




Bem-vindos a mais um artigo da série "Visão Geral sobre o Ecossistema Hadoop"! Nesta jornada, conceitos sobre o MapReduce serão introduzidos de modo a propor um entendimento panorâmico sobre o processamento de grandes quantidades de dados.
Parte de uma sequência de três artigos com o objetivo de detalhar os principais componentes do Hadoop, o conteúdo aqui alocado atua como complemento aos tópicos consolidados no artigo anterior, onde detalhes sobre o HDFS foram trazidos à tona no contexto de armazenamento de grandes volumes de dados. Por fim, em um artigo posterior, definições do YARN serão fornecidas para completar a tríade do Hadoop Core.
| Componente | Resumo | Artigo |
| HDFS | Sistema de armazenamento distribuído do Hadoop | Link |
| MapReduce | Modelo de programação para processamento paralelo | Este artigo |
| YARN | Gerenciador de recursos do cluster Hadoop | Próximo artigo |
Contexto do Processamento de Big Data
Em cenários de Big Data, o armazenamento de grandes volumes de dados é normalmente realizado em um cluster de computadores utilizando um sistema distribuído, como o HDFS ou o Amazon S3. Entretanto, armazenar os dados é apenas a primeira etapa da construção de um pipeline de transformação e análise. É preciso considerar a existência de um modelo capaz de processar os conjuntos armazenados em diferentes computadores de uma forma escalável, resiliente e veloz.
Na especialização Modern Big Data Analysis disponível no Coursera, Glynn Durham e Ian Cook realizam uma interessante comparação do tempo gasto para ler diferentes quantidades de dados utilizando sistemas clássicos como, por exemplos, HDs e SSDs.
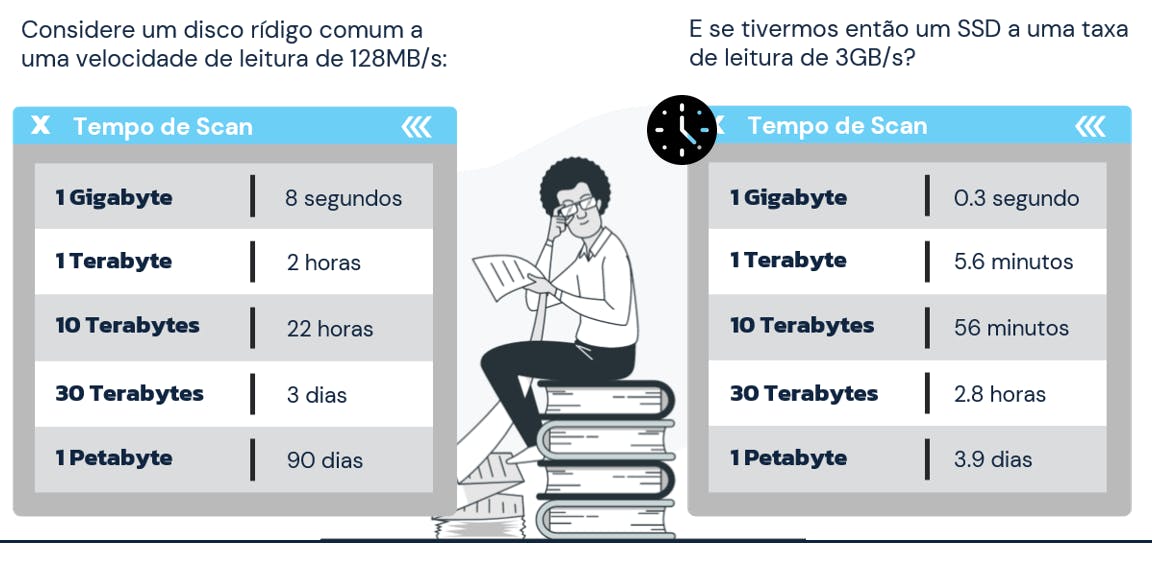
O resultado é surpreendente: quando a escala dos dados beira os Petabytes (cenário relativamente comum em Big Data), o tempo de leitura pode chegar a quase uma centena de dias com um disco rígido de 128MB/s. Mesmo considerando um SSD com uma taxa de leitura de 3GB/s, o mesmo conjunto de dados é processado em praticamente 4 dias! Definitivamente, um único motor de leitura é insuficiente para comportar as necessidades do mundo moderno.
