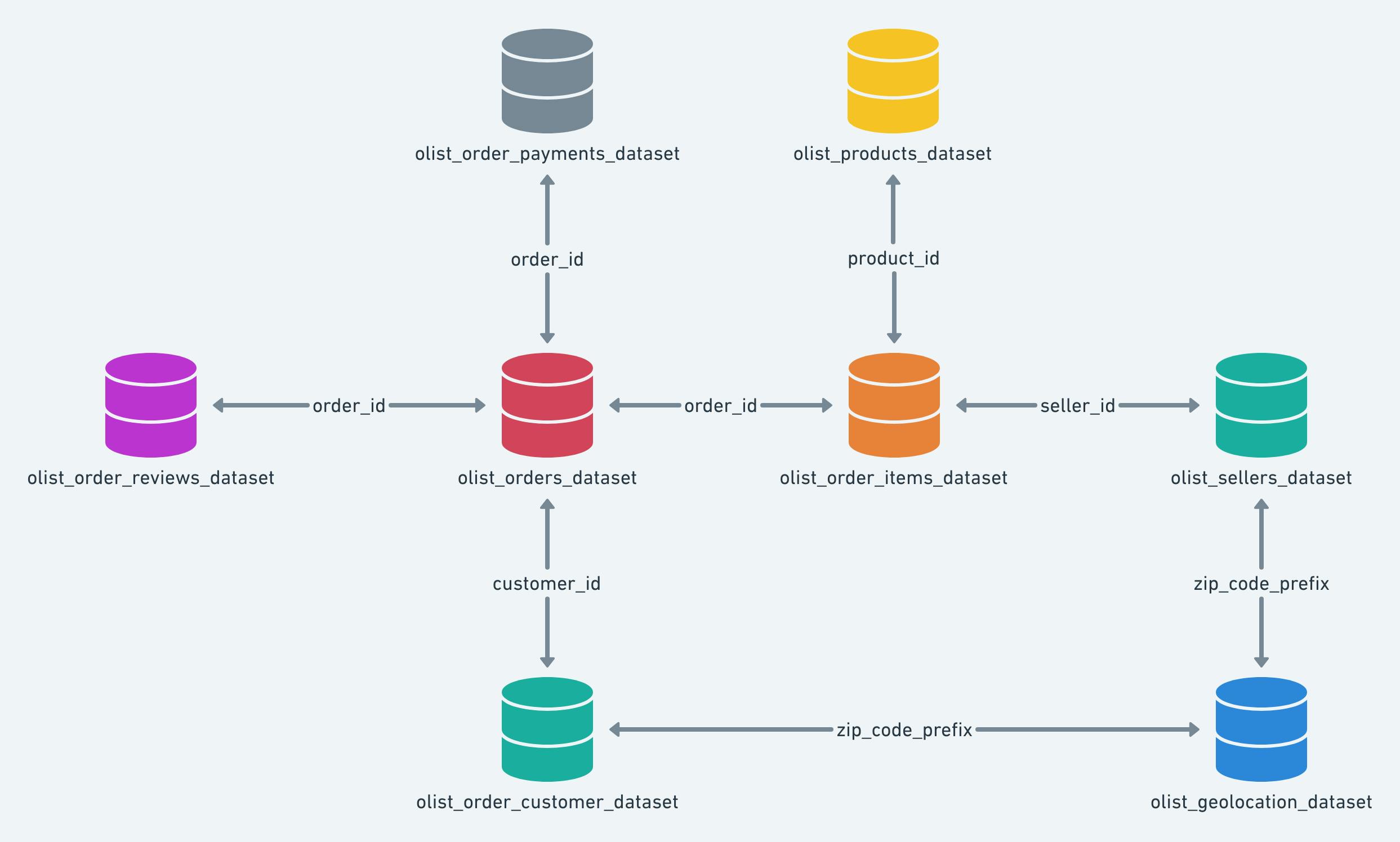
Considerando os objetivos propostos, será preciso realizar o upload destes arquivos em um formato familiar no S3 para a posterior leitura e transformação. Visualmente, toda a dinâmica estabelecida nesta seção está representada pelo diagrama abaixo:
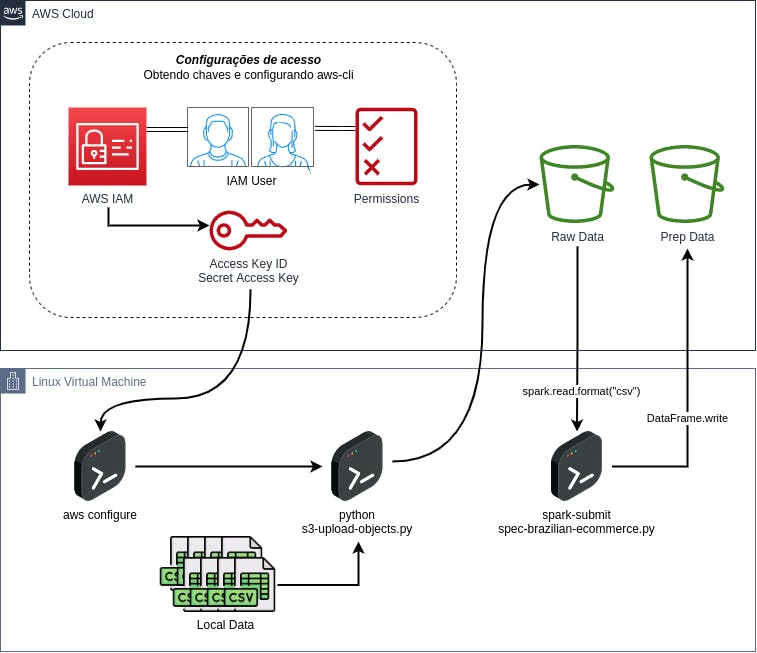
Assim, ao final de todo o processo, será possível visualizar, na prática, a execução de uma aplicação Spark capaz de ler dados do S3, transformá-los e, enfim, escrevê-los novamente no S3 como uma base especializada e particionada de acordo com os propósitos estabelecidos.
Subindo dados para o S3
De largada, alguns conceitos de scripting em Python serão aplicados em conjunto com a utilização do SDK boto3 para a construção de um código responsável por realizar o upload dos arquivos locais contendo os dados do E-Commerce brasileiro para um bucket S3 na AWS.
Como premissa, é importante que a conta AWS possua um bucket a ser utilizado como alvo do processo de upload. Além disso, o usuário owner das chaves de acesso inseridas e configuradas no AWS CLI via aws configure necessita ter acesso de escrita e leitura ao bucket alvo.
O script utilizado para este processo poderá ser visualizado no apêndice e possui os seguintes argumentos:
| Argumento | Descrição |
--path, -p | Diretório local onde os dados a serem inseridos no s3 estão armazenados |
--bucket, -b | Nome do bucket alvo do processo de escrita na AWS |
--bucket-prefix, -bp | Prefixo de folder no s3 para upload dos arquivos |
Assim, cumpridas as devidas exigências e, garantindo a correta inserção dos argumentos obrigatórios do script, o bloco de código abaixo realiza a execução do código para o upload de dados brutos no S3:
