

Instalação e Primeiros Passos

Olá, caro leitor! Seja muito bem vindo a mais um post desta indispensável série sobre Apache Spark que está, aos poucos, ganhando nossos inquietos corações preenchidos pelo anseio do saber! De maneira muito animada, já é possível dizer que o conhecimento adquirido até o momento possui uma grande solidez literária. As raízes criadas permitem dar um passo fundamental para a primeira exploração prática do Spark.
Para tal, este artigo irá consolidar detalhes técnicos sobre as diferentes formas de utilizar o Spark, permitindo assim um entendimento claro sobre os diferentes cenários de uso do Spark e iniciar, de fato, sua exploração prática. No limite, tópicos como os modos de instalação do Spark, spark-shell, pyspark e SparkSession serão abordados em detalhes nas próximas seções. Aperte os cintos!
Modos de instalação e uso do Spark
No artigo anterior desta série, a primeira cortina do palco foi aberta e uma ilustração mais detalhada do funcionamento do Spark em aplicações reais de dados pôde ser visualizada. Com isso, uma relevante introdução sobre os acontecimentos presentes após a criação e submissão de aplicações Spark foi registrada como mais um bloco fundamental de conhecimento nessa ferramenta.
Assim, sabendo exatamente os bastidores de uma aplicação Spark e sua integração com um cluster de computadores, é chegado o momento de começar os ensaios. Para isso, o primeiro ato proposto gira em torno do entendimento dos diferentes modos de instalação do Spark em cenários reais de uso. A tabela abaixo detalha 5 maneiras de utilizar o Spark e, para cada uma, especificidades dos processos driver, executors e o cluster manager são fornecidos para uma visualização mais clara das principais diferenças:
| Modo | Spark driver | Spark executor | Cluster manager |
| Local | Executado em uma única JVM, como um notebook ou um nó individual | Executado na mesma JVM que o driver | Executado no mesmo host |
| Standalone | Pode ser executado em qualquer nó do cluster | Cada nó no cluster irá lançar seu próprio executor na JVM | Pode ser alocado arbitrariamente em qualquer nó do cluster |
| YARN (client) | Executado em um client, mas não parte do cluster | Container do Node Manager do YARN | O Resource Manager do YARN trabalha com o Application Master para alocação de containers nos Node Managers para os executores |
| YARN (cluster) | Executado com o YARN Application Master | Mesmo do YARN no modo client | Mesmo do YARN modo client |
| Kubernetes | Executado em um pod do Kubernetes | Cada worker executa seu próprio pod | Kubernetes Master |
Para fins didáticos e, visando uma maior facilidade nas demonstrações em Spark a serem compartilhadas, o modo "Local" de instalação será escolhido como alvo.
Instalando o Spark no Modo Local
De forma direta, a instalação do Spark em seu modo local gira em torno da obtenção dos binários (arquivo compactado) do site oficial, seguido da descompactação e a configuração das variáveis de ambiente. Na imagem abaixo, um diagrama exemplifica a instalação do Spark em uma máquina virtual Ubuntu com destaque à instalação do Java como principal dependência (afinal, mesmo no modo local, uma JVM será a responsável por processar a aplicação).
