




Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark!
Em uma dinâmica prática de obtenção, preparação e carregamento de dados, atuar de modo a garantir uma eficiente análise para os tomadores de decisão é, sem dúvidas, uma tarefa fundamentalmente valiosa. Para a construção de produtos de dados a serem utilizados como alvos de tais processos analíticos, uma vasta gama de possibilidades são colocadas à mesa para serem escolhidas, pelos envolvidos no desenvolvimento, de acordo com as especificações e os objetivos a serem alcançados. Dessa forma, considerando qualquer cenário agnóstico à ferramentas e frameworks, o usuário terá em mãos uma série de funções, métodos ou qualquer outro artifício computacional para preparar, enriquecer, agrupar, modificar e, por fim, disponibilizar conjuntos de dados específicos e pontualmente construídos para atender às necessidades exigidas.
Por mais holístico que o trecho acima possa (intencionalmente) ter sido apresentado, é preciso pontuar que, em meio a todo este processo, alguns desses tais artifícios computacionais acabam caindo no esquecimento dos usuários que, de forma verdadeiramente honesta, acabam por contornar esse gap utilizando caminhos mais "pavimentados", mas que muitas vezes exigem mais código e mais processamento. Em alguns casos, a rota "mais simples" para alcançar um dado objetivo em um produto de dados não é a mais eficiente, o que prejudica toda a cadeia de extração de valor.
Assim, considerando esta filosófica introdução e, com um grande auxílio do próprio título deste artigo, os tópicos a serem abordados neste novo post estão intimamente relacionados à um conceito que se enquadra perfeitamente neste "mundo esquecido" de analytics: as funções window! Para aqueles que sempre tiveram uma certa dificuldade em entender a aplicar funções window em cenários de transformação de dados, seja em uma ferramenta específica ou mesmo utilizando SQL puro, este artigo possui a genuína missão de apresentar este conceito, aplicado ao Apache Spark, da forma mais clara e objetiva possível.
O que são funções window?
De início, é importante proporcionar uma honrosa apresentação ao processo de windowing (ou janelamento) como uma forma eficiente de carregar e computar agregações considerando uma janela específica de um conjunto de dados. Em outras palavras, diferente de processos de agrupamento, onde cada registro é direcionado para um único grupo, funções window consideram a definição de um conjunto de registros (ou frames) para retornar, a partir do cálculo aplicado, um resultado para cada registro de entrada, permitindo assim a construção de processos analíticos únicos.
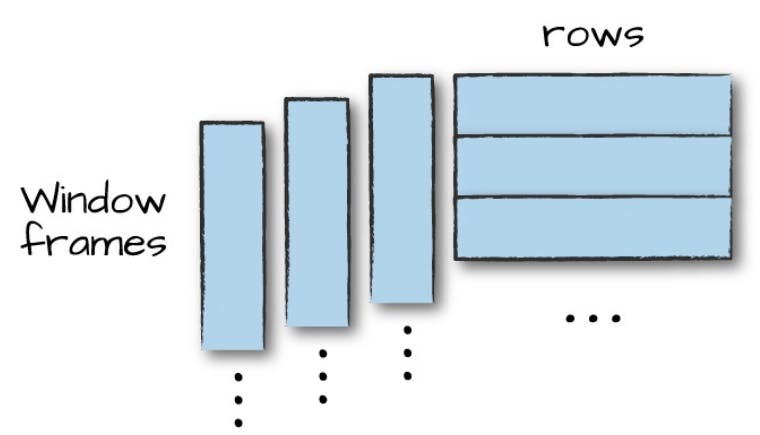
Na figura acima, extraída do livro Spark: the Definitive Guide, é possível visualizar os frames da janela aplicados aos registros de um conjunto de dados qualquer. Na prática, com as funções de janela, para cada registro do referido conjunto, um novo valor é adicionado a partir de um cálculo que considera, como referência, a respectiva janela especificada no processo.
Se tudo ainda soa complexo e abstrato, imagine que, com as funções window, seja possível calcular a média móvel de um determinado atributo numérico com base em uma janela temporal especificada. Assim, para cada registro de um DataFrame, o cálculo da média é realizado considerando o N registros posteriores (ou inferiores), gerando assim um valor único adicionado como uma nova coluna no conjunto de dados.
No decorrer deste artigo, exemplos práticos serão fornecidos para consolidar todo o conhecimento apresentado. Antes disso, é fundamental abordar os detalhes adicionais das funções de janela sob a ótica do Spark, a começar pelos diferentes tipos de funções disponíveis dentro deste contexto.
Diferentes tipos de funções window
No Spark, existem três grandes categorias de funções de janela que podem ser utilizadas para os mais variados propósitos:
- Funções de ranqueamento
- Funções analíticas
- Funções de agregação
As funções de agregação são as mesmas já conhecidas e utilizadas em outros exemplos desta mesma série. Grande parte delas (se não todas) estão disponíveis no módulo pyspark.sql.functions. As demais funções que se enquadram nas outras duas categorias são apresentadas a partir da tabela abaixo:
| Categoria | DataFrame API | Descrição |
| Ranking | rank() | Aplica um ranqueamento com base em uma especificação de janela |
dense_rank() | Semelhante à função rank(), porém sem gaps entre os rankings em situações de "empate" | |
percent_rank() | Retorna o ranking relativo (percentil) do registro em relação à janela | |
ntile() | Semelhante à função percent_rank(), porém com a possibilidade de definir um valor "N" de quadrantes | |
row_number() | Retorna o número da linha do registro com base na janela especificada | |
| Analytics | cume_dist() | Retorna a distribuição acumulada dos valores em uma janela, isto é, a fração de linhas que estão abaixo da linha atual |
lag() | Retorna o valor anterior com um offset parametrizável dentro da janela especificada | |
lead() | Opera de forma contrária à função lag(), trazendo o valor posterior de acordo com um offset parametrizado |
Etapas para a aplicação: a classe Window
Após uma apresentação geral sobre o que são e quais são as funções de janela disponíveis no Spark, de forma breve e direta, é preciso apresentar as etapas necessárias para sua aplicação prática. Em linhas gerais, qualquer operação de janelamento envolve duas etapas fundamentais:
- A definição de uma especificação de janela (window spec)
- A aplicação de uma função de janale sobre a especificação criada
A definição de uma especificação de janela, em Spark, parte da utilização da classe Window presente no módulo pyspark.sql:
# Importando classe
from pyspark.sql import Window
Uma vez importada, a classe Window é a base para a criação de uma especificação de janela considerando a seguinte sintaxe:
# Definindo especificação de janela
window_spec = Window\
.partitionBy("col_A")\
.orderBy("col_B")
No trecho acima, a coluna "col_A" é utilizada como partição da janela, enquanto a coluna "col_B" é a base de ordenação do conjunto. Existem, ainda, os métodos rowsBetween() e rangeBetween() que podem ser pontualmente configurados e utilizados como uma forma de especificar a janela conforme as necessidades presentes. No exemplo abaixo, uma especificação de janela é construída para considerar todos os registros anteriores à linha atual.