python3 s3-put-objects.py --path "../../../data/brazilian-ecommerce/" --bucket "datasets-729958084820-us-east-1" --bucket-prefix "brazilian-ecommerce"
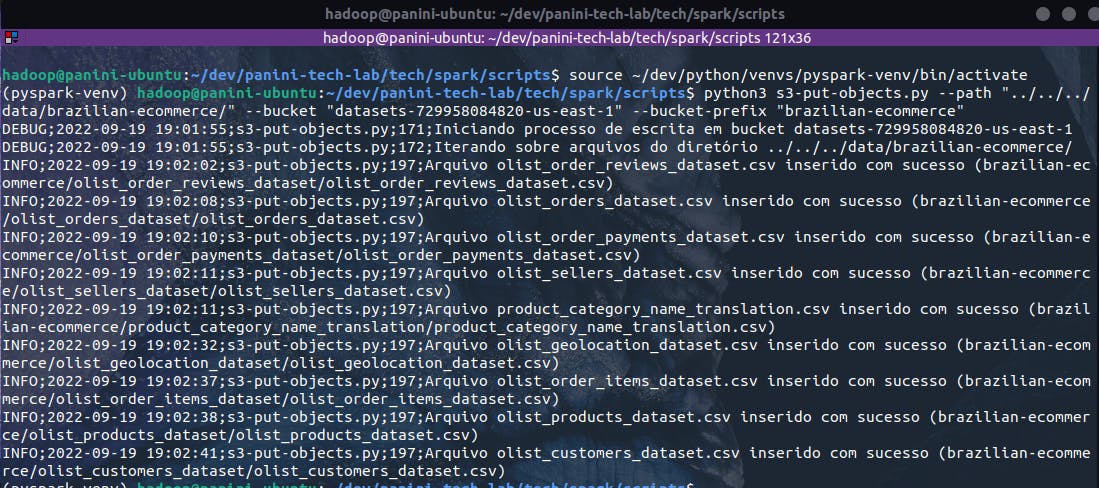
Ao acessar a conta AWS alvo do processo através do console, será possível identificar, em "bucket_name"/"bucket_prefix", um folder para cada base origem no seguinte formato:
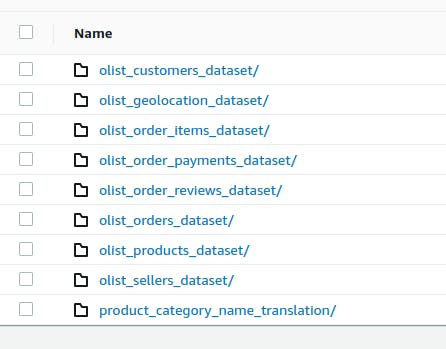
Neste momento, é importante citar que este script atua apenas como um facilitador para a inserção dos dados no ambiente alvo de trabalho do código em pyspark a ser demonstrado. Se a sua execução for um empecilho nesta etapa, o leitor pode inserir manualmente os arquivos seguindo o mesmo formato da imagem acima, podendo assim seguir tranquilamente com os próximos passos.
Gerando tabela especializada
Uma vez preparado o ambiente, é possível então iniciar as discussões sobre a aplicação Spark que, de fato, irá alocar toda a lógica de ETL aplicada aos dados de e-commerce para a construção de uma base desnormalizada contendo a junção de múltiplos atributos presentes em fontes distintas.
O script criado para esta etapa pode ser visualizado no apêndice do artigo e seu conteúdo considera uma série de argumentos, aos quais são detalhados na tabela abaixo:
| Argumento | Descrição |
--bucket, -b | Nome do bucket alvo do processo de leitura e escrita na AWS |
--input-prefix, -in | Prefixo de folder no s3 para leitura dos arquivos já existentes |
--output-prefix, -out | Prefixo de folder de saída no s3 para escrita dos dados gerados |