Fato é que a capacidade de armazenamento de discos aumentou de forma significativa nos últimos anos. O mesmo, porém, não pode ser dito sobre suas taxas de leitura. O livro Hadoop: the Definitive Guide exemplifica que, em 1990, um disco rígido padrão poderia armazenar em torno de 1.370MB de dados a uma taxa de leitura de 4,4MB/s, permitindo assim uma varredura completa do disco em um tempo próximo a 5 minutos. Aproximadamente 20 anos depois, o armazenamento comum em discos atinge uma escala de Terabytes quando, ao mesmo tempo, suas taxas de leitura alcançam velocidades em torno de 100MB/s e, nessa relação desproporcional, o tempo para a leitura completa de um disco é agora um processo de horas.
Assim, unindo as necessidades de extração de valor de grandes conjuntos de dados em um cenário factível e tempestivo, faz-se presente um modelo de programação capaz de processar os dados utilizando múltiplos processadores em um cluster de computadores. Nasce então o MapReduce.
Mapeamento e Redução
Imaginar uma forma de processar dados de forma paralela é desafiador. Um dos principais obstáculos presentes neste processo gira em torno da necessidade de combinar, de alguma forma, dados que estão armazenados em diferentes blocos e em diferentes nós de um grande conjunto de computadores.
O MapReduce surge como uma grande solução para os mais variados desafios no contexto de processamento de dados de maneira distribuída. Seu funcionamento está basicamente vinculado a funções de map (mapeamento) e reduce (redução) que utilizam entradas e saídas baseadas em conjuntos de chave e valor. Cada uma destas etapas possuem responsabilidades específicas na dinâmica de processamento dos dados:
| Função | Atuação Simplificada |
| Map | Funções de mapeamento são normalmente utilizadas para filtrar, transformar ou converter os dados |
| Reduce | Já as funções de redução, atuam na sumarização e agregação dos dados |
Como forma de ilustrar uma aplicação prática de um processo de MapReduce, um exemplo retirado da especialização Modern Big Data Analysis disponível no Coursera será utilizado dentro do objetivo de retornar uma análise de dados aplicada a uma base de vendas. Neste contexto, espera-se obter uma totalização de vendas para cada vendedor presente na base que, por sua vez, possui as seguintes características:
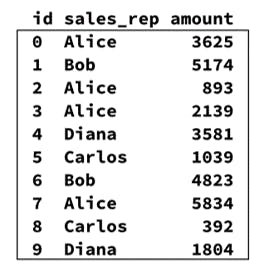
Em um cenário explicativo, os dados acima apresentados estão armazenados no HDFS e um job (programa) de MapReduce é submetido de modo a calcular a totalização de vendas por vendedor. De forma ilustrativa, o diagrama dos processos realizados no cluster Hadoop pode ser visualizado através da figura abaixo:
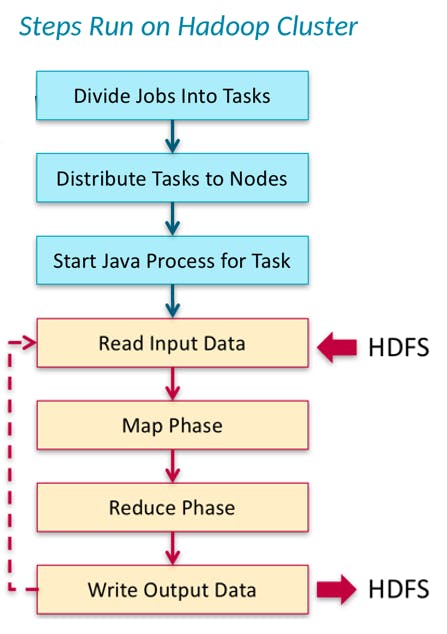
Antes de iniciar o detalhamento, é importante destacar que, no exemplo considerado:
- Os jobs (programas) submetidos no cluster Hadoop são divididos em tasks (tarefas)
- As tasks são então distribuídas para os nós do cluster
- Processos em Java são inicializados para o processamento dos dados
- Neste ponto, dados do sistema distribuído (HDFS) são lidos conforme a requisição
- Inicia-se a fase de mapeamento de acordo com a solicitação realizada
- A saída da fase de mapeamento é então submetida a uma fase de redução, conforme a solicitação realizada
- O resultado final é escrito novamente no HDFS
Dessa forma, as seções subsequentes irão alocar detalhes sobre as fases de mapeamento e redução realizadas no cluster Hadoop para retornar os dados requisitados neste exemplo de totalização de vendas por vendedor.
