

Cruzando Dados com Joins

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! No último artigo publicado, foi possível navegar em múltiplas funções de agregação capazes de serem utilizadas na construção de conjuntos agregados de dados. No universo analítico, este é conhecimento altamente relevante responsável por habilitar uma série de funcionalidades adicionais aos usuários.
Entretanto, na prática, jobs e fluxos de trabalho envolvendo a transformação de dados em Spark fatalmente serão compostos por duas ou mais fontes de dados que, analisadas em conjunto através de algum meio de "junção" das respectivas informações, contemplam objetivos específicos na visão de protudos de dados. Assim, a junção de DataFrames se faz presente como uma forma de "cruzar" diferentes origens em uma estrutura única através de uma chave comum e uma operação lógica.
Curioso para saber a sintaxe exatada para aplicação de joins no Spark? Embarque nesta jornada!
Dados para exploração
Para os acompanhantes assíduos desta série, já é sabido que a primeira seção de quase todos os artigos aqui publicados envolve a declaração do conjunto de dados a ser utilizado na exploração de exemplos práticos. Considerando o objetivo do atual artigo, existe uma exigência implícita na utilização de múltiplos conjuntos de dados. Afinal, seria um pouco mais complicado demonstrar exemplos de cruzamento de bases com uma única coleção.
Dessa forma, aproveitando o contexto para trazer à tona o processo completo de um fluxo de trabalho em Spark, o bloco de código abaixo pode ser utilizado para importação das bibliotecas necessárias, criação de um objeto SparkSession e posterior leitura de três bases de dados (armazenadas em objetos do tipo DataFrame) contendo informações específicas sobre vôos retirados do Bureau americano.
# Importando bibliotecas
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, expr
import os
# Criando objeto de sessão
spark = SparkSession\
.builder\
.appName("joins-spark")\
.getOrCreate()
# Definindo variáveis de diretório
home_path = os.path.expanduser("~")
data_path = os.path.join(home_path, "dev/panini-tech-lab/data")
flights_path = os.path.join(data_path, "flights-data")
# Definindo variáveis para leitura de arquivos
summary_path = os.path.join(flights_path, "summary-data/csv/2015-summary.csv")
airports_codes_path = os.path.join(flights_path, "airport-codes-na/airport-codes-na.txt")
departure_delay_path = os.path.join(flights_path, "departure-delays/departuredelays.csv")
# Realizando a leitura dos dados de sumário
df_flights = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(summary_path)
# Realizando a leitura de depara de códigos de aeroportos
df_air_codes = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.option("sep", "\t")\
.load(airports_codes_path)
# Realizando a leitura de dados de partida de vôos
df_departure = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(departure_delay_path)
Cada base lida possui informações específicas que podem ser combinadas para análises detalhadas sobre vôos realizados nos Estados Unidos. Para proporcionar uma visão mais específica neste âmbito, os blocos de código abaixo e suas subsequentes ilustrações podem ser utilizadas como referência para um entendimento mais claro sobre os dados:
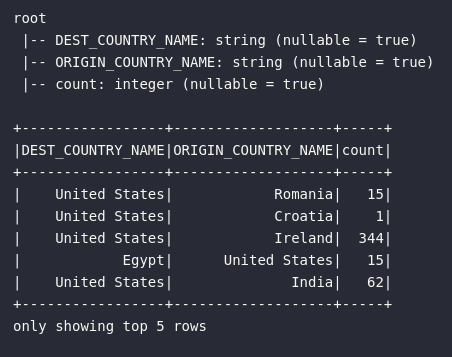
# Visualizando dados de resumo
df_flights.printSchema()
df_flights.show(5)
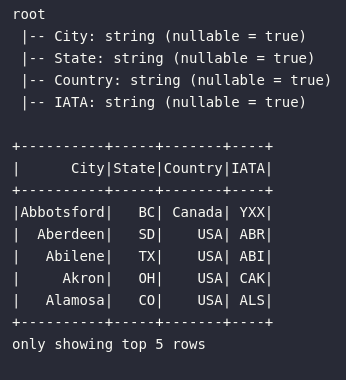
# Visualizando dados de aeroportos
df_air_codes.printSchema()
df_air_codes.show(5)
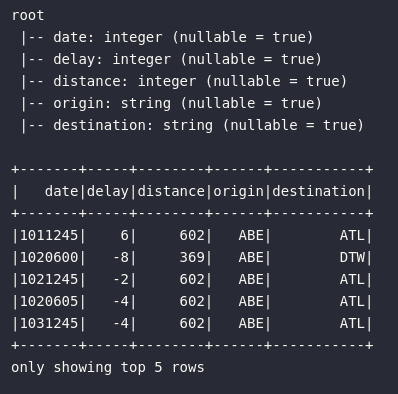
# Visualizando dados de saídas de vôos
df_departure.printSchema()
df_departure.show(5)