# Definindo especificação de janela
window_spec = Window\
.partitionBy("col_A")\
.orderBy("col_B")\
.rowsBetween(Window.unboundedPreceding, Window.currentRow)
E assim, especificada a janela, as funções e os cálculos estatísticos de agregação podem ser aplicados através do método over(), seja em consultas via select() e selectExpr() ou através de adição de atributos via withColumn():
# Aplicando função window em consulta
df_prep = df.select(
"col_A",
"col_B",
"col_C",
"col_D",
max("col_E").over(window_spec).alias("window_max_E"),
avg("col_E").over(window_spec).alias("window_avg_E"),
)
# Aplicando função window como nova coluna
df.withColumn("window_avg_E", max(col("col_E")).over(window_spec))
Com isso, é possível afirmar que grande parte da teoria envolvendo processos de janelamento no Spark foi fornecida. A partir deste ponto, uma série de situações práticas serão simuladas para que todo este ensinamento possa ser aplicado e visualizado em cenários reais de trabalho.
Dados para exploração (opcional)
Para a demonstração das operações de janelamento a serem apresentadas, uma base de dados contendo medições de sensores IoT será utilizada. Este mesmo conjunto esteve presente no artigo sobre agrupamento nesta mesma série e, para a ocasião atual, uma pequena modificação será proposta para facilitar o entendimento dos códigos a serem disponibilizados. Como um primeiro passo, é preciso configurar e realizar a leitura do conjunto de dados como um novo DataFrame disponível na sessão Spark:
# Importando biblitoecas
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, \
StringType, IntegerType, DoubleType, LongType
import os
# Criando objeto de sessão
spark = SparkSession\
.builder\
.appName("agregacoes")\
.getOrCreate()
# Definindo variáveis de diretório
home_path = os.path.expanduser('~')
data_path = os.path.join(home_path, 'dev/panini-tech-lab/data')
iot_path = os.path.join(data_path, 'iot-devices/iot_devices.json')
# Definindo schema para o arquivo a ser lido
iot_schema = StructType([
StructField("device_id", IntegerType(), nullable=False),
StructField("device_name", StringType(), nullable=True),
StructField("ip", StringType(), nullable=True),
StructField("cca2", StringType(), nullable=True),
StructField("cca3", StringType(), nullable=True),
StructField("cn", StringType(), nullable=True),
StructField("latitude", DoubleType(), nullable=True),
StructField("longitude", DoubleType(), nullable=True),
StructField("scale", StringType(), nullable=True),
StructField("temp", IntegerType(), nullable=True),
StructField("humidity", IntegerType(), nullable=True),
StructField("battery_level", StringType(), nullable=True),
StructField("c02_level", IntegerType(), nullable=True),
StructField("lcd", StringType(), nullable=True),
StructField("timestamp", LongType(), nullable=False)
])
# Lendo dados
df_iot_raw = spark.read.format("json")\
.schema(iot_schema)\
.load(iot_path)
# Criando tabelas temporárias
df_iot_raw.createOrReplaceTempView("tbl_iot")
# Visualizando dados
df_iot_raw.printSchema()
df_iot_raw.show(10)
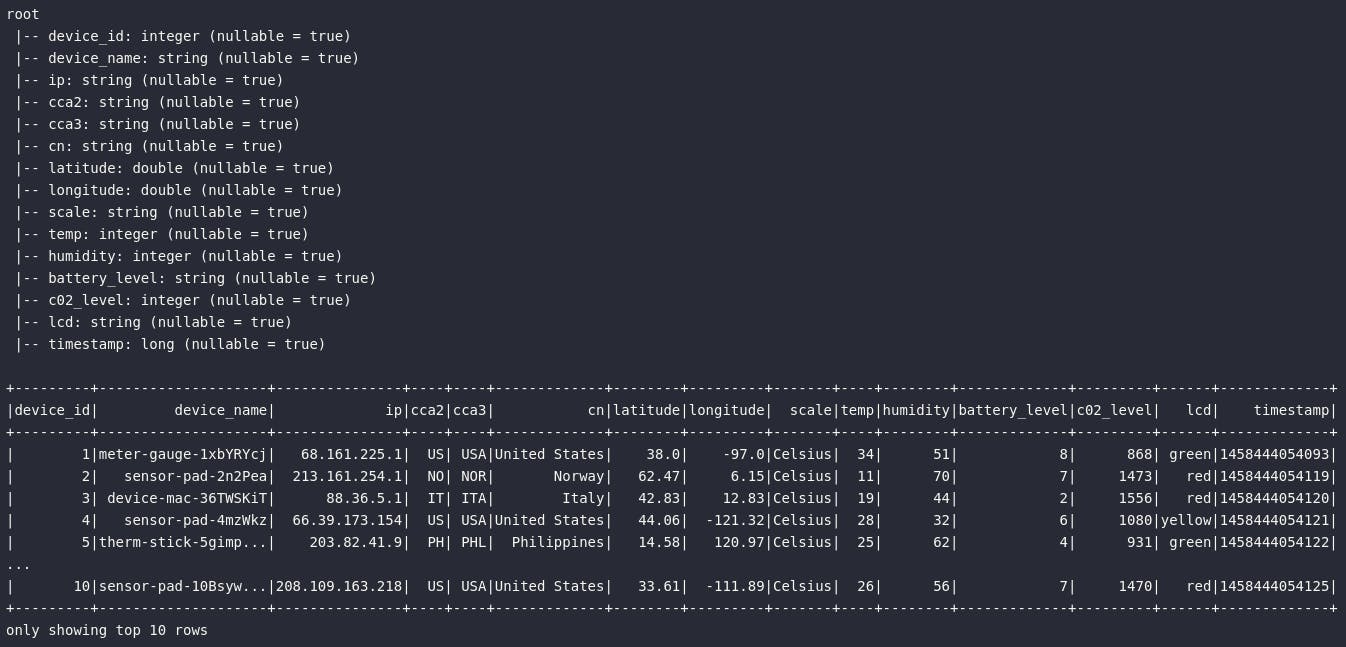
Como mencionado, o conjunto bruto disponibilizado será levemente modificado para comportar apenas algumas colunas juntamente com uma transformação no atributo timestamp de modo a gerar uma data de medição em um formato mais "amigável". Para tal, será proposta a aplicação dos seguintes passos de transformação:
- Criação de uma lista em Python com valores aleatórios a serem adicionados à coluna
timestampde modo a aumentar o range de datas originalmente disponibilizado pela base, permitindo assim análises mais ricas - Adição da lista de valores aleatórios como uma nova coluna do DataFrame com base em uma UDF (User Defined Function) e a função
monotonically_increasing_id()aplicada de modo a garantir a ordem dos valores de entrada - Aplicação da soma entre o timestamp original e os valores gerados aleatoriamente para a criação de uma nova coluna temporal
- Transformação da nova coluna criada em um formato de data
- Eliminação dos atributos sobressalentes
# Importando funções
import random
from pyspark.sql.functions import udf, monotonically_increasing_id,\
split, to_date, from_unixtime, col, expr
# Criando lista de valores aleatórios para serem adicionados ao DataFrame
random.seed(42)
rows = df_iot_raw.count()
date_add = [random.randint(a=-10000000, b=10000000) for i in range(rows)]
# Gerando base de dados de trabalho
df_iot = df_iot_raw.select(
split(col("device_name"), "-")[0].alias("device_type"),
col("cn").alias("country"),
col("temp"),
col("humidity"),
col("c02_level"),
col("timestamp").alias("timestamp_raw")
).withColumn("date_add", udf(lambda id: date_add[id])(monotonically_increasing_id()))\
.withColumn("timestamp", from_unixtime((col("timestamp_raw") / 1000) + col("date_add")))\
.withColumn("date", to_date(col("timestamp")))\
.drop("timestamp_raw", "date_add")
# Visualizando dados
df_iot.orderBy("timestamp").show(10)
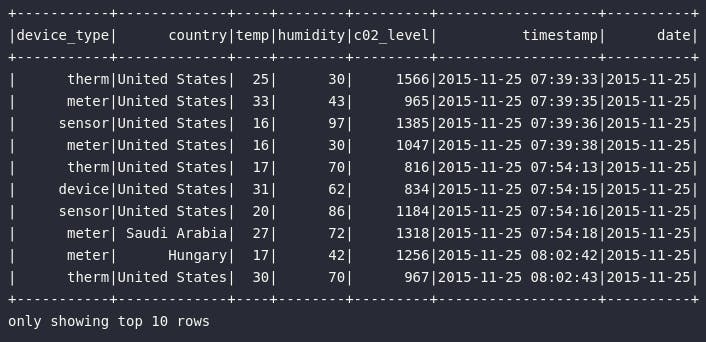
Por fim, considerando que todo o contexto fornecido neste artigo para justificar o aprendizado em funções de janelamento envolve, essencialmente, a utilização de um novo artifício computacional para aprimorar a forma como os dados são utilizados como produtos para uma melhor tomada de decisão, é substancialmente importante ter uma clara noção sobre o conteúdo do conjunto alvo.
Para os propósitos aqui envolvidos, basta ter clareza de que o DataFrame df_iot contempla dados de medições de sensores IoT coletados de diferentes fábricas localizadas em diferentes países. As medições envolvem essencialmente a temperatura, umidade e nível de gás carbônico da máquina. Cada medição foi registrada em um instante específico de tempo. Adicionalmente, informações sobre os sensores também podem ser encontradas na base.
Diferença entre agrupamento e janelamento
No início deste artigo, uma definição formal do processo de janelamento foi fornecida em um caráter comparativo. Para visualizar os efeitos práticos desta definição, o bloco de código abaixo considera a aplicação de um processo de agrupamento ma base de sensores IoT para responder às seguintes perguntas: "Quantas medições foram realizadas para cada país e qual a média de temperatura de cada um?"
# Importando função
from pyspark.sql.functions import avg, round
# Aplicando agrupamento
df_country_temp = df_iot.groupBy("country").agg(
round(avg(col("temp")), 2).alias("avg_temp"),
count("*").alias("measurements")
)
# Visualizando resultado
df_country_temp.orderBy("measurements", ascending=False).show(10)
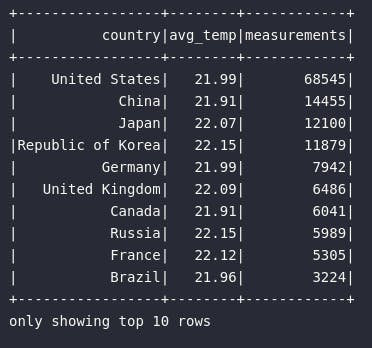
Observando o resultado acima, é fácil perceber que os registros da base de dados foram designados à um dos grupos especificados pelo atributo country. Isto é o processo clássico de agrupamento notoriamente conhecido.