Fase de Map
Na fase de map do processo, cada task individual recebe uma porção dos dados. Neste momento, é preciso lembrar que o conjunto de dados está armazenado de maneira distribuída em diferentes blocos e em diferentes nós em um cluster de computadores. Assim, o número de tasks estabelecidas pelo sistema para atuar no job depende da quantidade de dados utilizada no processo.
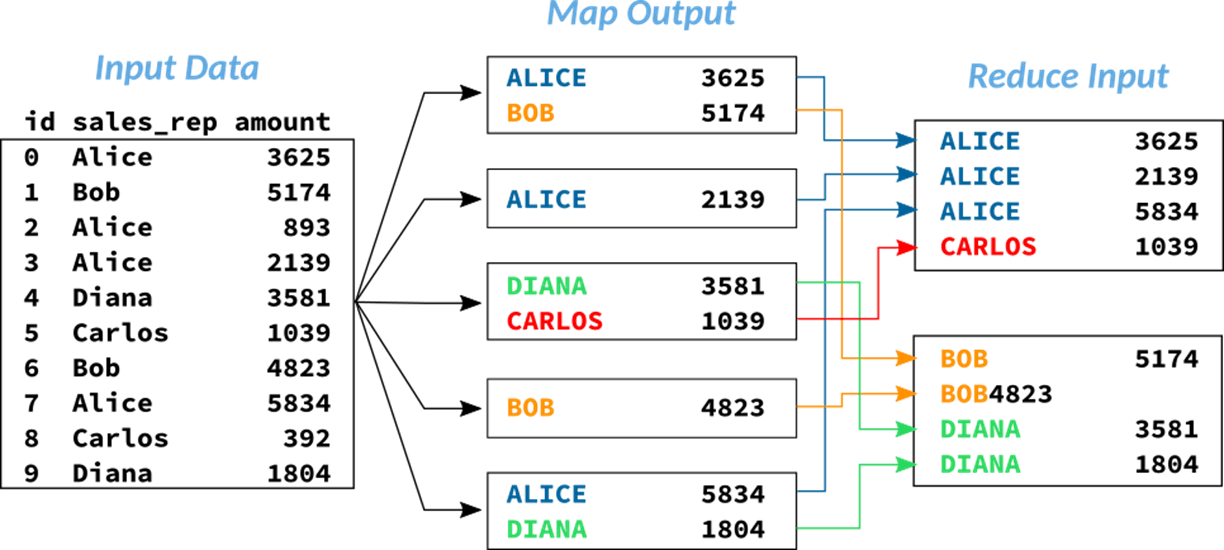
No exemplo considerado, a função map seleciona exclusivamente as colunas necessárias para o retorno do resultado. Na figura abaixo, é possível perceber que a saída do mapeamento contempla apenas as colunas sales_rep e amount, dado que o objetivo é somar a quantidade de vendas (amount) por vendedor (sales_rep). Neste caso, o atributo id não é necessário e, portanto, desconsiderado na fase de mapeamento.

Se houvesse algum filtro considerado no objetivo de análise (como por exemplo, a totalização de vendas para um vendedor em específico), este também seria aplicado na fase de map. Como reforço, é nesta fase que filtros, seleções ou conversões de dados são realizadas em um cenário de um para um.
Na sequência, a solicitação passa por um processo importante chamado de shuffle and sort antes de chegar à fase de redução.
Shuffle and Sort
Em alguns casos, a saída de uma tarefa de map passa por um processo intermediário chamado de shuffle and sort. Esta etapa é responsável por unificar dados de todas as tarefas de map executadas em cada nó do cluster de modo a criar um input facilitado para a subsequente tarefa de reduce.
