




Olá, caro leitor! No segundo artigo desta série sobre o ecossistema Hadoop, foram abordados tópicos extremamente relevantes dentro do contexto de surgimento, difusão, adoção e evolução do Hadoop como uma solução open source para solucionar os mais variados problemas da era do Big Data.
Em sua concessão, o Hadoop contou com três elementos fundamentais como grandes alicerces de suas funcionalidades relacionadas ao armazenamento e processamento distribuído de grandes quantidades de dados, sendo eles:
| Componente | Descrição |
| HDFS (Hadoop Distributed File System) | Sistema de armazenamento distribuído do Hadoop |
| MapReduce | Modelo de programação baseado em mappers e reducers |
| YARN (Yet Another Resource Negotiator | Gerenciador de recursos do cluster Hadoop |
Nesta próxima sequência de três artigos, serão fornecidos detalhes adicionais sobre cada um dos três componentes acima listados em prol de um maior entendimento sobre o funcionamento do Hadoop, a iniciar pelo HDFS. Aperte o cinto e prepare-se para compreender termos antes considerados misteriosos em sua jornada de aprendizado!
O Armazenamento de Big Data
Antes de arriscar um maior aprofundamento técnico, convido o leitor a imaginar um cenário onde seja necessário armazenar um volume de dados superior ao que pode ser comportado por uma única máquina. Em outras palavras, o desafio imaginário contempla a existência de um arquivo de texto de 50 Terabytes de volume que precisa ser armazenado e posteriormente transformado em busca de novos insights dentro de uma companhia. Se, por ventura, esta parece uma tarefa complexa em um cenário clássico de análise de dados é porque, de certa forma, sua solução está pautada pelos conceitos estabelecidos na era do Big Data.
De forma direta, este massivo conjunto de dados não pode ser comportado por discos rígidos (HDs) ou drivers de estado sólido (SSDs) com a tecnologia existente até o momento de escrita deste artigo. Por maiores que sejam os avanços relacionados ao armazenamento de dados, existem grandezas que exigem uma nova abordagem para que se tornem eficientes dentro dos requisitos intrínsecos existentes. Assim, na impossibilidade de armazenar grandes volumes em uma única máquina, a resposta mais objetiva possível é a utilização de múltiplas máquinas capazes de comportar, cada uma, uma parcela (ou uma partição) do arquivo de dados. De maneira simplificada, à esta organização de múltiplas máquinas dá-se o nome de cluster.

Sistematicamente, o Hadoop contribui para soluções de armazenamento de grandes quantidades de dados através do HDFS: o Hadoop Distributed Filesystem. Com este componente, volumes massivos de dados são armazenados de forma distribuída em um cluster de computadores, permitindo a construção de soluções viáveis, sustentáveis e de alta disponibilidade para as mais variadas cargas de trabalho no universo do Big Data.
O Sistema de Armazenamento Distribuído do Hadoop
Dado um contexto geral sobre as principais motivações em armazenar grandes quantidades de dados de maneira distribuída, é chegado o momento de aprofundar os conhecimentos em um dos principais componentes do ecossistema Hadoop: seu sistema de armazenamento distribuído.
O livro Hadoop: the Definitive Guide de Tom White define o HDFS como:
O HDFS é um sistema de arquivos construído para armazenar grandes quantidades de dados com acesso através de padrões de streaming executado em clusters de hardware commodity.
Separando alguns elementos fundamentais desta definição, tem-se:
"Grandes quantidades de dados:" como exemplificado no início deste artigo, este é o elemento fundamental para a existência de sistemas de armazenamento distribuído. Os desafios começam quando não é mais possível utilizar abordagens clássicas para solucionar problemas de Big Data.
"Padrões de streaming:" o HDFS é construído através de uma ideia write once/read many que, por sua vez, indica um padrão de utilização onde os usuários realizam a escrita de grandes quantidades de dados uma única vez e realizam a leitura múltiplas vezes. Neste cenário, o tempo para leitura de todo o conjunto de dados é mais importante do que a latência em ler o primeiro registro.
