

Instalando e Configurando o Ambiente Hadoop

“Instalar e executar os componentes principais do Hadoop, como HDFS, MapReduce e YARN em uma única máquina pode ser um feito extremamente interessante para aprendizado. […] O Hadoop foi desenvolvido para ser executado em hardware commodity, ou seja, não é necessário possuir computadores “potentes” para se aproveitar de suas funcionalidades.”
Traduzido do livro Hadoop - The Definitive Guide de Tom White
Bem-vindos a mais um artigo da série "Visão Geral sobre o Ecossistema Hadoop"! Após uma jornada sensacional de aprimoramento teórico em alguns componentes básicos do Hadoop, é chegado o grande momento de iniciarmos as atividades práticas para, finalmente, poder observar a integração entre as partes em um ambiente distribuído de armazenamento e processamento de dados.
Modos de Instalação do Hadoop
O Hadoop possui diferentes modos de instalação, sendo eles:
Standalone (ou local mode): modo de instalação em um único nó onde o Hadoop utiliza o próprio sistema de arquivos da máquina do usuário para armazenar dados. Este modo é normalmente utilizado para propósitos de debugging.
Pseudo distributed (ou single node cluster): também considera a instalação do Hadoop em um único nó, porém, diferente do modo standalone, o pseudo-distribuído simula um cluster de computadores a partir da execução dos daemons do Hadoop em processos diferentes. Em outras palavras, mesmo que elementos como namenode, datanode e resource manager estejam instalados todos na mesma máquina de trabalho, para cada um deles, uma JVM diferente é iniciada. Neste caso, o fator de replicação do HDFS deve ser configurado para 1.
Fully Distributed: Este é o modo de instalação do Hadoop encontrado em ambientes produtivos onde múltiplos nós estarão em execução ao mesmo tempo.
Assim, a grande proposta deste artigo é realizar a instalação e configuração do ambiente Hadoop no modo pseudo-distribuído em uma máquina virtual Ubuntu pré instalada. Com isso, será possível simular um cenário próximo ao encontrado em ambientes produtivos, com a exceção de que todas as operações são executadas em um único nó.
Diagrama de Instalação
Para providenciar uma visão ilustrativa aos leitores, a imagem abaixo consolida as principais ações a serem realizadas na instalação e configuração do Hadoop no modo e no ambiente propostos.
