

DataFrames e Datasets como Coleções Distribuídas
Compreendendo a forma como os dados são distribuídos no cluster de computadores

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! Neste artigo, o assunto abordado está literalmente presente em todo o lugar e pode ser considerado o elemento central de toda essa jornada de aprendizado: os dados.
Até este ponto, foi possível absorver uma visão história do Spark e detalhar, por meio das mais confiáveis fontes literárias, seu funcionamento prático na dinâmica promovida pela era do Big Data. No artigo anterior, experimentamos o primeiro sabor prático do Spark através de sua instalação e inicialização via shells interativas (spark-shell e pyspark) e também através de um ambiente virtual Python com Jupyter Notebook para a criação manual de uma SparkSession.
Por mais estreitos que os laços práticos tenham se tornado após essa última experiência, antes de mergulhar à fundo nos objetos, métodos e funções do Spark, é de suma importância garantir um entendimento claro sobre dados, partições e a distribuição destas coleções no universo paralelo de um cluster de computadores. Em outras palavras, a proposta deste artigo é apresentar, em todos os seus detalhes, os conceitos de DataFrames e Datasets no Spark.
Embarque nessa jornada!
Distribuição dos Dados no Spark
Em continuidade à linha prática de raciocínio já adotada nesta série, o início deste artigo parte de um dos exemplos fornecidos anteriormente e que envolve a criação de um objeto no Spark capaz de armazenar um intervalo numérico de 1000 inteiros. Seu código gerador utiliza o pyspark em um Jupyter Notebook e é dado por:
# Importando o módulo de sessão
from pyspark.sql import SparkSession
# Inicializando objeto de sessão
spark = (SparkSession
.builder
.appName("art04-dataframes")
.getOrCreate())
# Criando um DataFrame básico
df_range = spark.range(1000).toDF("numero")
df_range.show(5)
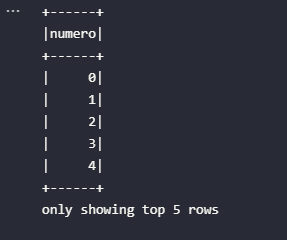
Apenas para reforçar, o código responsável por gerar este objeto parte da utilização do método range() para a criação de um intervalo de valores seguido do método toDF() para a transformação deste intervalo. A ação show() é encarregada por instruir o Spark a gerar a DAG de transformações codificadas, mas isso é um assunto para um outro artigo desta série.
Analisando o retorno do bloco de código acima, é possível pontuar que o objeto df_range é o elemento que "carrega" a informação do intervalo especificado. E assim, a pergunta que se faz é: o que é este objeto? Para respondê-la, é possível observar, em primeiro lugar, seu tipo primitivo:
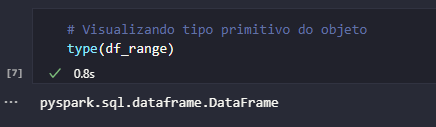
De fato, trata-se de um objeto do tipo DataFrame para o Spark (mais especificamente pyspark.sql.dataframe.DataFrame, mas facilmente simplificado como apenas DataFrame). De forma resumida, é possível definir um DataFrame como uma representação de uma tabela de dados contendo basicamente linhas e colunas. Sob a ótica do Spark, DataFrames são considerados como APIs estruturadas contendo coleções distribuídas de dados em memória.
“Para o Spark, DataFrames e Datasets são estruturas que representam planos de execução imutáveis, avaliados de forma lazily e que especificam operações a serem aplicadas aos dados armazenados em uma localidade específica de modo a gerar um certo output. Quando executamos uma ação em um DataFrame, instruímos o Spark a executar as transformações programadas e retornar um resultado. Isto representa um plano de manipulação de linhas e colunas para computar o resultado desejado pelo usuário.”
Trecho retirado do livro Spark: The Definitive Guide
Neste ponto, é interessante citar que o conceito de DataFrame não é exclusivo ao Spark. Para os familiarizados com Python, certamente os DataFrames do pandas já foram notados em algum momento da jornada. Por mais que os termos sejam idênticos, é importante sempre ter em mente que, em cenários de Big Data, todo o processamento ocorre de forma paralela e distribuída, tornando assim os conceitos característicos invariavelmente adeptos à esta fundamental propriedade. Salvo alguns cenários específicos, DataFrames em Python ou R existem em uma única máquina, enquanto DataFrames do Spark existem em múltiplas máquinas de um cluster de computadores.