Entretanto, caso o objetivo de transformação envolvesse retornar estes mesmos valores estatísticos de média e contagem sem agrupar os dados, ou seja, mantendo a mesma granularidade da base, a forma mais eficaz de construir um conjunto de dados neste formato seria através das funções de janela:
# Importando módulos
from pyspark.sql import Window
# Definindo especificação de janela
window_spec = Window.partitionBy("country")
# Aplicando consulta
df_country_temp_window = df_iot\
.where(expr("country != ''"))\
.select(
"country",
"scale",
"temp",
"humidity",
"c02_level",
"date",
round(avg("temp").over(window_spec), 2).alias("avg_cn_temp"),
count("*").over(window_spec).alias("cn_meas")
)
Para visualizar os resultados, uma ordenação aleatória dos registros será proporcionada para que os agregados estatísticos de média e contagem possam ser visualizados em cada registro distinto para cada país da janela:
# Importando função para ordenação
from pyspark.sql.functions import rand
# Visualizando resultado
df_country_temp_window.orderBy(rand()).show(10)
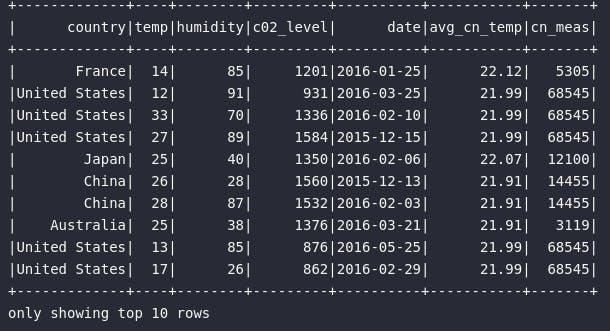
Observando o resultado acima, é possível perceber que a granularidade da base foi mantida e, através da função de janela, os resultados foram contabilizados para cada registro com base na especificação codificada (Window.partitionBy("country")). Para provar a efetividade do cálculo, todas linhas do conjunto que representam o país "United States" possuem os valores 21.99 para a média de temperatura e 68545 para a contagem de medições, sendo estes os valores exatos calculados previamente através do agrupamento clássico.
Este é apenas um simplório e ilustrativo exemplo comparativo do que pode ser realizado com funções window. Nos tópicos subsequentes, demonstrações mais complexas serão fornecidas para algumas das principais funções de janela disponíveis no Spark. Em cada caso, um cenário real de trabalho será exemplificado de modo a garantir e justificar o uso do processo de janelamento em fluxos produtivos.
Ranqueamento
Após uma breve fundamentação teórica seguida de um exemplo prático inicial, é chegado o momento de mergulhar à fundo nas principais funções de janela utilizadas no cotidiano de transformações de dados no Spark. Em um primeiro momento, serão abordadas as funções window presentes na categoria de ranqueamento.
rank() e dense_rank()
Abrindo as portas para novas explorações, serão apresentadas duas funções fundamentalmente importantes neste cenário: rank() e dense_rank()
Como um cenário prático de demonstração, o objetivo de aplicação de tais funções de ranqueamento envolve proporcionar uma análise mais efetiva sobre os picos de emissão de gás carbônico (atributo c02_level) para cada dia de medição. Em outras palavras, pretende-se ranquear as medidas, dia a dia, para analisar as maiores emissões de gás carbônico registradas pelos dispositivos. Com essa explicação, já é possível imaginar uma especificação de janela? Vamos começar por ela:
# Especificando janela
window_date_c02 = Window\
.partitionBy("date")\
.orderBy(col("c02_level").desc())\
.rowsBetween(Window.unboundedPreceding, Window.currentRow)
No bloco de código acima, a especificação de janela é construída com base nas necessidades de análise estabelecidas. Considerando que a ideia é justamente analisar as informações dia a dia, o método partitionBy() recebe a coluna date como principal argumento, separando assim os blocos de análise para cada data presente no DataFrame. Já o bloco orderBy() é alimentado com a coluna c0_level em uma ordenação descendente dos valores, permitindo assim que o ranqueamento seja corretamente aplicado para eleger os maiores volumes de emissão de gás. Por fim, o método rowsBetween() basicamente especifica que os frames da janela serão construídos com base no registro atual e em todos os registros precedentes do DataFrame, permitindo uma comparação completa entre os valores de emissão de gás em cada partição de data.
Assim, com a especificação construída, é possível codificar uma consulta capaz de aplicar as funções de janela aos frames configurados:
# Importando funções
from pyspark.sql.functions import rank, dense_rank
# Consultando datas de pico de emissão de carbono
df_c02_peak = df_iot.select(
col("device_type"),
col("country"),
col("c02_level"),
col("date"),
col("timestamp"),
rank().over(window_date_c02).alias("c02_rank"),
dense_rank().over(window_date_c02).alias("c02_dense_rank")
)
# Visualizando dados
df_c02_peak.orderBy("date").show(10)
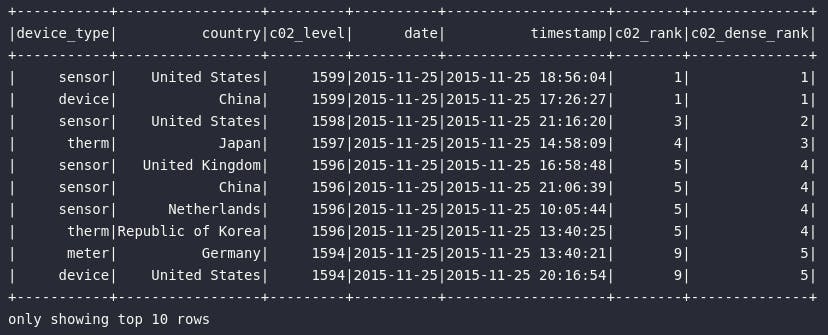
Como principal insight da consulta acima, é possível estabelecer que, no dia 25/11/2015 (primeiro registro de data da base), o pico de emissão de gás carbônico esteve atrelado à uma medição de um sensor realizada nos Estados Unidos às 18:56:04. Na sequência, emptada em termos numéricos, uma medição realizada na China às 17:26:27 ocupa a segunda colocação. Completando o top 3, uma nova medição feita nos Estados Unidos registrada às 21:16:20 indica mais um alto nível de emissão de gás.
Neste momento, é importante notar a diferença entre as funções rank() e dense_rank() como forma de ranquear resultados. A primeira não deixa lacunas entre os rankings em caso de "empate" e isso pode ser visualizado logo nas primeiras posições, onde a primeira e a segunda medição são idênticas e ocupam o primeiro lugar, quando a terceira, por sua vez, ocupa realmente o ranking de número 3. Já no caso da dense_rank(), lacunas são deixadas entre as posições em casos de empate, sendo este comportamento presente neste mesmo cenário, onde a terceira medição mais ofensora ocupa o ranking de número 2.