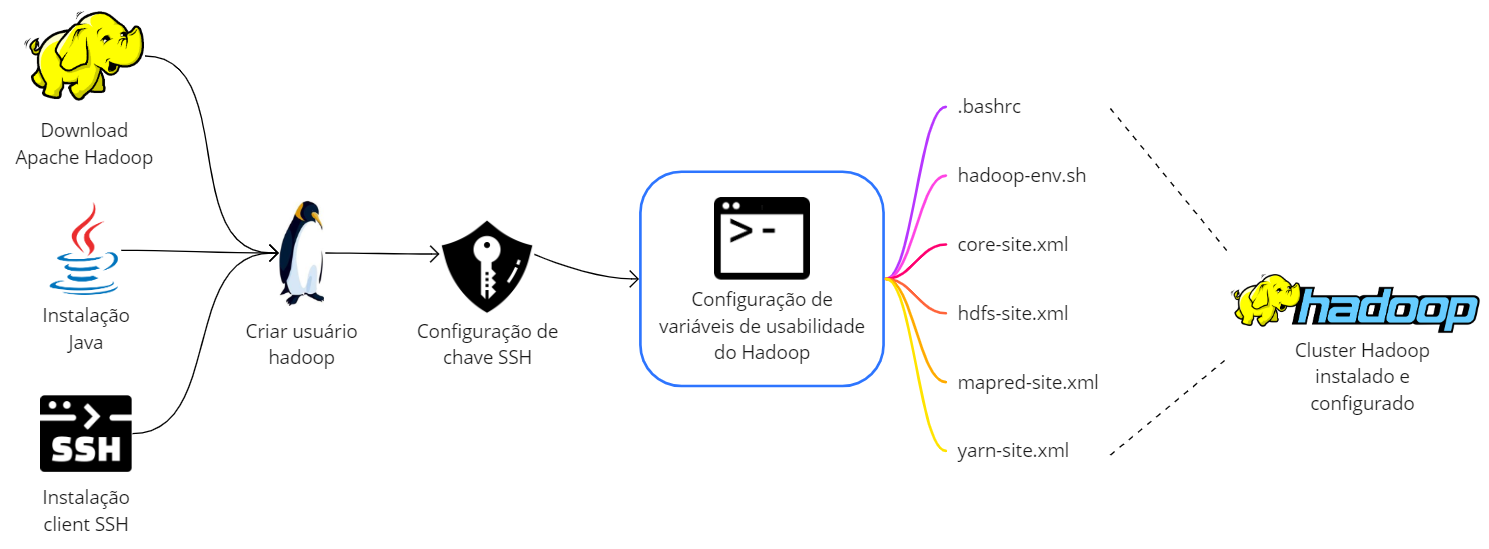
Como principal pré-requisito, espera-se que o usuário tenha disponível uma máquina Linux para realizar a instalação e configuração do Hadoop. Os passos subsequentes deste tutorial serão fornecidos considerando uma distribuição Ubuntu na versão 22.04 instalada como uma máquina virtual em um sistema Windows através do software VirtualBox. O segundo artigo publicado na série de Linux neste mesmo blog contempla um tutorial completo de instalação e configuração de uma VM Linux análoga à utilizada neste passo a passo de configuração do Hadoop.
Download do Apache Hadoop
Como primeiro passo do processo de instalação do Hadoop, uma versão estável do framework será escolhida diretamente do site oficial para que o download na máquina virtual Linux possa ser realizado. Para isso, será preciso:
1) Verificar as versões disponíveis no site oficial do Hadoop. No momento da criação deste tutorial, parece viável a instalação do Hadoop versão 3.2.2.
2) Com o terminal aberto, realize o download do Hadoop 3.2.2 através da execução do seguinte comando:
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz
Ao finalizar a instalação, um arquivo comprimido com os binários do Hadoop de extensão .tar.gz estará disponível na pasta de downloads do usuário (~/Downloads). Para garantir uma configuração sustentável do processo de instalação, este arquivo será movido e extraído para um local comum no sistema.
“Como boa prática, recomenda-se que a extração do conteúdo da distribuição do Hadoop seja feita em um diretório sensível, como /usr/local ou /opt por exemplo. Não é recomendado que o Hadoop seja instalado em um diretório home de usuário.”
Trecho adaptado do livro Hadoop: The Definitive Guide
3) Mova o arquivo recém baixado para o diretório /usr/local através do comando:
sudo mv hadoop-3.2.2.tar.gz /usr/local
4) Navegue até o diretório /usr/local e realize a extração do arquivo tarball através do comando:
cd /usr/local
sudo tar xzf hadoop-3.2.2.tar.gz
5) Verifique o conteúdo obtido através do comando ls:
Configurações Iniciais
Para que o processo de instalação e configuração do Hadoop seja realizado com sucesso, é necessário que algumas premissas e insumos estejam disponíveis no sistema. O bloco abaixo será responsável por orientar o usuário sobre os softwares a serem instalados e ações de configuração a serem tomadas para que os passos subsequentes possam ser executados com sucesso. Isto inclui:
- Instalação do Java
- Instalação do OpenSSH
- Criação de usuário
hadoope modificação de permissões do diretório de binários do Hadoop - Geração e configuração de chave SSH para o usuário
hadoop
Instalação do Java
1) Como forma de validação, primeiro verifique se o Java já está instalado na máquina através da execução do seguinte comando terminal:
java -version
Resultado para Java não instalado:
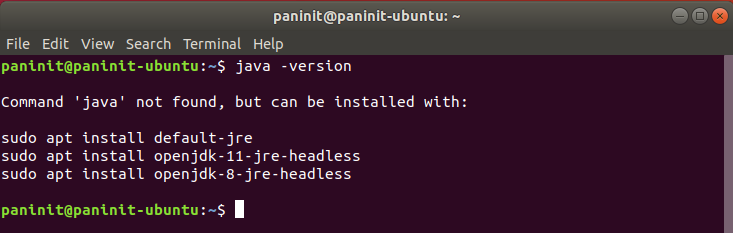
2) Realize a instalação do java a partir do comando:
cd ~
sudo apt install openjdk-8-jdk -y
3) Aguarde o término da instalação e verifique novamente a versão instalada do Java via java -version
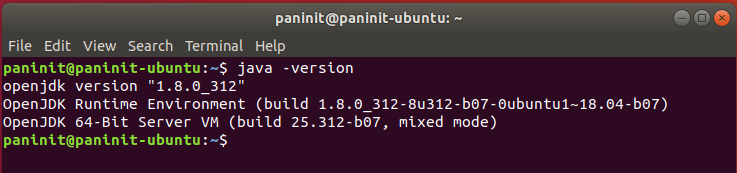
Instalação do OpenSSH
“É recomendado criar um user não-root para o ambiente Hadoop. Um usuário apartado aprimora a segurança e auxilia no gerenciamento do cluster de forma mais eficiente. Para garantir as funcionalidades dos serviços Hadoop, este usuário necessita ter permissão para estabelecer uma conexão SSH “sem password” com o localhost”
Traduzido de phoenixNap - Install Hadoop on Ubuntu
1) No terminal Linux, realize o download do server e client OpenSSH através do comando:
sudo apt install openssh-server openssh-client -y
Pronto! Agora o sistema conta com a possibilidade de utilizar o protocolo SSH de forma segura e criptografada para comunicação em rede. Futuramente, um novo usuário nomeado hadoop será criado e, para ele, chaves de segurança serão construídas e armazenadas para utilização junto ao Hadoop.
Criação de Usuário Hadoop
1) Com o terminal Linux aberto, execute o comando:
sudo adduser hadoop
2) Forneça uma senha para os campos solicitados
3) Pressione Enter para campos como Full Name, Room Number, Work Phone, Home Phone e Other
4) Confirme a criação do usuário pressionando y
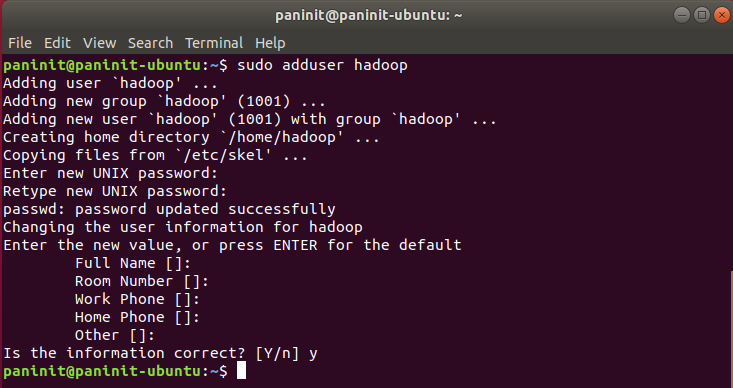
5) Uma vez criado o novo usuário hadoop, altere o owner do diretório do Apache Hadoop extraído previamente (em `/usr/local_ ) para o novo usuário criado através do comando abaixo:
sudo chown -R hadoop:hadoop /usr/local/hadoop-3.2.2
Este passo é extremamente importante para que o usuário possa acessar, configurar, modificar as variáveis de ambiente e utilizar as funcionalidades do Hadoop.