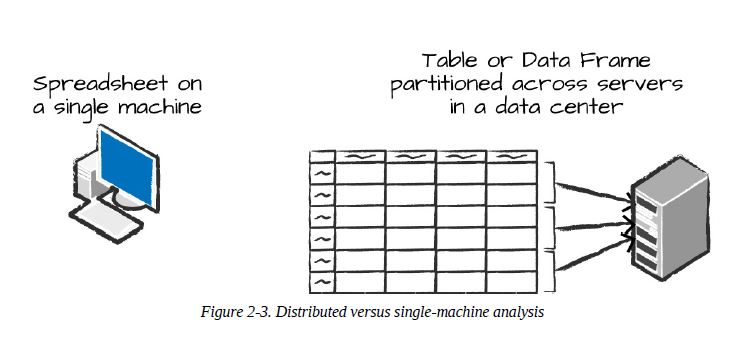
Assim, de modo a permitir que cada executor trabalhe em paralelo, o Spark literalmente "quebra" os dados em chunks chamados de partições. Uma partição pode ser definida como um conjunto de linhas presentes em uma máquina física do cluster. Um esquema particionado de dados em blocos permite que os programas executores processem apenas dados próximos entre si, minimizando assim altos tráfegos de rede.
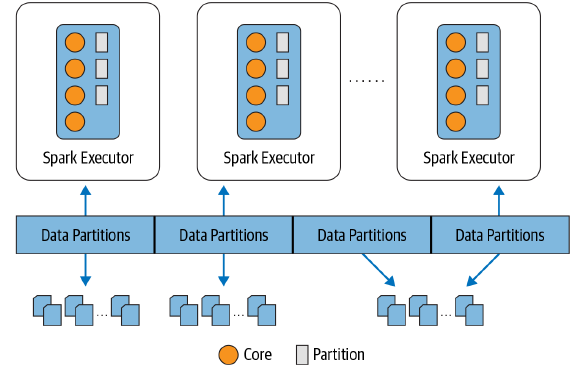
Seguindo está lógica, seria correto pontuar que o DataFrame df_range, utilizado como exemplo, está particionado em múltiplas máquinas? Bem, a resposta mais correta para esta pergunta é que sim, desde que o Spark esteja instalado e configurado para isto. No caso demonstrativo, o Spark está sendo utilizado em seu modo local e, dessa forma, apenas uma única JVM é instanciada para processar os cálculos. Mesmo assim, o Spark faz de tudo para adicionar paralelismo em suas atividades e, para validar a quantidade de partições em um objeto DataFrame criado, basta descer um pouco o nível e chamar o método getNumPartitions() do módulo rdd.
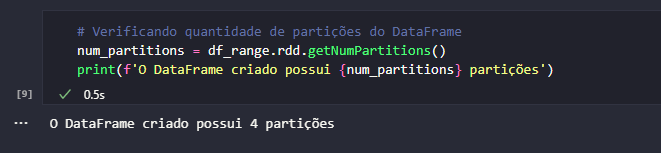
Mesmo em seu modo local, um simples DataFrame de 1000 linhas criado manualmente no Spark possui 4 partições. Em tese, a configuração das partições não é algo realizado recorrentemente pelo engenheiro ou cientista de dados. A premissa é sempre verdadeira: quanto mais partições, maior o nível de paralelismo adotado. Porém, um alto paralelismo não implica necessariamente em uma maior velocidade. É preciso configurar um nível ótimo e que faça sentido diante dos propósitos estabelecidos.
Tipos Primitivos
Uma vez conhecidas as nuances do conceito de Dataframe sob a ótica do Spark, é importante abordar os tipos primitivos envolvendo tais coleções distribuídas de dados. Afinal, um simples DataFrame contendo um intervalo de 1000 inteiros possui, em seu conteúdo, um tipo primitivo característico.
Internamente, o Spark usa um motor conhecido como Catalyst contendo sua própria informação sobre tipos primitivos ao longo do planejamento e processamento dos cálculos. Isso proporciona algumas vantagens, como por exemplo, a otimização do tempo de processamento dos fluxos de dados. Entretanto, sabendo que o Spark é uma ferramenta capaz de ser operada nas mais variadas linguagens de programação através de suas APIs estruturadas, é esperado que haja uma relação entre a tipagem de dados do Catalyst e seu equivalente na linguagem utilizada.
Com foco no Python (assim como em todos os exemplos já fornecidos e a serem construídos nesta série), a tabela abaixo traz uma relação direta entre os tipos primitivos do Spark e seu equivalente em Python:
| Tipo Primitivo | Equivalente no Python | Instância |
| ByteType | int | DataTypes.ByteType |
| ShortType | int | DataTypes.ShortType |
| IntegerType | int | DataTypes.IntegerType |
| LongType | int | DataTypes.LongType |
| FloatType | float | DataTypes.FloatType |
| DoubleType | float | DataTypes.DoubleType |
| StringType | str | DataTypes.StringType |
| BooleanType | bool | DataTypes.BooleanType |
| DecimalType | decimal.Decimal | DecimalType |
Adicionalmente, existem os tipos primitivos complexos e estruturados que também possuem comparações equivalentes:
| Tipo Primitivo | Equivalente no Python | Instância |
| BinaryType | bytearray | BinaryType() |
| TimestampType | datetime.datetime | TimestampType() |
| DateType | datetime.date | DateType() |
| ArrayType | list, typle ou array | ArrayType(dataType, [nullable]) |
| MapType | dict | MapType(keyType, valueType, [nullable]) |
| StructType | Lista de tuplas | StructType([fields]) |
| StructField | Correspondente ao tipo do campo | StructField(name, dataType, [nullable]) |
A importância em conhecer essa relação está intimamente ligada ao conceito de schema no Spark.