"Hardware commodity:" o Hadoop não exige que o cluster de computadores seja formado por máquinas potentes com altas especificações técnicas. Esta é uma de suas principais vantagens pois, considerando seus elementos de replicação e alta disponibilidade, é possível construir toda sua arquitetura utilizando hardwares de baixo custo.
Tão importante quanto definir e destacar os principais elementos que compõem uma descrição completa do HDFS, é também proporcionar uma visão clara sobre cenários onde seu uso não é adequado:
- Padrões de acesso com baixa latência
- Existência de small files
- Grande quantidade de modificações em arquivos
Uma vez formalizado o entendimento geral sobre o HDFS, é preciso compreender como os grandes volumes são, de fato, armazenados em um cluster de computadores.
Blocos de Armazenamento
O primeiro grande conceito por trás do armazenamento distribuído de grandes conjuntos de dados no Hadoop está atrelado ao fatiamento em blocos. Em essência, o HDFS possui blocos de armazenamento de 128MB (ou 256MB em alguns cenários), canalizando o posicionamento de um grande volume de dados em chunks proporcionais ao tamanho do bloco. A imagem abaixo, extraída do vídeo Hadoop in 5 minutes, exemplifica um cenário ilustrativo de um arquivo de 600MB armazenado no HDFS. Nela, cada retângulo representa um nó no cluster Hadoop o que, de forma genérica, é análogo a um bloco de 128MB (considerando um cluster com este tamanho de bloco).
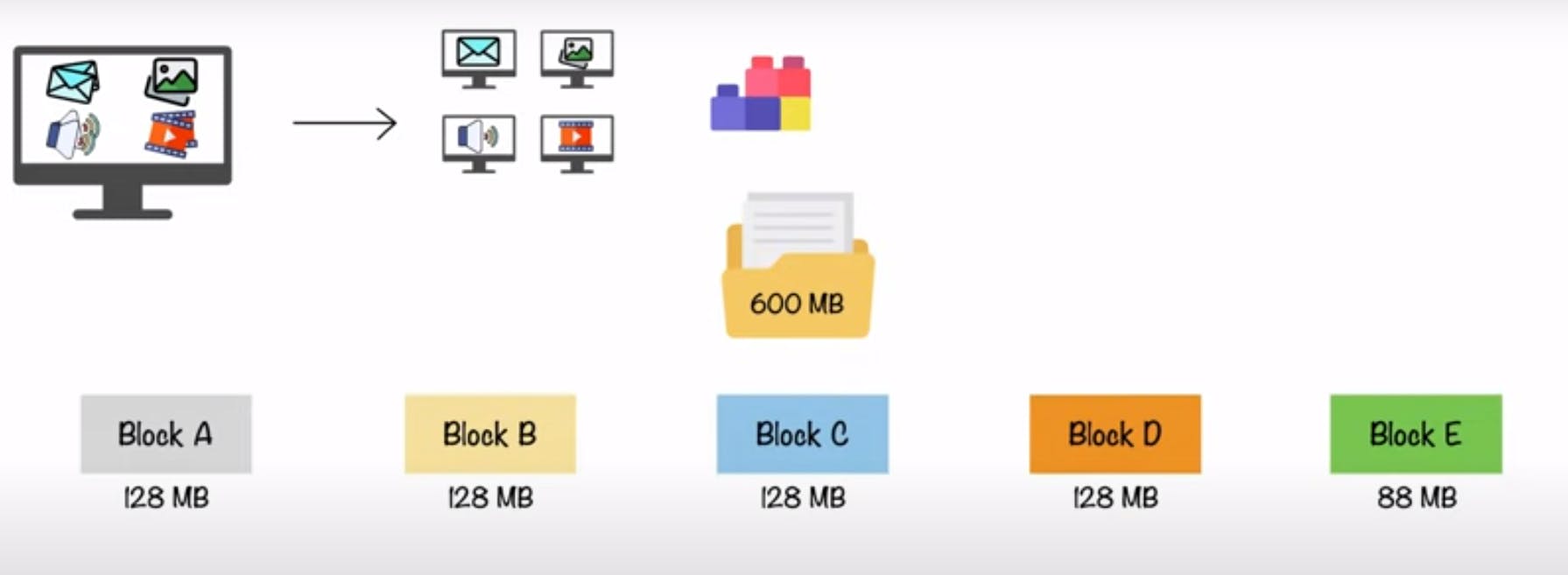
Neste cenário, o arquivo de 600MB é separado em chunks de 128MB e armazenado em diferentes nós do cluster de computadores. O volume restante (88MB) é armazenado em um último bloco, evidenciando assim o conceito de que é possível armazenar volumes de dados menores do que o tamanho do bloco configurado. Entretanto, é importante citar que, de acordo com o cenário, o armazenamento de um arquivo pouco volumoso espalhado em vários nós pode ocasionar um famoso problema conhecido como small files.