Na figura abaixo, é possível perceber como os dados dos mesmos vendedores são consolidados e unificados em nós iguais. Sempre reforçando o contexto paralelo de armazenamento e processamento, é importante lembrar que os dados originais estão literalmente "espalhados" em diversas localidades. Unificar dados similares facilita e acelera o processo de obtenção dos resultados.
Fase de Reduce
Por fim, para calcular a soma de vendas por vendedor, a fase de reduce se faz presente. É nesta etapa onde são executadas as agregações e sumarizações dos dados, tendo seus resultados unificados para proporcionar uma sáida final.
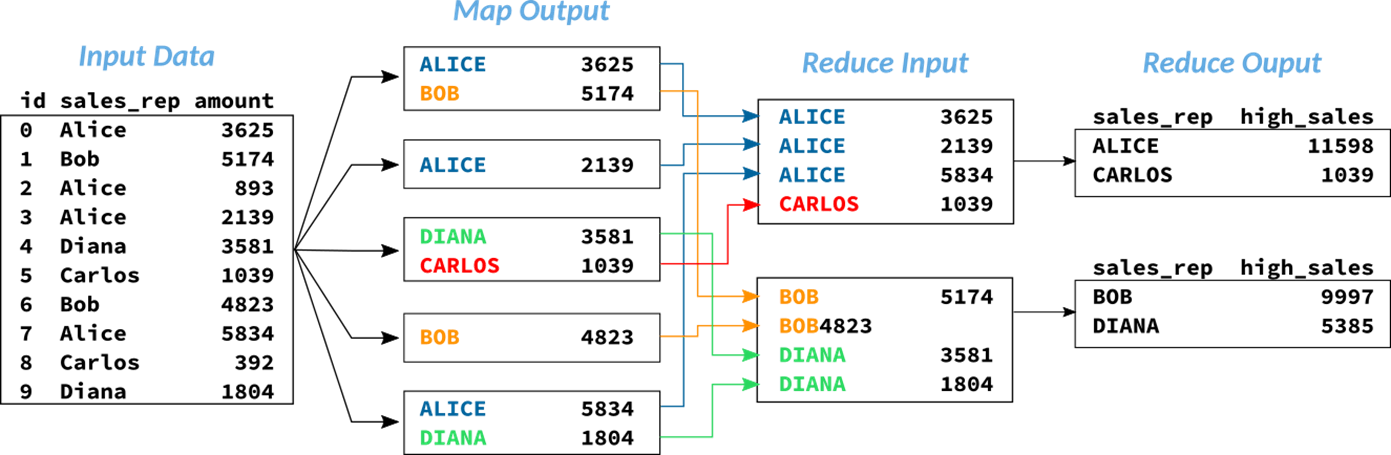
Os processos de map, shuffle and sort e reduce ocorrem dentro da dinâmica distribuída de processamento em diferentes máquinas. Cabe ao usuário programar um código baseado nas funções de mapeamento e redução utilizando uma linguagem compatível, como Java ou Python, por exemplo. Com o avanço das tecnologias no ecossistema Hadoop, este processo está cada vez mais simples, permitindo que o usuário utilize motores como Hive capazes de traduzir queries SQL em jobs de MapReduce.
Outros Exemplos Práticos de MapReduce
De modo a consolidar o entendimento sobre as etapas de mapeamento e redução, referências distintas foram consultadas de modo a obter aplicações práticas a serem utilizadas como exemplo. Nos tópicos a seguir, cenários alternativos de uso do MapReduce serão fornecidos em diferentes contextos, permitindo assim a obtenção de uma noção mais clara sobre este modelo.