Ainda assim, o usuário deve se perguntar: "por que utilizar funções de janela quando, na verdade, a solução para este problema poderia ser tranquilamente obtida através de uma simples ordenação ascendente por data e descendente por emissão de gás carbônico?" De fato, esta afirmação está correta mas, considerando a gama de possibilidades proporcionada pelas funções de janela, imagine agora que um novo pedido se faça presente para retornar apenas os 3 principais ofensores, em termos de missão de gás carbônico, para cada uma das datas de medição? Com o ranking estabelecido, este problema é facilmente solucionado com um filtro:
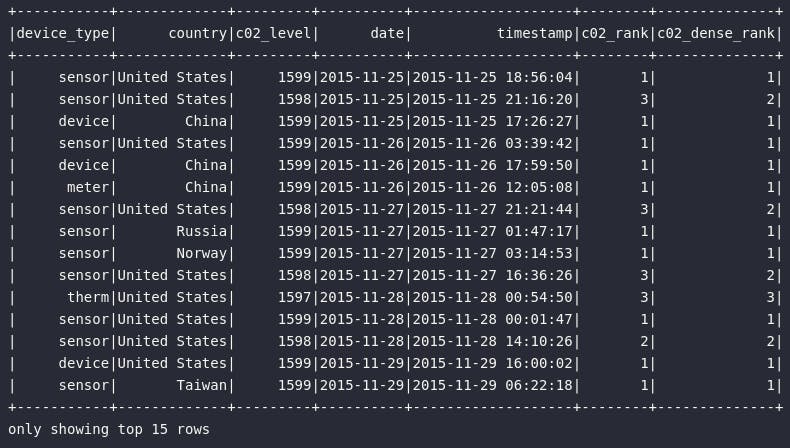
# Top 3 ofensores por dia
df_c02_peak\
.where(expr("c02_rank <= 3"))\
.orderBy("date")\
.show(15)
Adicionalmente, seria também possível retornar a quantidade de vezes que um determinado país foi considerado um ofensor diário de emissão de gás carbônico. Com o auxílio da função collect_list(), a consulta se torna ainda mais completa a partir do retorno de todos os momentos de picos de medição de gás carbônico nos países, permitindo uma análise bem específica sobre o cenário:
# Importando função
from pyspark.sql.functions import collect_list
# Quantidade de vezes que um país ficou no top 1
df_c02_peak\
.where(expr("c02_rank == 1"))\
.groupBy("country").agg(
count("*").alias("count_main_c02_emissor"),
collect_list("timestamp").alias("c02_peak_timestamps")
)\
.orderBy("count_main_c02_emissor", ascending=False)\
.show(10)
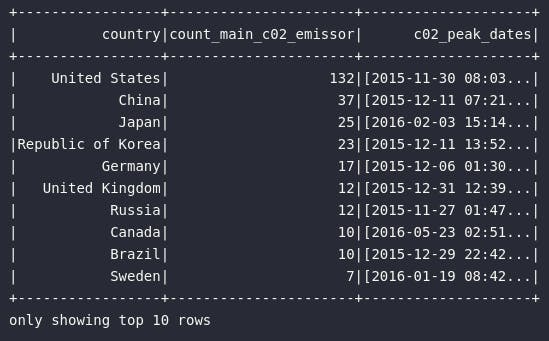
Como principal resultado, é possível observar que os Estados Unidos apareceram 132 vezes (132 dias) como principais ofensores de emissão de gás carbônico entre os dispositivos IoT considerados. O ranking segue com China, Japão, Coréia e Alemanha.
Uma série de outras análises de ranqueamento poderiam ser implementadas mas, com o fornecido até aqui, é possível visualizar o grande poder atrelado às funções de janela em consultas analíticas de dados.
percent_rank() e ntile()
Ainda imersos na categoria de funções de janela relacionadas ao ranqueamento de registros, as funções percentile_rank() e ntile() se mostram como alternativas interessantes para propósitos específicos de análise.
# Importando funções
from pyspark.sql.functions import percent_rank, ntile, round
# Comparando diferentes funções de ranqueamento
df_c02_peak_ranking = df_iot.select(
"device_type",
"country",
"temp",
"humidity",
"c02_level",
"timestamp",
rank().over(window_date_c02).alias("rank"),
dense_rank().over(window_date_c02).alias("dense_rank"),
round(percent_rank().over(window_date_c02), 5).alias("percent_rank"),
ntile(n=100).over(window_date_c02).alias("ntile_100")
)
# Visualizando dados
df_c02_peak_ranking.orderBy("date").show(15)
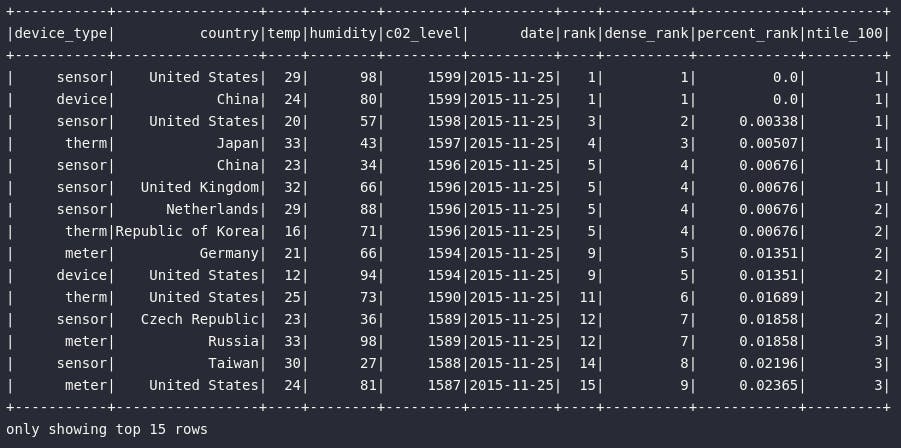
Em termos gerais, a função percent_rank() pode ser aplicada quando o problema analítico a ser resolvido envolve retornar um percental específico de registros dentro da especificação de janela. Em outras palavras, sua aplicação cairia como uma luva caso a necessidade de análise envolvesse responder uma pergunta tal como: "Qual o top 1% de países que mais emitiram gás carbônico no dia 25/11/2015?". A solução para este problema não pode ser obtida exclusivamente a partir de um ranqueamento comum como rank() ou dense_rank(), visto que não se sabe de antemão onde os 1% se encaixam na hierarquia. Assim, a resposta pode ser perfeitamente obtida através de um filtro em percent_rank() para trazer apenas registros menores ou iguais a 0.01 (1% do conjunto):
# Top 1% países mais emissores de um dia específico
df_c02_peak_ranking\
.where(expr("date = '2015-11-25'"))\
.where(expr("percent_rank <= 0.01"))\
.show()
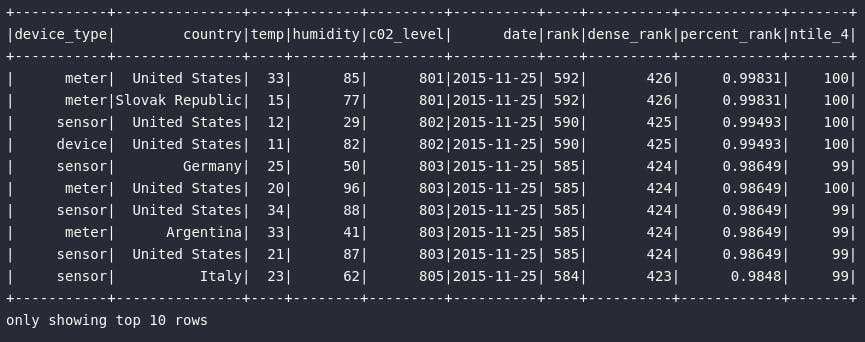
Já a função ntile() possui um papel bem específico que pode ser entendido como uma espécie de ranqueamento em meio a uma quantidade N de grupos. Neste contexto, primeiro define-se uma quantidade de blocos a serem utilizados como alvo do processo dentro da janela especificada. No exemplo codificado, referenciar n=100 como argumento da função indica que, para cada data da janela, o ranking será aplicado considerando 100 grupos distintos, onde os maiores emissor de gás carbônico notoriamente serão ranqueados nas primeiras posições e, os menores emissores, em posições maiores, nunca ultrapassando o limite definido pelo parâmetro N.