Em resumo, cada um dos três objetos DataFrames lidos em memória representa um contexto específico relacionado à vôos. A grande ideia por trás dos exemplos práticos a serem demonstrados neste artigo envolve o cruzamento destes objetos de modo a enriquecer dados e gerar novas coleções capazes de responder questões estratégicas impossíveis de serem alcançadas observando apenas as bases individualmente. Neste caso, os detalhes de cada DataFrame são:
| DataFrame | Descrição |
df_flights | Contabilização de vôos americanos em uma relação de origem e destino. Cada registro deste DataFrame representa a quantidade de vôos realizados de uma origem para um determinado destino. |
df_air_codes | Tabela auxiliar contendo os códigos de cada aeroporto e suas respectivas informações geográficas. A informação sobre o código do aeroporto está armazenada na coluna IATA. |
df_departure | Informações sobre registros de saídas de cada vôo considerando uma origem e um destino. |
E assim, com a plena compreensão sobre os dados a serem utilizados nos exemplos práticos e, já neste momento, possuindo uma ideia clara sobre as possibilidades a serem abordadas dentro do cenário de cruzamento de informações, é possível mergulhar a fundo em conceitos mais práticos sobre joins em Spark.
Tipos de joins
A aplicação de joins é uma tarefa existente há muito tempo em processamento e enálise de dados e, independente da linguagem ou ferramenta utilizada, é comum encontrar uma série de opções disitntas para cruzamento de dados.
No âmbito específico do Spark, as opções de joins são descritas através da tabela abaixo:
| Opção de Join (Spark) | Atuação |
inner | Mantém registros com a chave existente em ambos os conjuntos da esquerda e da direita |
left ou left_outer | Mantém registros com a chave existente apenas no conjunto da esquerda |
right ou right_outer | Mantém registros com a chave existente apenas no conjunto da direita |
left_semi | Mantém registros onde a chave existe em ambos os conjuntos da esquerda e da direita, porém preserva apenas as colunas do conjunto da esquerda |
left_anti | Realiza o direto oposto do left_semi, mantendo registros apenas onde a chave não existe nos conjuntos da esquerda e da direita |
outer ou full ou full_outer | Mantém todos os registros de ambos os conjuntos da esquerda e da direita |
Por padrão, a aplicação de um simples join() em Spark implica na implementação de um inner join. Se este não é comportamento adequado, é importante especificar, na chamada do método, qual o tipo de join desejado para o processo de transformação de dados codificado.
Nesta linha, para compreender como especificar o tipo de cruzamento programado, é extreamamente importante ter uma clara noção sobre a sintaxe de aplicação de joins no Spark.
Sintaxe de aplicação de joins
De forma direta, o join pode ser considerado um método de transformação aplicado à DataFrames que, por consequência, pode ser chamado e configurado através de parâmetros e argumentos específicos de acordo com as necessidades existentes. Em linhas gerais, a sintaxe de aplicação de um join é dada por:
DataFrame.join(
other=,
on=,
how=
)
O argumento other determina o segundo DataFrame alvo do cruzamento codificado. Já o argumento on estabelece a operação lógica envolvendo a chave de cruzamento utilizada na operação. Por fim, o argumento how indica o tipo de join a ser utilizado (vide tabela acima).
Por mais lúdico que tudo possa parecer, nada mais efetivo do que visualizar exemplos práticos de cruzamento de dados no Spark!
Exemplos práticos
Considerando o conteúdo teórico fornecido previamente e, trazendo à tona o significado de cada um dos objetos DataFrame lidos para serem utilizados como alvo dos exemplos práticos, esta seção será composta por múltiplos subtópicos contendo, cada um, desafios específicos que poderão ser solucionados utilizando o método join.