Movie Ratings
No exemplo extraído do curso de Hadoop disponibilizado na Udemy por Frank Kane (Sundog Education), uma base de avaliação de filmes é utilizada como insumo para obter a relação de usuários que mais forneceram notas a filmes. Neste contexto, a base de entrada possui as seguintes características:
USER ID: Identificação do usuário que avaliou o filmeMOVIE ID: Identificação do filme avaliado pelo usuárioRATING: Avaliação fornecida pelo usuário a determinado filmeTIMESTAMP: Marcador temporal da avaliação (não utilizado no processo)
Assim, propondo a utilização do MapReduce para extrair a quantidade de filmes avaliados por cada usuário, o cenário envolvendo as fases de map, shuffle and sort e reduce podem ser ilustradas através da seguinte imagem:
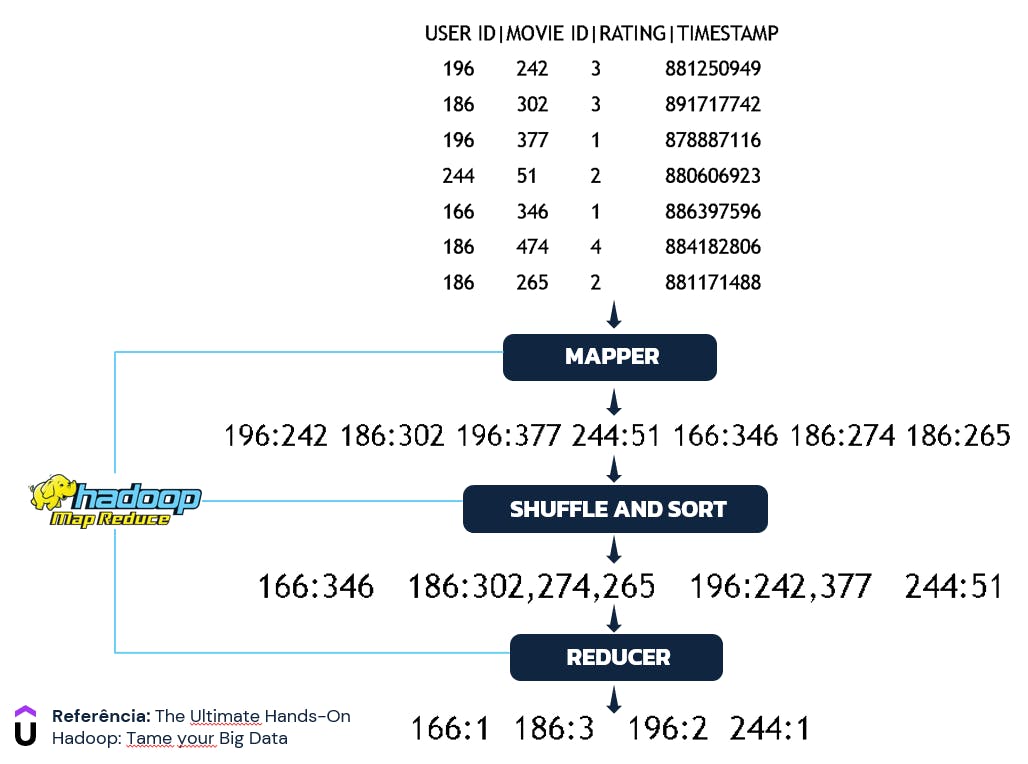
Detalhando o processo, a fase de map comporta a seleção das colunas USER ID e MOVIE ID em um formato de chave-valor. Como abordado anteriormente, esta é a fase responsável por selecionar, filtrar ou converter os dados e, considerando a proposta de contagem de filmes avaliados por cada usuário, a consolidação destas duas variáveis é perfeitamente suficiente para o andamento da solicitação.
Na sequência, a fase de shuffle and sort realiza a unificação dos conteúdos de um mesmo grupo. Neste contexto, valores (filmes) são consolidados em suas respectivas chaves (usuários), permitindo assim um input facilitado para a próxima fase do processo.
Por fim, com os dados separados e unificados, a fase reduce tem o exclusivo papel de agregar os valores nas chaves, obtendo assim o resultado final de contagem de filmes avaliados para cada usuário.