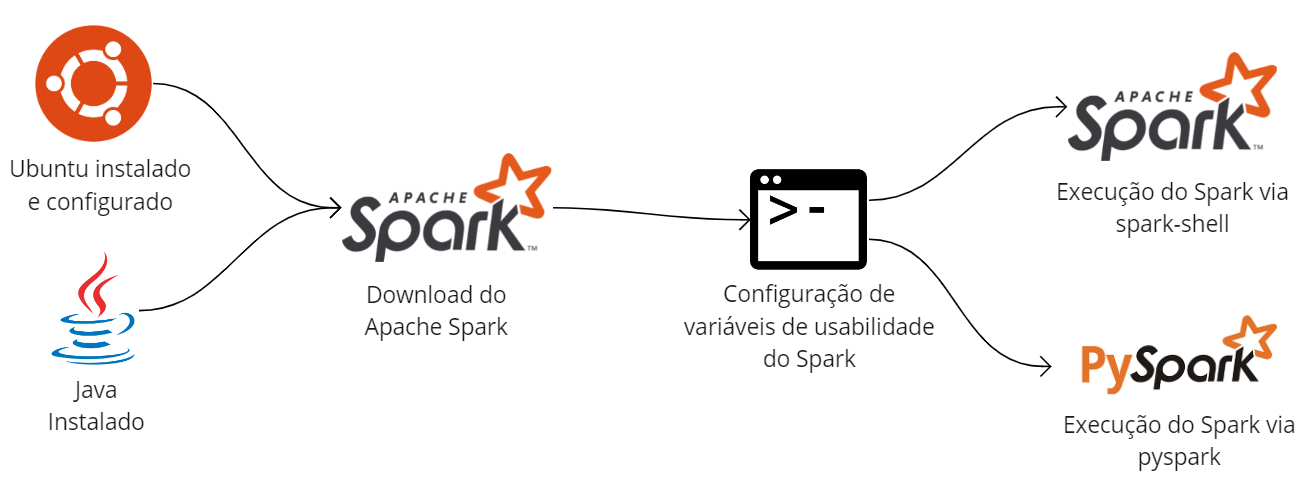
Por outro lado, considerando o uso do Spark junto ao Python, é possível realizar o download da biblioteca pyspark no ambiente virtual de escolha (ou mesmo no próprio executável Python do sistema) para usufruir de suas funcionalidades. Como dica adicional, o usuário poderá instalar o Jupyter Notebook de modo a facilitar seu aprendizado em um ambiente com possibilidades dinâmicas. A imagem abaixo ilustra o processo de obtenção do Spark para uso exclusivo com Python.
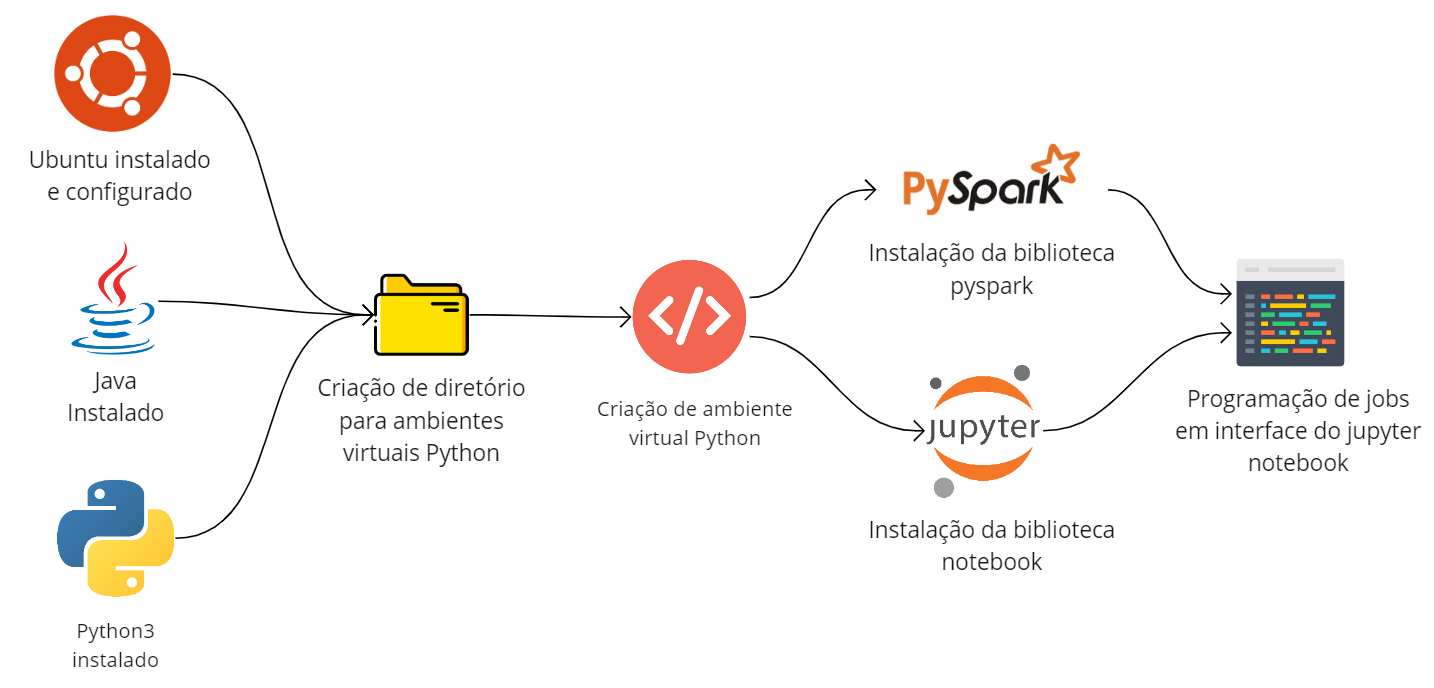
Afinal, qual escolher? Depende do seu propósito. Na verdade, não há uma necessidade de escolha neste momento e tampouco o download dos binários do Spark impede de também ter um ambiente virtual Python para uso do pyspark. Neste caso, seguir os passos de ambos os diagramas pode ser a escolha mais completa.