--format, -f | Formato do arquivo de saída |
--table-name, -t | Nome da tabela a ser considerada como um prefixo adicional no s3 |
Na lógica implementada, o script é composto por uma série de etapas que podem ser definidas em:
Preparação inicial do script
1.1 Importação das bibliotecas
1.2 Configuração do objeto logger
1.3 Coleta e validação dos argumentos
Programa principal
2.1 Criando e configurando SparkSession
2.2 Lendo objetos do s3 em DataFrames Spark
2.3 Cruzando e preparando dados
2.4 Criando coluna de partição da tabela
2.5 Escrevendo tabela final em bucket no s3
E assim, sua execução então pode ser realizada através do spark-submit configurando o argumento --master de acordo com a instalação do Spark existente (no caso do exemplo, o Spark local está sendo utilizado), além dos demais argumentos do script detalhados previamente:
spark-submit --master local ./spec-brazilian-ecommerce.py \
--bucket "datasets-729958084820-us-east-1" \
--input-prefix "brazilian-ecommerce" \
--output-prefix "output" \
--format "parquet" \
--table-name "tbl_spec_brazilian_ecommerce"
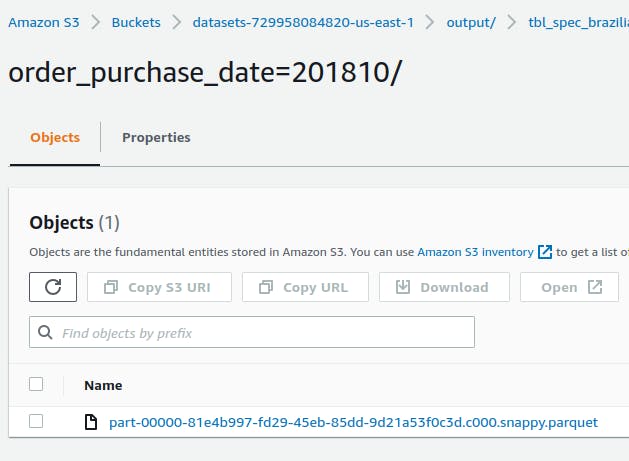
Como resultado, a base final gerada é particionada por mês de compra registrado na tabela de pedidos. Dessa forma, o resultado da aplicação considera a criação de múltiplas partições no S3 para cada mês de registro em um cenário exemplificado pela figura abaixo:
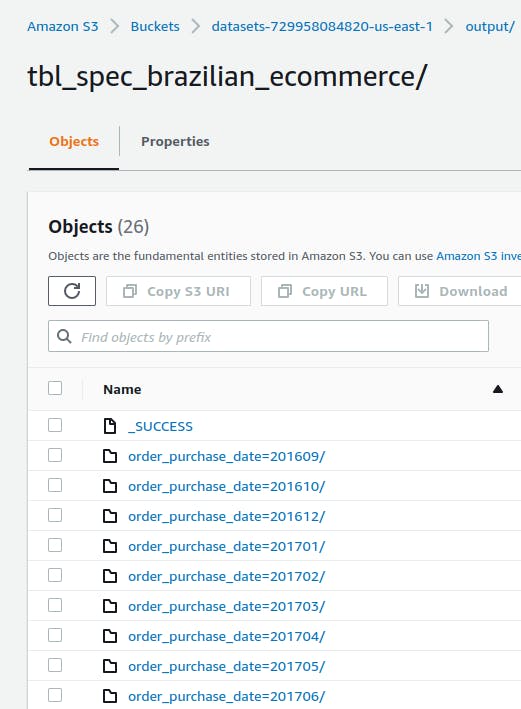
Cada partição contendo um ou mais arquivos no formato parquet (argumento --format inserido no script) e compressão SNAPPY (padrão do método DataFrame.write.format("parquet")) :
Conclusão e encerramento