Contagem de Palavras
Um exemplo clássico na literatura de MapReduce é, sem dúvidas, a contagem de palavras. Em um trecho do vídeo Hadoop in 5 minutes, um texto é utilizado como entrada para as etapas de mapeamento, shuffle and sort e redução com o objetivo de realizar uma contagem de cada uma das palavras presentes. De uma só vez, o diagrama desta implementação pode ser visualizado na imagem abaixo:
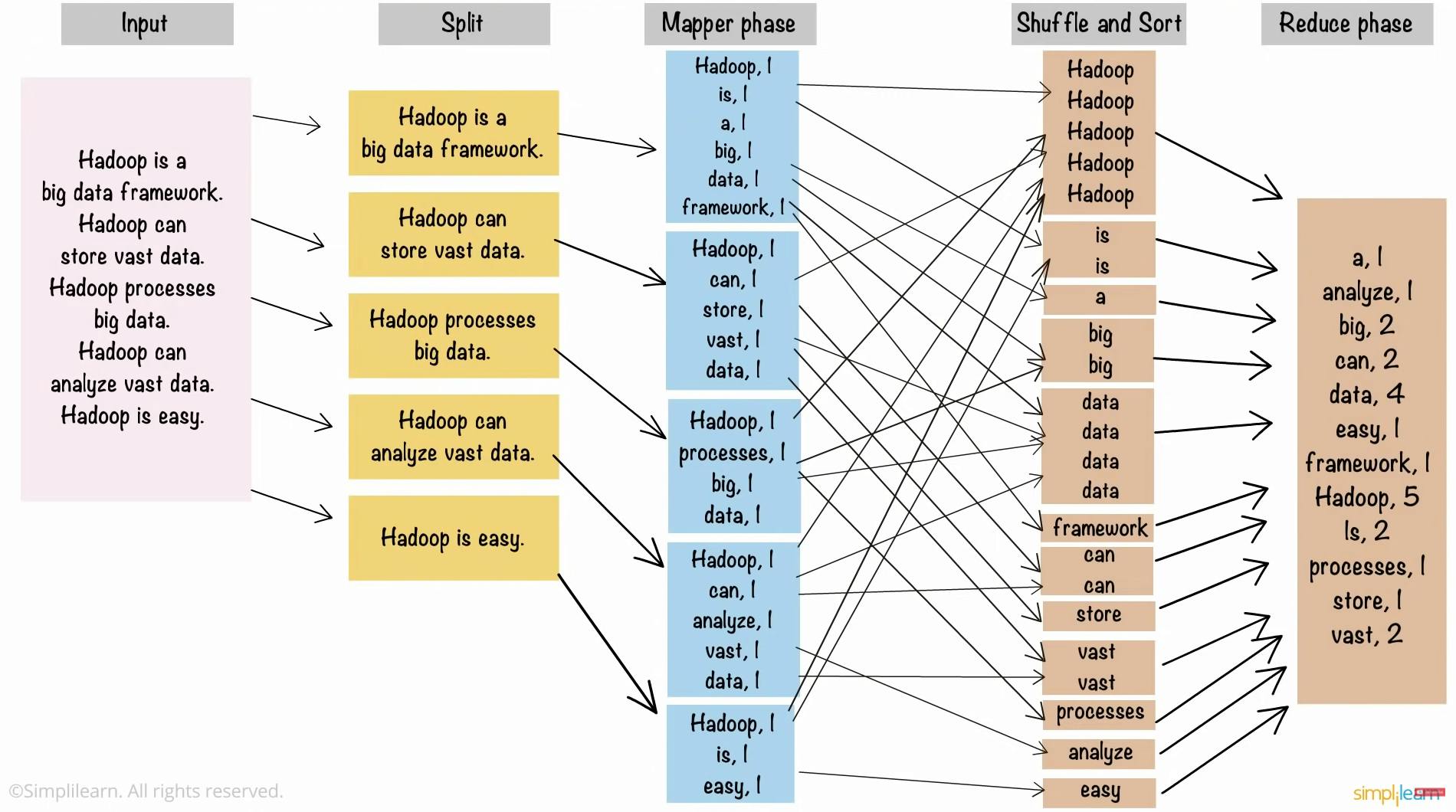
Assim como nos demais processos exemplificados neste artigo, todo o processamento é realizado em diferentes nós de um cluster de computadores. Não obstante a este fato, as fases de map, shuffle and sort e reduce possuem os mesmos comportamentos já reforçados ao longo do processo evolutivo de aprendizado.