Possuir uma abstração de blocos em um sistema de armazenamento distribuído é interessante pois:
- É possível armazenar um arquivo maior do que qualquer volume individual de disco
- Informações de metadados podem ser trabalhadas por outros sistemas externos
- A abordagem em blocos trabalha bem com tolerância à falhas e alta disponibilidade
E é na linha do terceiro ponto de vantagem acima listado que a próxima seção tem início.
Replicação de Dados no Cluster
Até este ponto, foi possível entender como o HDFS atua em prol do armazenamento de grandes quantidades de dados a partir de chunks vinculados a blocos (ou nós) no cluster de computadores. Imaginando que cada fatia de um volume massivo de dados está presente em uma máquina física em algum rack de servidores, o que pode acontecer com o conjunto geral de dados caso esta máquina falhe? Os dados serão comprometidos por completo?
Essas duas perguntas são respondidas com uma das principais vantagens do HDFS: seu sistema de replicação.
Por padrão, sempre que um grande volume de dados é armazenado no cluster de computadores, existe um fator de replicação que automaticamente realiza cópias dos blocos em múltiplos nós do sistema. De forma ilustrativa, a imagem abaixo traz uma continuação da ilustração de armazenamento em blocos dentro do contexto de replicação.
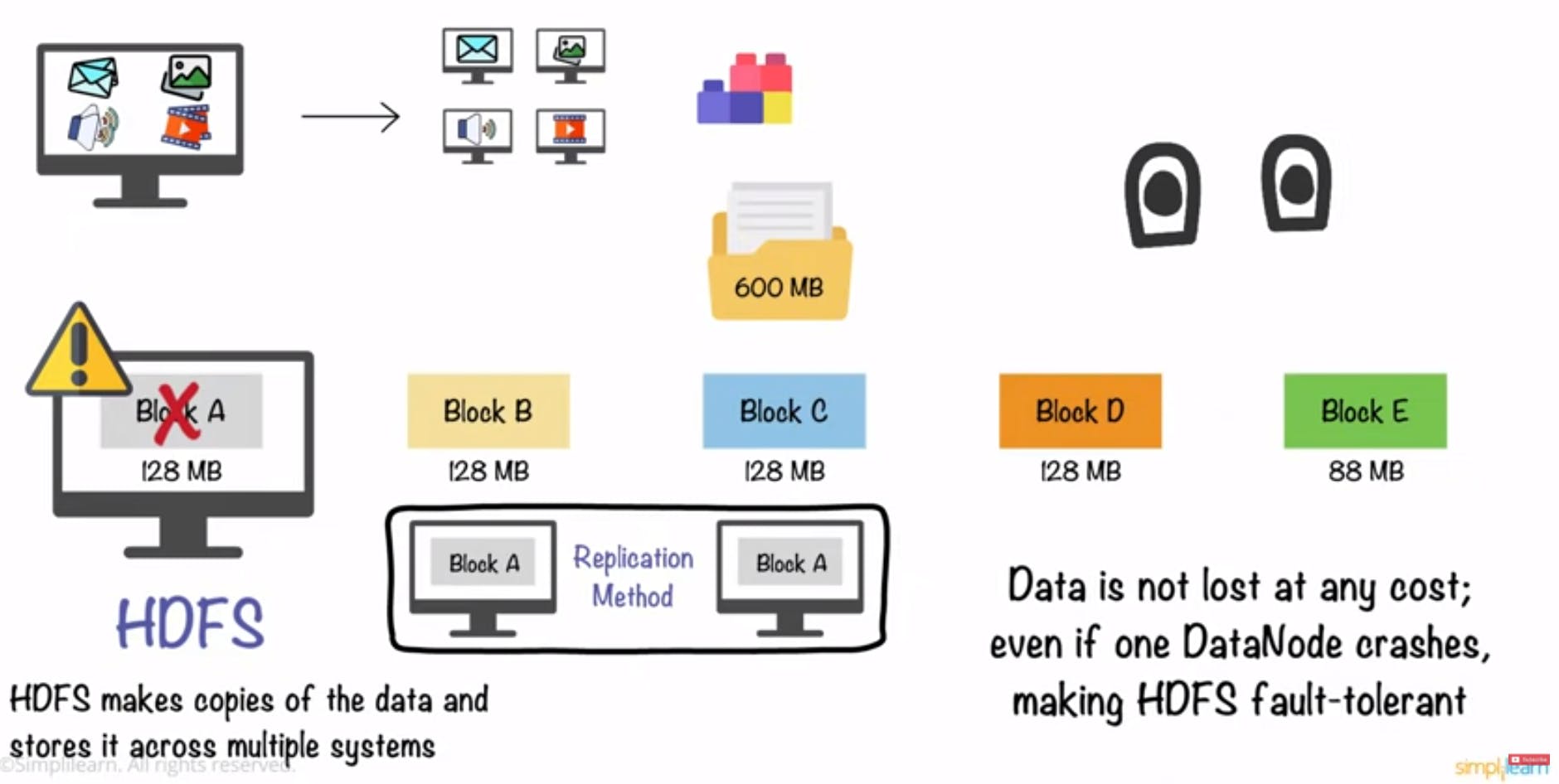
Assim, se um computador do cluster Hadoop falhar, o HDFS automaticamente irá garantir que os dados solicitados pela requisição serão retornados através de uma fonte alternativa de replicação.
Arquitetura do HDFS
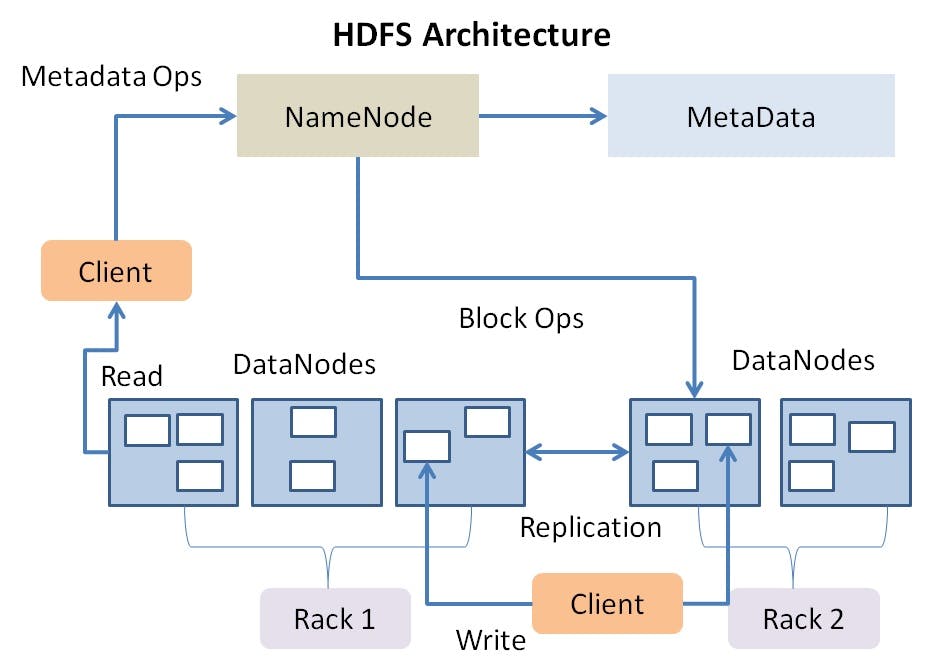
Considerando um cluster Hadoop para o armazenamento distribuído, alguns componentes se fazem presentes para diferenciar nós do sistema em meio a suas funções e responsabilidades. Quando um client realiza uma requisição ao cluster Hadoop, estará eventualmente interagindo com diferentes tipos de nós do sistema que atuam em um padrão master-worker, sendo eles:
- Namenodes (master): gerencia toda a árvore do sistema de armazenamento e os metadados para todos os arquivos e diretórios presentes. Os namenodes mantém um arquivo conhecido como edit log responsável por registrar informações sobre o que é criado, mantido ou alterado no cluster. Além disso, possuem informações de todos os datanodes do sistema.