Na jornada de aprendizado do Spark, além do conhecimento sobre as mais variadas formas de transformar dados, é essencialmente importante possuir uma clara noção sobre como implantar um pipeline de dados em um ambiente produtivo de trabalho. Neste artigo, alguns conceitos interessante sobre a criação de scripts em Python juntamente com a execução de uma aplicação Spark através do comando spark-submit foram demonstrados visando proporcionar, aos amantes desta ferramenta, algumas das melhores práticas para criação de aplicações eficientes na dinâmica de uso do Spark.
Existe, ainda, uma série de outros conceitos envolvendo detalhes técnicos de execução de uma aplicação Spark em um cluster de computadores, sendo este um conhecimento igualmente importante para alcançar uma completa autonomia no entendimento do Spark. A princípio, ter um primeiro contato com toda a dinâmica de transformação de um código exploratório em um script produtivo é a porta de entrada para assuntos gerenciais envolvendo a execução dos códigos de forma paralela.
Foi ótimo ter você aqui, caro leitor! até a próxima!
Apêndice: scripts criados
s3-upload-objects
"""
SCRIPT: s3-put-objects.py
CONTEXTO:
---------
Script criado para auxiliar o upload de arquivos locais
para um destino s3 especificado pelo usuário. O código
aqui alocado considera que o usuário tenha acesso
programático de escrita no bucket de destino, utilizando
como principal meio, o SDK boto3.
OBJETIVO:
---------
Proporcionar uma forma fácil, rápida e eficiente para
transferência de arquivos locais para um bucket s3 na
AWS, respeitando a hierarquia local de pastas existente.