Um Exemplo Prático de Programa
Até este ponto, muitos diagramas visuais foram fornecidos para um entendimento do funcionamento de jobs de MapReduce no cluster Hadoop. Entretanto, é importante ter uma noção clara sobre as maneiras de solicitar tais execuções no contexto de submissão dos jobs que visam retornar resultados atrelados ao processamento paralelo de dados.
Em mais uma referência ao curso de Hadoop disponibilizado na Udemy por Frank Kane (Sundog Education), o trecho de código abaixo utiliza a linguagem Python para programar um job de MapReduce responsável por retornar uma contagem de filmes avaliados para cada nota de avaliação. Em outras palavras, é esperado obter um resultado que indique quantas avaliações foram fornecidas para cada uma das notas presentes (de 1 a 5).
from mrjob.job import MRJob
from mrjob.step import MRStep
class RatingsBreakdown(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper_get_ratings,
reducer=self.reducer_count_ratings)
]
def mapper_get_ratings(self, _, line):
(userID, movieID, rating, timestamp) = line.split('\t')
yield rating, 1
def reducer_count_ratings(self, key, values):
yield key, sum(values)
if __name__=='__main__':
RatingsBreakdown.run()
Em linhas gerais, o código acima comporta a utilização da biblioteca mrjob como forma de consolidar os paradigmas necessários para a criação de um job MapReduce em Python. De forma estrutural, a classe RatingBreakdown() herda o elemento MRJob de modo a ganhar funcionalidades adicionais relacionadas ao MapReduce. A construção desta classe está basicamente baseada em duas funções: uma de map (mapper_get_ratings()) e outra de reduce (reducer_count_ratings()), cada uma atuando de maneira específica e de acordo com suas especificidades e papéis.
Na função de mapeamento, o conjunto de dados é obtido como uma linha única, referenciado pela variável line. Neste cenário, é possível concluir que os dados estão separados por tabulação e, dessa forma, cada campo é obtido individualmente através da execução do método split() na linha fornecida como entrada. O retorno da função de map é basicamente a coluna de avaliação (rating) e o numeral 1, dado que o objetivo final é apenas realizar uma contagem.
Na função de redução, o conjunto de chave (avaliação) e valor (numeral 1) são sumarizados através da função sum() e retornados também como um conjunto de chave (avaliação) e valor (total de filmes avaliados).
Como forma de formalizar a execução destas etapas, a classe RatingsBreakdown considera um método steps() responsável por utilizar a classe MRStep junto das funções de mapeamento (argumento mapper) e redução (argumento reducer).
Assim, ao submeter este script Python em um cluster Hadoop passando a localização dos dados de entrada como parâmetro, o resultado final será obtido utilizando o mais puro modelo de programação baseado no MapReduce.
Estado da Arte de Utilização do MapReduce
Observando o exemplo anterior, é notório que a aplicação prática de MapReduce pode exigir um conhecimento relativamente complexo na programação de jobs. A complexidade escala ainda mais em solicitações envolvendo transformações avançadas ou até mesmo joins.
Como forma de facilitar a utilização do MapReduce em cenários de Big Data, diversas ferramentas foram construídas e inseridas dentro do ecossistema Hadoop. O caso mais clássico é o Apache Hive que, conforme citado anteriormente neste artigo, permite que o usuário programe em SQL para obter resultados analíticos de dados armazenados no HDFS sem a necessidade de programar códigos complexos em Java, Python ou Scala. Este, porém, é um assunto para uma outra série deste blog.
Considerações Finais
Uma jornada longa requer uma finalização direta. Conhecer detalhes sobre o MapReduce é, sem dúvidas, um diferencial no contexto de aplicações no universo do Big Data.
Espero que os elementos contidos neste artigo tenham tornado sua jornada de aprendizado ainda mais animadora. Por mais complexo e denso que tenha sido, o entendimento do funcionamento do MapReduce atua como um grande divisor de águas no cenário distribuído de processamento de grandes conjuntos de dados.
No próximo artigo, tocaremos no YARN para entender como o cluster Hadoop gerencia os recursos em meio a requisições de armazenamento ou processamento de dados.