- Datanodes (worker): atuam como os verdadeiros trabalhadores do cluster. São eles quem armazenam os dados em blocos e retornam, sempre que solicitados, informações para o namenode para que este saiba exatamente a localização dos arquivos.
Dessa forma, um "nó" em um cluster Hadoop pode ser tanto um namenode quanto um datanode, cada um com seus respectivos papéis e responsabilidades. A imagem abaixo, extraída do Google, fornece uma visão clara sobre a dinâmica de requisições no HDFS. Nela, um client (usuário utilizando uma aplicação integrada ao Hadoop) pode realizar operações de leitura e escrita de dados no HDFS. Na leitura, o client contata o namenode em busca de informações relacionadas à localização dos blocos dos dados solicitados, obtendo posteriormente os dados solicitados através de uma requisição aos datanodes específicos. Na escrita, o client aciona os datanodes para armazenamento do volume de dados em blocos para que estes últimos possam, posteriormente, informar o namenode sobre a localidade do novo conteúdo inserido.
Recuperação à Falhas
Considerando a arquitetura demonstrada, é possível constatar que o namenode é um ponto crítico de falha do sistema. Sua inexistência impede por completo a utilização do HDFS, visto a impossibilidade de obter informações de metadados e localidade dos dados nos blocos presentes nos datanodes do cluster.
No livro Hadoop: the Definitive Guide e no excelente curso de Hadoop disponibilizado na Udemy por Frank Kane, conceitos sobre a estruturação do HDFS para contornar pontos de falha podem ser visualizados em detalhes. Para uma visão geral, existem algumas ações que podem ser tomadas, incluindo:
Realizar o backup dos metadados: visto que o namenode é o responsável por gerenciar os metadados do sistema, realizar backups periódicos locais ou em um outros sistemas de arquivos pode ser uma ação relevante para retomar a operação em caso de falhas. Nesta abordagem, eventualmente alguns dados serão perdidos, dado que a retomada do sistema pode ter algum delay.
Manter um secondary namenode: neste contexto, apesar do nome intuitivo, não há um namenode secundário executando ao mesmo tempo que o primário. Basicamente, cópias dos arquivos importantes do namenode são mantidas em uma máquina separada no cluster para que, em eventuais falhas, o sistema possa ser recuparado.
Considerações Finais
Por mais densa que tenha sido esta leitura, obter um conhecimento básico sobre a estrutura do HDFS é algo fundamental dentro da jornada de aprendizado do Hadoop. Afinal, o armazenamento distribuído pode ser considerado como um dos primeiros passos dentro dos propósitos de atuação no universo de Big Data.
Quando procura-se informações sobre o Hadoop e o HDFS, certamente são encontradas definições sobre cluster, namenode, datanode, blocos, replicação e outros termos. Compreender o significado de cada um deles é um conhecimento fundamental e de grande valia.
Nos próximos artigos, serão trazidos detalhes sobre os demais componentes fundamentais do Hadoop: o MapReduce e o YARN. Até a próxima!