TABLE OF CONTENTS:
------------------
1. Preparação inicial do script
1.1. Importação das bibliotecas
1.2. Configuração do objeto logger
1.3. Coleta e validação dos argumentos
2. Programa principal
2.1 Validando argumentos do script
2.2 Instanciando client s3 do boto3
2.3 Iterando sobre arquivos do diretório
------------------------------------------------------
------------------------------------------------------
---------- 1. PREPARAÇÃO INICIAL DO SCRIPT -----------
1.1. Importação das bibliotecas
---------------------------------------------------"""
# Importando bibliotecas
import sys
import argparse
import logging
import os
import boto3
"""---------------------------------------------------
---------- 1. PREPARAÇÃO INICIAL DO SCRIPT -----------
1.2. Configuração do objeto logger
---------------------------------------------------"""
# Instanciando objeto de logging
logger = logging.getLogger(__file__)
logger.setLevel(logging.DEBUG)
# Configurando formato das mensagens no objeto
log_format = "%(levelname)s;%(asctime)s;%(filename)s;"
log_format += "%(lineno)d;%(message)s"
date_format = "%Y-%m-%d %H:%M:%S"
formatter = logging.Formatter(log_format,
datefmt=date_format)
# Configurando stream handler do objeto de log
stream_handler = logging.StreamHandler()
stream_handler.setFormatter(formatter)
logger.addHandler(stream_handler)
"""---------------------------------------------------
---------- 1. PREPARAÇÃO INICIAL DO SCRIPT -----------
1.3. Definição e coleta dos argumentos
---------------------------------------------------"""
# Criando objeto para parse dos argumentos
parser = argparse.ArgumentParser(
prog=sys.argv[0],
usage="python s3-put-objects.py <local_path> <bucket_name>",
description="Script criado para auxiliar o upload de arquivos locais " +
"para um destino s3 especificado pelo usuário. O código " +
"aqui alocado considera que o usuário tenha acesso " +
"programático de escrita no bucket de destino, utilizando " +
"como principal meio, o SDK boto3."
)
# Adicionando argumento: --version
parser.add_argument(
"-v", "--version",
action="version",
version=f"{os.path.splitext(parser.prog)[0]} 0.1"
)
# Adicionando argumento: --path
parser.add_argument(
"-p", "--path",
dest="path",
type=str,
help="Diretório local onde os dados a serem inseridos " +
"no s3 estão armazenados",
required=True
)
# Adicionando argumento: --bucket
parser.add_argument(
"-b", "--bucket",
dest="bucket",
type=str,
help="Nome do bucket alvo do processo de escrita na AWS",
required=True
)
# Adicionando argumento: --bucket-prefix
parser.add_argument(
"-bp", "--bucket-prefix",
dest="bucket_prefix",
type=str,
default="",
help="Prefixo de folder no s3 para upload dos arquivos",
required=False
)
# Coletando argumentos do script
args = parser.parse_args()
"""---------------------------------------------------
--------------- 2. PROGRAMA PRINCIPAL ----------------
---------------------------------------------------"""
if __name__ == "__main__":
"""-----------------------------------------------
------------- 2. PROGRAMA PRINCIPAL --------------
2.1 Validando argumentos do script
-----------------------------------------------"""
# Validando diretório local
path_msg = f"Argumento --path ({args.path})"
try:
# Coletando informações do diretório
valid_path = os.path.isdir(args.path)
files_in_path = os.listdir(args.path)
except TypeError as te:
logger.error(f"{path_msg} inválido.")
raise te
except FileNotFoundError as fnf:
logger.error(f"{path_msg} aponta pra um diretório inexistente. " +
"Insira um diretório existente para upload dos arquivos.")
raise fnf
except NotADirectoryError as nade:
logger.error(f"{path_msg} não foi identificado como um diretório. " +
"Insira um diretório existente para upload dos arquivos.")