# Visualizando o efeito de ntile na borda de baixo
df_c02_peak_ranking\
.where(expr("date = '2015-11-25'"))\
.orderBy("c02_level")\
.show(10)
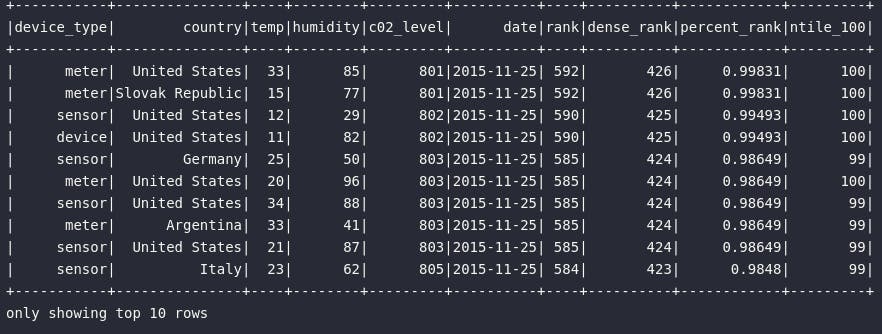
Analytics
Após uma iniciação extremamente convidativa em funções window presentes na categoria de ranqueamento, é chegado o momento de explorar alguns exemplos práticos de janelamento envolvendo a categoria de analytics.
lag() e lead()
Já se viu presente em uma situação específica de trabalho envolvendo a necessidade de se analisar ou comparar registros imediatamente anteriores ou posteriores em uma base de dados? As funções lag() e lead() atuam justamente neste contexto e permitem, dentro de uma especificação de janela, obter valores acima ou abaixo, respectivamente.
Em uma situação prática de análise, considerando todas as medições de temperaturas obtidas na base de dados, imagine que uma nova solicitação seja feita para aplicar um cálculo de delta envolvendo uma comparação entre o registro de temperatura imediatamente anterior em cada um dos países? Para isso, é possível utilizar todos os conhecimentos de janelamento obtidos até aqui para criar um novo DataFrame capaz de responder o referido questionamento da forma mais eficiente possível:
# Importando funções
from pyspark.sql.functions import lag
# Definindo especificação de janela
window_spec = Window\
.partitionBy("country")\
.orderBy("timestamp")
# Obtendo temperaturas anteriores e posteriores para cálculo do delta
df_delta_temp = df_iot.where(expr("country != ''")).select(
"country",
"timestamp",
"temp",
lag("temp").over(window_spec).alias("preceding_temp")
).withColumn("delta_temp", expr("temp - preceding_temp"))
# Visualizando resultado
df_delta_temp\
.where(expr("country = 'United States'"))\
.orderBy("timestamp")\
.show(15)
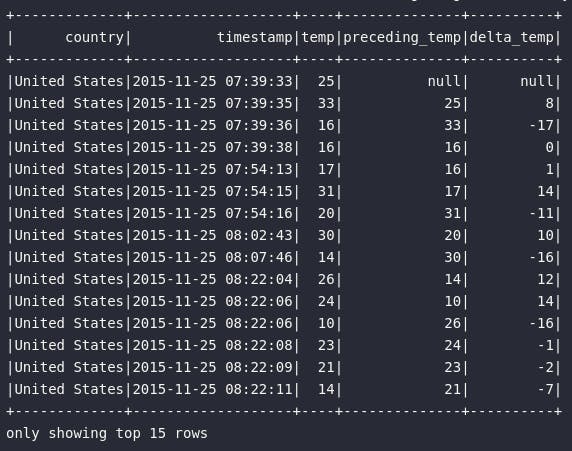
No bloco de código acima, uma espeificação de janela é criada com um particionamento em país e uma ordenação por timestamp, permitindo assim a aplicação da função lag() sobre a janela com offset igual 1 de modo a retornar a temperatura no instante de tempo imediatamente anterior ao registro atual. Na sequência, com ajuda do método withColumn(), uma nova coluna de delta pode ser criada através da subtração da temperatura atual (presente na base) e a temperatura anterior (obtida no janelamento).
Com essa abordagem, seria possível extrair, ainda, uma série de outros insights, como por exemplo, os maiores deltas de temperatura. Isto poderia indicar algum tipo de problema nos sensores ou algum erro pontual na fábrica que pudesse ser analisado pontualmente. Para esta aplicação, bastaria alterar a ordenação acima de timestamp para delta_temp mas, considerando o foco do artigo em janelamento, por que não criar um ranking de deltas em uma nova especificação de janela?