Como um exemplo prático, o bloco de código abaixo é responsável por criar um ambiente virtual Python isolado com a subsequente instalação dos pacotes pyspark e notebook para utilização do Spark através de um Jupyter Notebook.
# Criando e acessando ambiente virtual python
python3 -m venv pyspark_venv
source pyspark_venv/bin/activate
# Atualizando gerenciador de pacotes pip
pip install pip --upgrade
# Instalando pyspark e jupyter notebook
pip install pyspark notebook
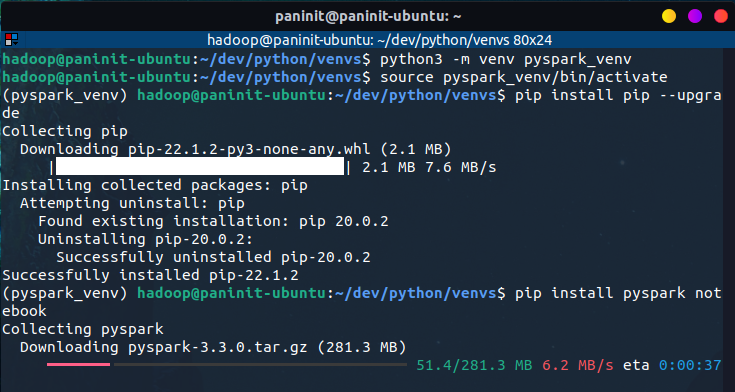
Após a conclusão do processo, é possível inicializar o jupyter notebook pelo terminal e, em seu interior, utilizar o pyspark para a criação do elemento SparkSession e a subsequente interação com suas APIs estruturadas.