Informações de cidades nas saídas de vôos
Nesta proposta de tarefa, é possível pontuar que as bases de dados utilizadas na obtenção das resposta são:
df_departurecom dados relacionados à saídas de cada vôo por código de aeroporto para origem e destinodf_air_codescom dados sobre o código do aeroporto, seu nome, cidade, estado e país
A grande ideia por trás deste questionamento envolve fornecer ao usuário uma informação mais clara sobre a origem e o destino de cada vôo registrado. Por vezes, o código do aeroporto é insuficiente para transparecer objetivos à consumidores de dados que não estão intimamente relacionados com o ramo. Tecnicamente, a solução para esta tarefa envolve minimamente o cruzamento de duas fontes distintas de dados.
Por fim, antes de partir para a proposta de solução, é importante citar que existem dois locais onde as informações da localização do aeroporto precisa ser consolidada: origem e destino. Dessa forma, este é um problema que envolve a aplicação de pelo menos dois cruzamentos de dados para trazer as informações solicitadas tanto para os aeroportos de origem dos vôos como também para os aeroportos de destino.
Vamos ao código:
# Aplicando consulta analítica
df_departure_airports = df_departure.join(
other=df_air_codes,
on=(df_departure.origin == df_air_codes.IATA),
how="left"
).select(
"date",
"delay",
"distance",
expr("origin AS airport_origin"),
expr("City AS city_origin"),
"destination"
).join(
other=df_air_codes,
on=(df_departure.destination == df_air_codes.IATA),
how="left"
).select(
"date",
"delay",
"distance",
"airport_origin",
"city_origin",
expr("destination AS airport_dest"),
expr("City AS city_destination")
)
# Visualizando resultado
df_departure_airports.show(5)
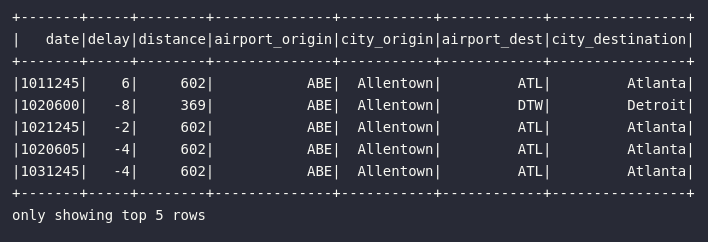
Principais pontos sobre a solução proposta:
- Múltiplas etapas de transformação podem ser codificadas em sequência visando um objetivo comum
- O resultado do método
join()é um objeto do tipo DataFrame, assim como o resultado do métodoselect() - O primeiro
jointraz a informação de cidade para a origem do vôo - O segundo
jointraz a informação de cidade para o destino do vôo - Os métodos
selectvisam consolidar os atributos de uma maneira mais legível ao usuário
Aeroportos com maior média de atraso
Assim como no exemplo anterior, esta tarefa também envolve a utilização das duas bases de vôos citadas no seguinte cenário:
df_departurecom dados relacionados à saídas de cada vôo (incluindo informações de atraso ou adiantamento através do atributodelay)df_air_codescom dados sobre o nome do aeroporto, cidade, estado e país
Adicionalmente, considerando o schema de cada uma das bases candidatas e, analisando o questionamento analítico realizado, é possível pontuar a necessidade de utilização não somente de operações de cruzamento de dados, como também grande parte dos métodos de transformação abordados nos últimos artigos desta série. Afinal, o alcance do resultado envolve minimamente processos de agregação (média) e ordenação.
# Aplicando consulta analítica
df_most_delayed = df_departure.join(
other=df_air_codes,
on=(df_departure.origin == df_air_codes.IATA),
how="left"
).groupBy("origin", "City").agg(
expr("round(avg(delay), 2) AS avg_delay"),
expr("count(1) AS qtd_voos")
).sort("avg_delay", ascending=False)
# Visualizando resultado
df_most_delayed.show(10)
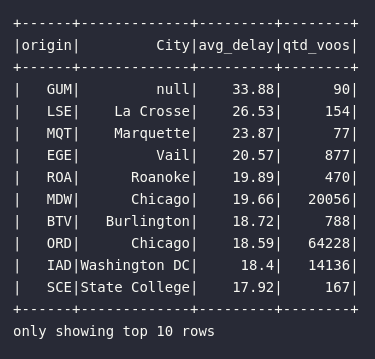
Principais pontos sobre a solução proposta:
- Apenas o cruzamento com o código de origem do vôo foi necessário para avaliar aeroportos com possíveis problemas de atraso
- O aeroporto mais problemático é identificado pela sigla
GUM, porém não há entrada para este código (atributoIATA) na base auxiliar representada pelo DataFramedf_air_codes - Múltiplas agregações foram consolidadas após o cruzamento dos dados para alcançar o resultado esperado
- Além da média de atraso (
avg(delay)), uma contagem de vôos foi fornecida para validar possíveis "pontos fora da curva". A criticidade no aeroportoGUM, com 90 registros de vôos, pode não ser tão severa quanto a encontrada emORD(Chicago) e seus mais de 60.000 vôos.