# Especificando janela com deltas positivos recebendo as primeiras posições
window_spec_ranking = Window\
.partitionBy("country", to_date(col("timestamp")))\
.orderBy(col("delta_temp").desc())\
.rowsBetween(Window.unboundedPreceding, Window.currentRow)
# Criando nova coluna com base em ranking
df_delta_temp_rank = df_delta_temp.withColumn("rank_delta_temp", rank().over(window_spec_ranking))\
# Visualizando resultado
df_delta_temp_rank\
.where(expr("country = 'United States' and to_date(timestamp) = '2015-11-25'"))\
.orderBy("rank_delta_temp")\
.show(15)
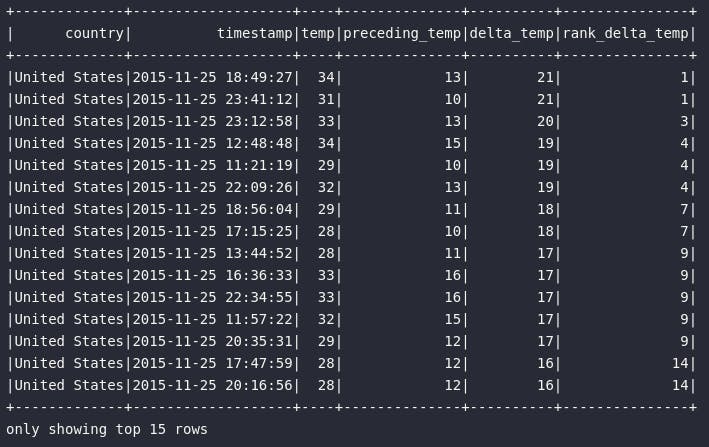
Como importantes pontos de atenção do resultado acima, é possível perceber que, em sensores localizados em fábricas dos Estados Unidos, às 18:49:27 do dia 25/11/2015, foi registrado o maior salto positivo de temperatura, partindo de 13º na medição anterior para 34º na medição atual.
Do outro lado do espectro, a função lead() possui um comportamento estritamente semelhante, porém com o objetivo de analisar valores posteriores ao registro atual de um DataFrame. De forma simples e direta, a consulta abaixo une estes dois mundos para proporcionar uma situação comparativa sobre quando e onde utilizá-las:
# Importando função
from pyspark.sql.functions import lag, lead
# Visualizando temperaturas anteriores e posteriores
df_delta_temp = df_iot.where(expr("country != ''")).select(
"country",
"timestamp",
"temp",
lag("temp", offset=1).over(window_spec).alias("preceding_temp"),
lead("temp", offset=1).over(window_spec).alias("following_temp")
)
# Visualizando resultado
df_delta_temp\
.where(expr("country = 'United States'"))\
.orderBy("timestamp")\
.show(10)
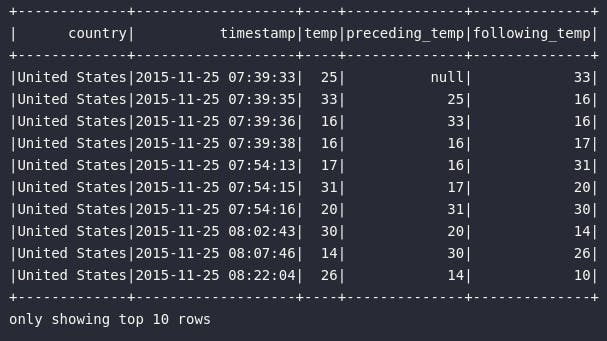
Existem, ainda, uma série de outras funções de janela categorizadas como analíticas que podem ser aplicadas para os mais variados propósitos. Para estas, não serão fornecidos exemplos práticos, entretanto é possível estabelecer que sua aplicação é estritamente semalhante às demonstrações já fornecidas neste artigo.
Agregações
Por fim, encerrando este vasto bloco de exemplificações sobre funções de janelamento, exemplos de agregações serão fornecidos para estabelecer, de forma definitiva, o grande dinamismo deste assunto em meio ao vasto universo de possibilidades.
Soma acumulada
O primeiro exemplo de janelamento envolvendo agregações diz respeito a um cenário onde deseja-se obter a soma acumulada de emissão de gás carbônico por país. Para isso, o bloco de código abaixo é responsável por definir uma especificação de janela particionada por país e ordenada por timestamp, considerando uma análise entre o registro atual e todos os registros anteriores:
# Importando função
from pyspark.sql.functions import sum
# Defindo janela
window_spec = Window\
.partitionBy("country", "date")\
.orderBy("timestamp")\
.rowsBetween(Window.unboundedPreceding, Window.currentRow)
# Retornando soma acumulada de emissão de gás carbônico por dia
df_c02_cumulative = df_iot.select(
"country",
"date",
"timestamp",
"c02_level",
sum("c02_level").over(window_spec).alias("cumulative_c02")
)
# Visualizando resultado
df_c02_cumulative\
.where(expr("country = 'United States'"))\
.orderBy("timestamp")\
.show(15)
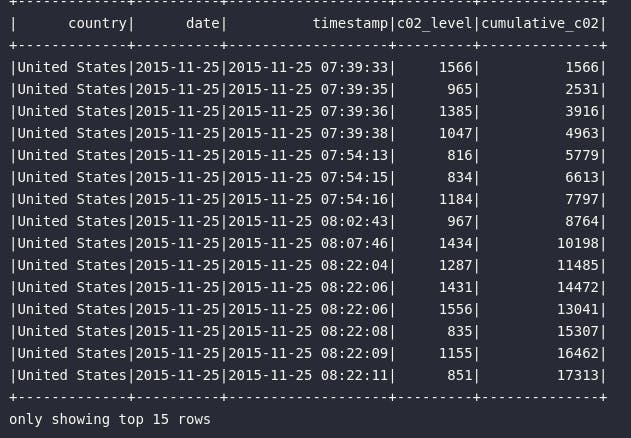
Através do resultado acima, é possível perceber como o nível de emissão de gás carbônico registrado em um determinado país e em uma determinada data cresce conforme os eventos registrados. Cenários deste tipo possuem grande valia para a retirada de insights e tomada de decisão.
Média móvel
A média móvel é, em sombra de dúvidas, um artifício estatístico de extremo valor em cenários analíticos . É comum observar casos de uso da média móvel para responder às mais variadas questões ou mesmo para acompanhar o comportamento de uma determinada variável numérica.