Primeiro contato via shells interativas
Uma vez instalado o Spark e configurado as variáveis de ambiente do sistema, o tão aguardado primeiro contato com o framework pode ser obtido através do próprio terminal ao inserir o seguinte comando:
spark-shell
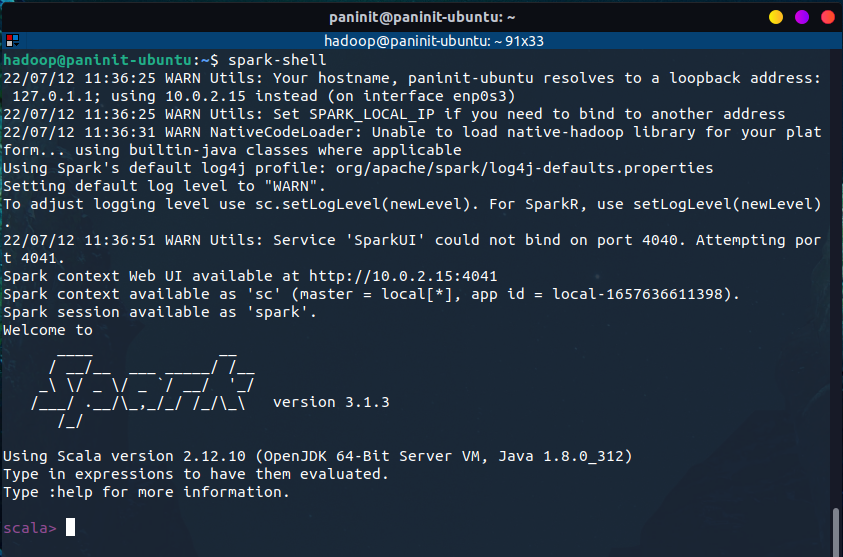
Neste caso, o comando executado permite acessar o Spark através de um console que utiliza a linguagem Scala. Para utilizá-lo com Python, basta executar o seguinte comando no terminal:
pyspark
O resultado é muito semelhante ao anterior, com a diferença de que, agora, o uso do Spark está pautado pela utilização da linguagem Python.
Este tipo de inicialização é possível pois o Spark possui uma série de shells interativas que funcionam como interpretadores para habilitar análises ad-hoc. Em um comparativo com alguns motores de consulta do Hadoop, seria análogo comparar as shells interativas do Spark com o beeline ou o impala-shell. No limite, são eles:
| Shell | Uso |
spark-shell | Utilização do Spark através da linguagem Scala |
pyspark | Utilização do Spark através da linguagem Python |
sparkR | Utilização do Spark através da linguagem R |
spark-sql | Utilização do Spark através da linguagem SQL |
Uma observação importante a ser feita diz respeito às configurações das variáveis de ambiente para a devida chamada dos comandos sem a necessidade de navegar até a pasta de binários do Spark. Caso este processo não tenha sido realizado, o sistema operacional não reconhecerá os comando acima exemplificados, resultando assim em um erro. Como uma alternativa às configurações das variáveis de ambiente, é possível navegar até o diretório dos binários do Spark no arquivo já descompactado e executar o comando (ex: /opt/spark/bin/pyspark para instalação do Spark no diretório /opt/spark).
Por mais que sejam considerados comandos distintos para utilização do Spark em diferentes linguagens, todos eles tem algo em comum: ao executar qualquer uma das shells interativas, uma sessão Spark é criada automaticamente para o usuário e se torna acessível através do objeto spark.
>>> spark
<pyspark.sql.session.SparkSession object at 0x7f3491b4af40>
Isto é altamente relevante pois, ao desenvolver uma aplicação Spark em um script Python ou em um Jupyter Notebook, por exemplo, o objeto SparkSession precisa necessariamente ser criado pelo usuário para, assim, obter todas as funcionalidades das APIs estruturadas. Como o objetivo das shells interativas é justamente facilitar o uso do Spark para análises pontuais, este trabalho já é realizado por padrão.