Schemas
DataFrames possuem schema, ou seja, colunas bem definidas com seus respectivos tipos primitivos. Em linhas gerais, o Spark possui opções para assumir automaticamente o schema de uma fonte externa (um arquivo, por exemplo) e determinar, da melhor forma que conseguir, os tipos primitivos envolvidos. Por outro lado, é possível considerar uma boa prática a definição explícita de um schema antes da leitura de uma fonte externa de dados, garantindo uma maior padronização e sustentabilidade do fluxo construído, principalmente se ele estiver sendo utilizado em produção.
O DataFrame df_range não foi criado através da leitura de um arquivo externo ou algo assim. Na verdade, sua instância foi concebida manualmente através do fornecimento de um intervalo de valores. De um jeito, ou de outro, sendo ele um objeto do tipo DataFrame, é possível dizer que existe um schema vinculado. Assim, para verificar o schema de um objeto DataFrame, basta executar seu método printSchema().
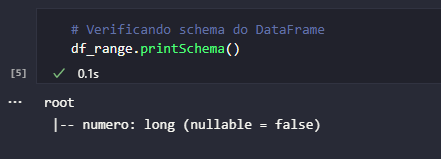
Interpretando o resultado do comando ilustrado acima, é possível pontuar que o DataFrame df_range possui uma única coluna chamada numero do tipo long e que não possui (ou não aceita) valores nulos (nullable = false). Este tipo de análise pode ser feita independente do DataFrame, seja ele criado manualmente ou gerado a partir da leitura de arquivos locais, bancos de dados (ODBC) ou sistemas de armazenamentos distribuído (HDFS, S3).
Agora que explicações sobre DataFrames e seus respectivos tipos primitivos foram fornecidas, é possível abordar o conceito de Datasets.
Diferenças entre DataFrames e Datasets
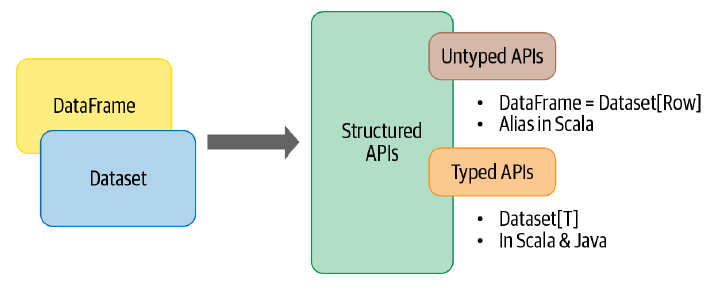
Em geral, Datasets possuem um conceito estritamente semelhante ao de DataFrames, porém com uma principal diferença que o torna altamente característico: para o Spark, Datasets são estruturas "tipadas" existentes apenas nas linguagem Scala e Java.
Há pouco, foi dito que DataFrames são estruturas que possuem schema com tipos primitivos bem definidos. No caso dos Datasets, a verificação dos tipos primtiivos ocorre em tempo de compilação, enquanto nos DataFrames, este mesmo processo ocorre em tempo de execução.
Indo aquém dos detalhes técnicos, na grande maioria dos casos, os usuários de Spark estarão utilizando DataFrames. Para alguns casos específicos e, considerando o uso do Spark em Scala ou Java, é possível que o conceito de Datasets esteja presente, principalmente se a coleção distribuída precisar assumir um tipo primitivo descrito por classes nas duas linguagens mencionadas. Para Scala e Java, DataFrames são basicamente considerados Datasets do tipo Row.
Encerramento e conclusão
E assim, é chegado ao fim mais um artigo desta série onde um assunto fundamental foi abordado e discutido. Falar sobre dados é, de certa forma, estar em linha com qualquer ferramenta analítica.
Para o Spark, DataFrames e Datasets são as APIs estruturadas com grande adoção por parte da comunidade, sendo a primeira delas universalmente utilizada em conjunto com as linguagens Python e R. Ter este primeiro contato com essas coleções distribuídas é a chave para o entendimento de assuntos relativamente mais complexos, como planos de execução, transformações, ações e aplicações Spark no geral.
Espero que o conteúdo aqui consolidado tenha sido aproveitado tanto quanto possível. Aguardo vocês no próximo artigo!