No exemplo abaixo, uma nova aplicação de operação de janelamento será proporcionada de modo a retornar a média móvel de temperatura, para cada país e em cada dia, a cada 3 medições registradas:
# Importando função
from pyspark.sql.functions import avg
# Definindo especificação de janela
window_spec_avg = Window\
.partitionBy("country", "date")\
.orderBy("timestamp")\
.rowsBetween(-2, Window.currentRow)
# Retornando a média móvel de temperatura
df_rolling_avg_temp = df_iot.select(
"country",
"date",
"timestamp",
"temp",
round(avg("temp").over(window_spec_avg), 2).alias("rolling_avg_temp")
)
# Visualizando resultado
df_rolling_avg_temp\
.where(expr("country = 'United States'"))\
.orderBy("timestamp")\
.show(15)
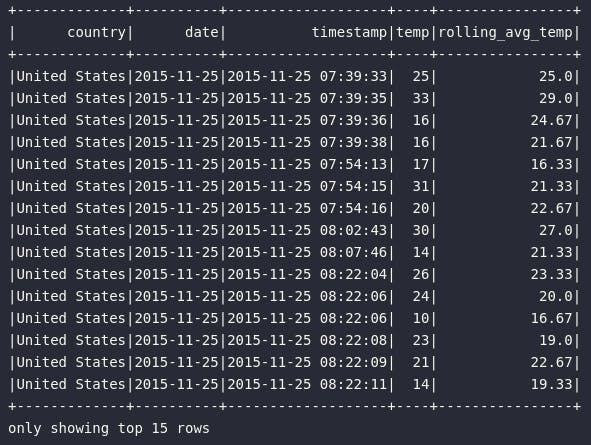
Como principal destaque, é possível notar como a especificação de janela foi construída para atender às necessidades estabelecidas: neste exemplo, ao invés de configurar uma janela que observa para todos os registros anteriores ao registro atual (.rowsBetween(Window.unboundedPreceding, Window.currentRow)), foi determinado uma restrição ao frame para considerar apenas os dois registros anteriores ao atual (.rowsBetween(-2, Window.currentRow)), configurando assim uma janela de três elementos para o posterior cálculo da média móvel.
Visando propor uma espécie de "validação dummy" ao cálculo da média e, aproveitando o momento para testar os conhecimentos nas funções de janela, o bloco de código abaixo serve para aplicar o mesmo cálculo acima referenciado, porém utilizando a função lag() com diferentes offsets de modo a ter em mãos os valores imediamente anteriores do registro atual para um cálculo manual da média móvel:
# Definindo especificação de janela para função lag
window_spec_lag = Window\
.partitionBy("country", "date")\
.orderBy("timestamp")
# Criando média móvel na mão via lag
df_avg_lag = df_iot.select(
"country",
"date",
"timestamp",
"temp",
lag("temp", offset=1).over(window_spec_lag).alias("temp_t1"),
lag("temp", offset=2).over(window_spec_lag).alias("temp_t2"),
round(avg("temp").over(window_spec_avg), 2).alias("window_rolling_avg")
).selectExpr(
"*",
"case when temp_t1 is null and temp_t2 is null then temp \
when temp_t1 is not null and temp_t2 is null then round((temp + temp_t1) / 2, 2) \
else round((temp + temp_t1 + temp_t2) / 3, 2) \
end as manual_rolling_avg"
)
# Visualizando resultado
df_avg_lag\
.where(expr("country = 'United States'"))\
.orderBy("timestamp")\
.show(15)
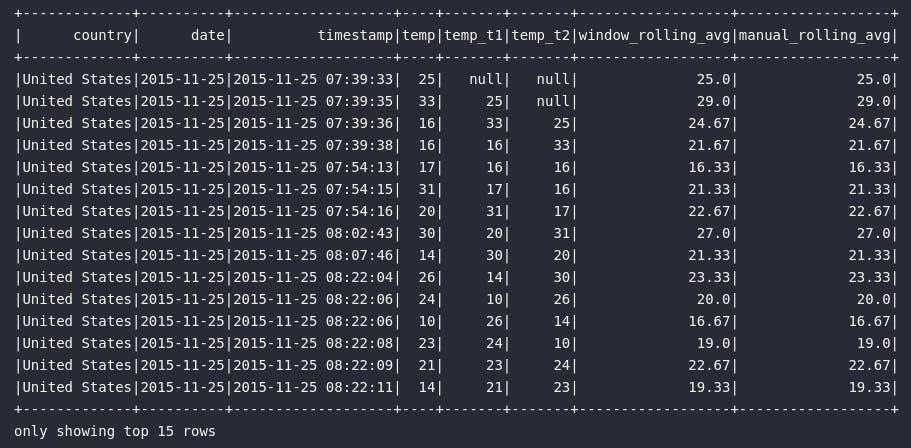
Com a igualdade entre os atributos window_rolling_avg (calculado a partir da função window) e manual_rolling_avg (calculado manualmente a partir da função lag), é possível perceber o quão trabalhoso seria obter este cálculo na mão.
Conclusão e encerramento
E assim, finalmente podemos dar como encerrada essa longa e extensiva jornada envolvendo o processo de janelamento no Spark. Por maiores que tenham sido os desafios e por mais cansativo que tenha sido esta leitura, foi possível navegar por uma série de exemplos práticos envolvendo as mais variadas funções de janela.
Com mais este conhecimento adquirido, um novo e gigantesco leque de possibilidades se abre para os usuários em meio a construção dos mais variados produtos de dados analíticos para melhores tomadas de decisões.
Espero que tenham gostado, caros leitores. Vejo vocês na próxima!
Referências
- pyspark.sql.Window
- pyspark.sql.Window.partitionBy
- pyspark.sql.Window.orderBy
- pyspark.sql.Window.rangeBetween
- pyspark.sql.Window.rowsBetween
- pyspark.Column.over
- pyspark.sql.functions.rank
- pyspark.sql.functions.dense_rank
- pyspark.sql.functions.percent_rank
- pyspark.sql.functions.ntile
- pyspark.sql.functions.row_number
- pyspark.sql.functions.lag
- pyspark.sql.functions.lead
- pyspark.sql.functions.monotonically_increasing_id
- Spark: The Definitive Guide
- Learning Spark - Lightning-Fast Data Analytics
- Spark By Examples - Pyspark Window Functions