raise nade
"""-----------------------------------------------
------------- 2. PROGRAMA PRINCIPAL --------------
2.2 Instanciando client s3 do boto3
-----------------------------------------------"""
try:
s3_client = boto3.client("s3")
except Exception as e:
logger.error("Erro ao inicializar client s3 via boto3")
raise e
"""-----------------------------------------------
------------- 2. PROGRAMA PRINCIPAL --------------
2.3 Iterando sobre arquivos do diretório
-----------------------------------------------"""
# Iterando sobre diretório
logger.debug(f"Iniciando processo de escrita em bucket {args.bucket}")
logger.debug(f"Iterando sobre arquivos do diretório {args.path}")
for path, dirs, files in os.walk(args.path):
# Iterando sobre cada arquivo e realizando upload
for name in files:
# Preparando variáveis de destino no s3
file_prefix = os.path.splitext(name)[0]
if args.bucket_prefix != "":
bucket_prefix = args.bucket_prefix + "/" \
if args.bucket_prefix[-1] != "/" \
else args.bucket_prefix
# Montando chave de objeto
obj_key = bucket_prefix + file_prefix + "/" + name
# Montando caminho completo do arquivo local
filepath = os.path.join(path, name)
# Realizando upload de stream binária já em buffer
try:
with open(filepath, 'rb') as f:
s3_client.put_object(
Bucket=args.bucket,
Body=f,
Key=obj_key
)
logger.info(f"Arquivo {name} inserido com sucesso ({obj_key})")
except Exception as e:
logger.warning("Erro ao realizar upload via put_object() " +
f"de arquivo {filepath} no destino {obj_key} " +
f"em bucket {args.bucket}. Exception: {e}")
raise e
spec-brazilian-ecommerce
"""
SCRIPT: brazilian-ecommerce.py
CONTEXTO:
---------
Script criado para servir como um exemplo prático, eficiente
e completo dentro da jornada de aprendizado em Apache Spark
com pyspark em termos de submissão de aplicações para
um cluster de computadores (ou para o driver, em caso de
utilização do modo local do Spark).
OBJETIVO:
---------
Consolidar múltiplas fontes externas de dados contendo
informações sobre compras e atividades no cenário do
e-commerce brasileiro registrado pela empresa Olist,
permitindo assim a construção de um dataset completo,
não normalizado e com atributos suficientemente ricos
de modo a garantir análises eficientes em outras etapas
do fluxo analítico.
TABLE OF CONTENTS:
------------------
1. Preparação inicial do script
1.1 Importação das bibliotecas
1.2 Configuração do objeto logger
1.3 Coleta e validação dos argumentos
2. Programa principal
2.1 Criando e configurando SparkSession
2.2 Lendo objetos do s3 em DataFrames Spark
2.3 Cruzando e preparando dados
2.4 Criando coluna de partição da tabela
2.5 Escrevendo tabela final em bucket no s3
------------------------------------------------------
------------------------------------------------------
---------- 1. PREPARAÇÃO INICIAL DO SCRIPT -----------
1.1 Importação das bibliotecas
---------------------------------------------------"""
# Importando bibliotecas
import sys
import argparse
import logging
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import expr
import boto3
from warnings import filterwarnings
filterwarnings("ignore")
"""---------------------------------------------------
---------- 1. PREPARAÇÃO INICIAL DO SCRIPT -----------
1.2 Configuração do objeto logger
---------------------------------------------------"""
# Instanciando objeto de logging
logger = logging.getLogger(__file__)
logger.setLevel(logging.DEBUG)
# Configurando formato das mensagens no objeto
log_format = "%(levelname)s;%(asctime)s;%(filename)s;"
log_format += "%(lineno)d;%(message)s"
date_format = "%Y-%m-%d %H:%M:%S"
formatter = logging.Formatter(log_format,
datefmt=date_format)
# Configurando stream handler do objeto de log
stream_handler = logging.StreamHandler()
stream_handler.setFormatter(formatter)
logger.addHandler(stream_handler)
"""---------------------------------------------------
---------- 1. PREPARAÇÃO INICIAL DO SCRIPT -----------
1.3 Definição e coleta dos argumentos
---------------------------------------------------"""
# Criando objeto para parse dos argumentos
parser = argparse.ArgumentParser(
prog=sys.argv[0],
usage="spark-submit spec-brazilian-ecommerce.py <bucket_name>",
description="Script responsável por realizar a " +
"leitura de dados contendo informações sobre o " +