Codificando no Spark
Neste momento, é possível celebrar um primeiro contato com o Spark utilizando alguns de suas shells interativas, permitindo uma exploração inicial que, até pouco tempo atrás, soava distante. Utilizando o pyspark e uma sessão ativa, o código abaixo pode ser utilizado para criar uma simples coleção de números:
# Criando o primeiro DataFrame
data = spark.range(1000).toDF("number")
data.show(5)
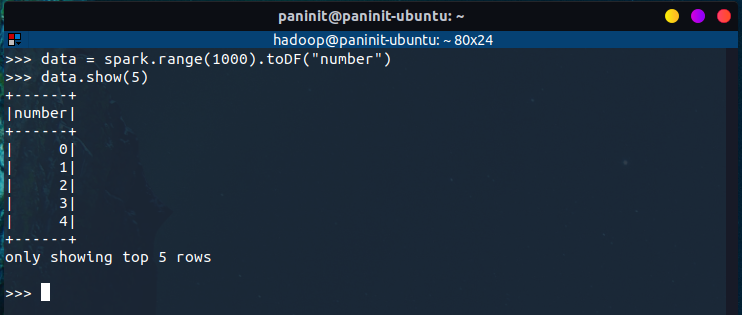
E, por mais simples que possa parecer, essa foi a primeira aplicação Spark escrita nesta série! De forma minuciosamente detalhada, os passos realizados foram:
- Criação de um intervalo de valores de 0 a 1000 através do método
range(n) - Criação de um objeto do tipo Spark DataFrame através do método
toDF() - Execução de uma ação para mostrar as 5 primeiras linhas do objeto através do método
show(n)
Sob uma ótica técnica, o intervalo de números criados representa uma coleção distribuída no Spark. Quando executava no cluster, cada parte deste intervalo existe em um executor diferente. Isto é um Spark DataFrame e detalhes adicionais sobre este indispensável elemento serão fornecidos em artigos posteriores desta série.
PySpark no Jupyter Notebook
Como uma demonstração final, será proposta a utilização de uma das APIs estruturadas do Spark através do Jupyter Notebook em um ambiente virtual previamente configurado em um processo já evidenciado neste mesmo artigo. Para tal,
basta ativar o ambiente virtual criado e inicializar o Jupyter Notebook através da execução comando jupyter notebook no terminal.
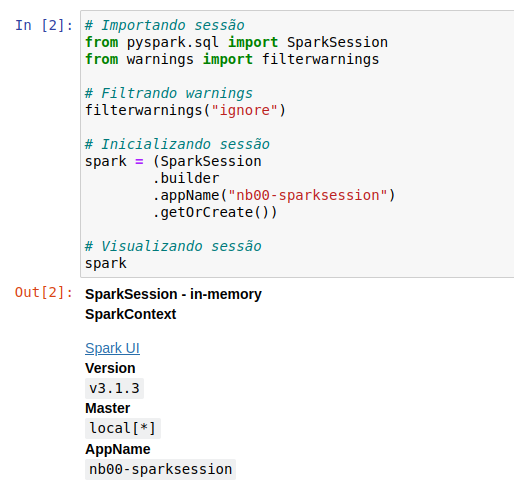
Com o notebook inicializado, insira o seguinte código para importar o objeto SparkSession do módulo pyspark.sql e inicializar uma sessão.
# Importando sessão
from pyspark.sql import SparkSession
# Inicializando sessão
spark = (SparkSession
.builder
.appName("nb00-sparksession")
.getOrCreate())
Conclusão e Encerramento
A evolução geral é nítida: mesmo em seu terceiro artigo, a série sobre o Spark já abordou conteúdos altamente relevantes para o uso da ferramenta em cenários de Big Data. Como passo mais recente, foi possível detalhar todo o processo de obtenção do Spark em cenários que poderão facilitar o aprendizado de seus usuários nesta longa jornada.
De fato, o Spark é uma ferramenta extremamente dinâmica e plural. Isto significa que existem diferentes formas de utilizá-lo de acordo com tópicos mais familiares a seus usuários. Python, Scala, R e SQL estão nativamente presentes através de shells interativas prontos para serem utilizados.
E assim, com o primeiro passo do uso prático do Spark fornecido, um outro conceito extremamente importante se fez notar: os DataFrames. Nos próximos artigos, as coleções distribuídas no Spark serão apresentadas em uma maior riqueza de detalhes para que, de uma maneira geral, seja possível compreender não só como programar em Spark utilizando seus objetos, métodos e funções, mas também obter um valioso entendimento sobre como os dados (o principal insumo de tudo o que está sendo tratado aqui) estão armazenados, distribuídos e localizados em toda essa dinâmica computacional.
Foi ótimo ter você aqui, caro leitor! Até a próxima!