Rotas mais comuns entre cidades
No último exemplo prático deste artigo, a proposta de solução envolve programar um código em Spark capaz de trazer uma relação das rotas mais comuns entre cidades em termos de vôos registrados. Para isso, mais uma vez será preciso contar com auxílio dos DataFrames de saídas de vôos (df_departure) e de informações geográficas sobre os aeroportos (df_air_codes).
Visando proporcionar uma forma adicional de programar fluxos em Spark, diferente das soluções evidenciadas até o momento, a proposta desta tarefa será codificada em etapas. Em termos técnicos, as transformações a serem consolidadas envolvem cruzamento de dados, agrupamento, ordenação e seleção de atributos.
# Trazendo país origem do vôo
df_city_origin = df_departure.join(
other=df_air_codes,
how="left",
on=(df_departure.origin == df_air_codes.IATA)
)
# Selecionando apenas dados relevantes
df_city_origin_select = df_city_origin.selectExpr(
"City AS city_origin",
"destination"
)
# Trazendo país destino do vôo
df_city_dest = df_city_origin_select.join(
other=df_air_codes,
how="left",
on=(df_city_origin_select.destination == df_air_codes.IATA)
)
# Selecionando apenas dados relevantes
df_city_dest_select = df_city_dest.selectExpr(
"city_origin",
"City AS city_dest"
)
# Agrupando dados
df_city_grouped = df_city_dest_select\
.groupBy("city_origin", "city_dest").agg(
expr("count(1) AS count")
)
# Ordenando dados
df_city_ordered = df_city_grouped\
.sort("count", ascending=False)
# Visualizando resultado
df_city_ordered.show(10)
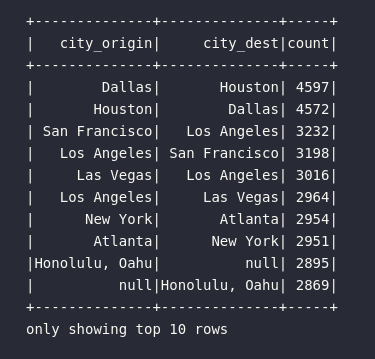
Principais pontos sobre a solução proposta:
- Cada bloco de transformação foi codificado de maneira separada, tendo seu respectivo resultado armazenado em um objeto DataFrame distinto
- A rota mais comum envolve vôos saindo de Dallas com destino à Houston
- Na sequência, a rota contrária (de Houston à Dallas) é a segunda mais frequente na base de dados
- O top 10 traz sempre uma relação de troca entre cidades de origem e de destino entre vôos mais comuns
- Em 9º e 10º lugar, é possível notar que um código de aeroporto não foi encontrado na base e, assim sendo, não é possível saber a origem e destino dos vôos que fazem par com a cidade de Honolulu
Conclusão e encerramento
Infinitos poderiam ser os exemplos a serem consolidados neste artigo envolvendo diferentes fontes de dados e a mais plurais operações de joins. De fato, cruzar dados é uma transformação altamente comum em meios analíticos.
Do outro lado do espectro, é possível citar que este tipo de operação pode ser considerada computacionalmente custosa em termos de processamento. Na dinâmica de tratamento e utilização de dados armazenados em múltiplas máquinas em um cluster de computadores, é de se imaginar que a avaliação das chaves de cruzamento e a reunião das partições necessárias podem ser ações realmente custosas.
No mais, compreender as formas de join disponíveis em Spark e, ainda por cima, ter em mãos alguns exemplos práticos de fluxos codificados pode ser considerado um marco extremamente importante dentro da proposta de aprendizado nesta ferramenta.
Foi ótimo ter você aqui, caro leitor! Até a próxima!