"e-commerce brasileiro para a criação de um " +
"dataset escalável utilizando a API estruturada " +
"de DataFrames do Spark via pyspark"
)
# Adicionando argumento: --version
parser.add_argument(
"-v", "--version",
action="version",
version=f"{os.path.splitext(parser.prog)[0]} 0.1"
)
# Adicionando argumento: --bucket
parser.add_argument(
"-b", "--bucket",
dest="bucket",
type=str,
help="Nome do bucket alvo do processo de leitura e escrita",
required=True
)
# Adicionando argumento: --input-prefix
parser.add_argument(
"-in", "--input-prefix",
dest="input_prefix",
type=str,
default="brazilian-ecommerce",
help="Prefixo de folder no s3 para leitura dos arquivos",
required=False
)
# Adicionando argumento: --output-prefix
parser.add_argument(
"-out", "--output-prefix",
dest="output_prefix",
type=str,
default="output",
help="Prefixo de folder no s3 para escrita dos arquivos",
required=False
)
# Adicionando argumento: --format
parser.add_argument(
"-f", "--format",
dest="format",
type=str,
default="parquet",
help="Formato do arquivo final a ser armazenado no s3",
required=False
)
# Adicionando argumento: --table-name
parser.add_argument(
"-t", "--table-name",
dest="table_name",
type=str,
default="tbl_spec_brazilian_ecommerce",
help="Nome da 'tabela' final a ser armazenada no s3",
required=False
)
# Coletando argumentos do script
args = parser.parse_args()
if __name__ == "__main__":
"""-----------------------------------------------
------------- 2. PROGRAMA PRINCIPAL --------------
2.1 Criando e configurando SparkSession
-----------------------------------------------"""
logger.debug("Criando objeto de sessão spark")
try:
spark = SparkSession\
.builder\
.appName(__file__)\
.getOrCreate()
except Exception as e:
logger.error("Erro ao criar objeto de sessão spark")
raise e
# Criando sessão do boto3 para coleta das credenciais
session = boto3.Session()
credentials = session.get_credentials()
frozen_credentials = credentials.get_frozen_credentials()
access_key = frozen_credentials.access_key
secret_key = frozen_credentials.secret_key
# Configurando contexto para integração com AWS
spark._jsc.hadoopConfiguration().set("fs.s3a.access.key", access_key)
spark._jsc.hadoopConfiguration().set("fs.s3a.secret.key", secret_key)
spark._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "s3.amazonaws.com")
"""-----------------------------------------------
------------- 2. PROGRAMA PRINCIPAL --------------
2.2 Lendo objetos do s3 em DataFrames Spark
-----------------------------------------------"""
# Corrigindo prefixo de entrada, se necessário
if args.input_prefix != "":
input_prefix = args.input_prefix + "/" \
if args.input_prefix[-1] != "/" \
else args.input_prefix
# Corrigindo prefixo de saída, se necessário
if args.output_prefix != "":
output_prefix = args.output_prefix + "/" \
if args.output_prefix[-1] != "/" \
else args.output_prefix
# Definindo caminhos de entrada e saída no s3
s3_input_path = f"s3a://{args.bucket}/{input_prefix}"
s3_output_path = f"s3a://{args.bucket}/{output_prefix}/{args.table_name}"
# Criando dicionário de caminhos a partir de entrada no s3
s3_key_dict = {
"customers": "olist_customers_dataset/olist_customers_dataset.csv",
"items": "olist_order_items_dataset/olist_order_items_dataset.csv",
"pay": "olist_order_payments_dataset/olist_order_payments_dataset.csv",
"orders": "olist_orders_dataset/olist_orders_dataset.csv",
"products": "olist_products_dataset/olist_products_dataset.csv",
"sellers": "olist_sellers_dataset/olist_sellers_dataset.csv"
}
# Inserindo informação de protocolo e bucket de entrada
s3_input_list = [s3_input_path] * len(s3_key_dict)
s3_input_zip = zip(s3_key_dict.keys(), s3_key_dict.values(), s3_input_list)
s3_input_dict = {k: p + v for k, v, p in s3_input_zip}
# Lendo DataFrame: customers
try:
logger.debug("Realizando a leitura de DataFrame: customers")
df_customers = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load(s3_input_dict["customers"])
except Exception as e:
logger.error("Erro ao realizar a leitura do DataFrame: customers")
raise e
# Lendo DataFrame: customers
try:
logger.debug("Realizando a leitura de DataFrame: items")
df_order_items = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load(s3_input_dict["items"])
except Exception as e:
logger.error("erro ao realizar a leitura do DataFrame: items")
raise e
# Lendo DataFrame: payments
try:
logger.debug("Realizando a leitura de DataFrame: payments")
df_order_payments = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load(s3_input_dict["pay"])
except Exception as e:
logger.error("Erro ao realizar a leitura do DataFrame: payments")
raise e
# Lendo DataFrame: orders
try:
logger.debug("Realizando a leitura de DataFrame: orders")
df_orders = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load(s3_input_dict["orders"])
except Exception as e:
logger.error("Erro ao realizar a leitura do DataFrame: orders")
raise e
# Lendo DataFrame: products
try:
logger.debug("Realizando a leitura de DataFrame: products")
df_products = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load(s3_input_dict["products"])
except Exception as e:
logger.error("Erro ao realizar a leitura do DataFrame: products")
raise e
# Lendo DataFrame: sellers
try:
logger.debug("Realizando a leitura de DataFrame: sellers")
df_sellers = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load(s3_input_dict["sellers"])
except Exception as e:
logger.error("Erro ao realizar a leitura do DataFrame: sellers")
raise e
logger.info(f"Todos os {len(s3_input_dict)} objetos foram lidos com " +
f"sucesso do bucket {args.bucket}")
"""-----------------------------------------------
------------- 2. PROGRAMA PRINCIPAL --------------
2.3 Cruzando e preparando dados
-----------------------------------------------"""
logger.debug("Aplicando cruzamento dos dados para geração de tabela única")
# Cruzando dados: pedidos e pagamentos
df_ord_pay = df_orders.join(
other=df_order_payments,
how="left",
on=[df_orders.order_id == df_order_payments.order_id]
).drop(df_order_payments.order_id)
# Cruzando dados: pedidos, pagamentos e clientes
df_ord_pay_cust = df_ord_pay.join(
other=df_customers,
how="left",
on=[df_ord_pay.customer_id == df_customers.customer_id]
).drop(df_customers.customer_id)
# Cruzando dados: pedidos, pagamentos, clientes e itens
df_ord_pay_cust_items = df_ord_pay_cust.join(
other=df_order_items,
how="left",
on=[df_ord_pay_cust.order_id == df_order_items.order_id]
).drop(df_order_items.order_id)
# Cruzando dados: pedidos, pagamentos, clientes, itens e produtos
df_ord_pay_cust_items_prod = df_ord_pay_cust_items.join(
other=df_products,
how="left",
on=[df_ord_pay_cust_items.product_id == df_products.product_id]
).drop(df_products.product_id)
# Cruzando dados: pedidos, pgtos, clientes, itens, produtos e vendedores
df_ecommerce_join = df_ord_pay_cust_items_prod.join(
other=df_sellers,
how="left",
on=[df_ord_pay_cust_items_prod.seller_id == df_sellers.seller_id]
).drop(df_sellers.seller_id)
"""-----------------------------------------------
------------- 2. PROGRAMA PRINCIPAL --------------
2.4 Criando coluna de partição da tabela
-----------------------------------------------"""
logger.debug("Adicionando coluna de partição como a data do pedido")
# Adicionando coluna de partição
partition_expr = "date_format(order_purchase_timestamp, 'yyyyMM')"
df_ecommerce_spec = df_ecommerce_join.selectExpr(
"order_id",
"customer_id",
"order_status",
"order_purchase_timestamp",
"order_approved_at",
"order_delivered_carrier_date",
"order_delivered_customer_date",
"order_estimated_delivery_date",
"payment_sequential",
"payment_type",
"payment_installments",
"payment_value",
"customer_unique_id",
"customer_zip_code_prefix",
"customer_city",
"customer_state",
"order_item_id",
"product_id",
"seller_id",
"shipping_limit_date",
"price",
"freight_value",
"product_category_name",
"product_name_lenght",
"product_description_lenght",
"product_photos_qty",
"product_weight_g",
"product_length_cm",
"product_height_cm",
"product_width_cm",
"seller_zip_code_prefix",
"seller_city",
"seller_state"
).withColumn("order_purchase_date", expr(partition_expr))
"""-----------------------------------------------
------------- 2. PROGRAMA PRINCIPAL --------------
2.5 Escrevendo tabela final em bucket no s3
-----------------------------------------------"""
logger.debug(f"Salvando dados em bucket {args.bucket}")
# Executando comando
df_ecommerce_spec.write.format(args.format)\
.partitionBy("order_purchase_date")\
.save(s3_output_path)
# Encerrando sessão
spark.stop()