6) Ative o usuário a partir da execução do comando:
su - hadoop
7) Forneça a senha cadastrada para o usuário nos passos anteriores e verifique a alteração do nome do usuário no próprio terminal (exemplo de: paninit para hadoop)

Configuração de Chave SSH
1) Realize a criação e a configuração da chave através do comando:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
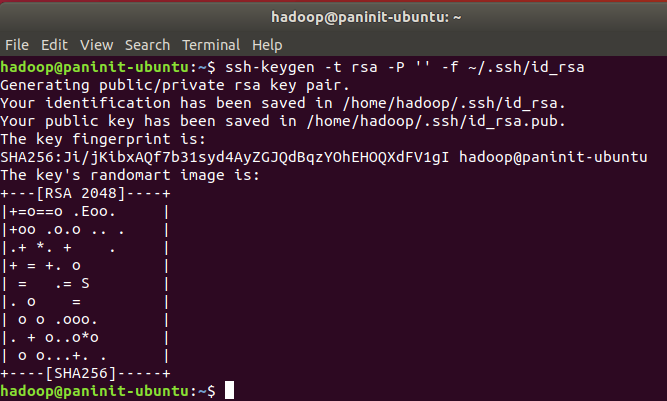
2) Armazene a chave SSH pública recém criada na lista de chaves autorizadas através do comando:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3) Modifique as permissões da chave através do comando:
chmod 0600 ~/.ssh/authorized_keys
4) Verifique se o usuário agora consegue realizar conexão no localhost via ssh sem password através do comando:
ssh localhost
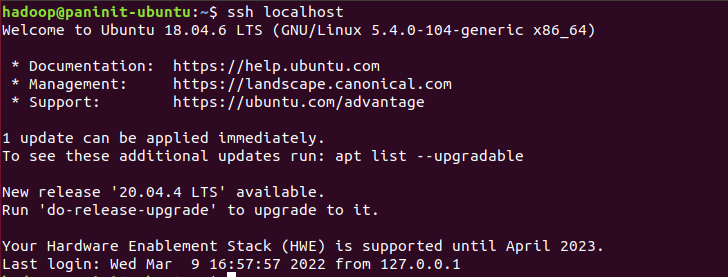
Com isso, todas as premissas de ferramentas e configurações foram concluídas com sucesso. A partir de agora, a instalação do Hadoop terá sequência a partir da configuração das variáveis de ambiente do sistema.
Configuração das Variáveis de Ambiente e Propriedades
Após o download e extração do Hadoop, é preciso realizar configurações de algumas variáveis de ambiente para, de fato, garantir a eficiência da usabilidade do Hadoop em seu modo pseudo-distribuído. Com o consumo de diversas referências sobre este passo, a tabela abaixo pôde ser construída para facilitar o entendimento geral de cada arquivo e variável a ser configurada nos passos subsequentes:
| Arquivo | Função | Variáveis Configuradas |
| .bashrc | Arquivo inicializado quando um usuário Linux realiza o login. Contém configurações a serem aplicadas na sessão do terminal. | HADOOP_HOME, HADOOP_INSTALL, HADOOP_MAPRED_HOME, HADOOP_COMMON_HOME, HADOOP_HDFS_HOME, YARN_HOME, HADOOP_COMMON_LIB_NATIVE_DIR, PATH, HADOOP_OPTS |
| hadoop-env.sh | Arquivo master para configuração de variáveis de ambiente utilizadas nos scripts de execução do Hadoop. Funciona como uma espécie de guia para configurações do HDFS, YARN e MapReduce. | JAVA_HOME |
| core-site.xml | Configurações para o Hadoop Core, como I/O comuns ao HDFS, MapReduce e YARN. Define as propriedades principais do Hadoop. | hadoop.tmp.dir, fs.default.name |
| hdfs-site.xml | Configura propriedades dos daemons do HDFS: o namenode, o secundary namenode e o datanode. | dfs.name.dir, dfs.data.dir, dfs.replication |
| mapred-site.xml | Configura propriedades dos daemons MapReduce: o servidor de job history. | mapreduce.framework.home |
| yarn-site.xml | Configura propriedades dos daemons do YARN: o resource manager, o proxy do servidor web app e os node managers. | yarn.nodemanager.aux-services, yarn.nodemanager.aux-services.mapreduce.shuffle.class, yarn.resourcemanager.hostname, yarn.acl.enable, yarn.nodemanager.env-whitelist |
Configuração do arquivo .bashrc
1) Usando um editor de texto presente no sistema operacional, abra o arquivo .bashrc:
nano .bashrc
2) Ao final do arquivo (dica: utilize Ctrl + End), adicione as seguintes configurações:
# Configuração de variáveis de ambiente para o Hadoop
export HADOOP_HOME=/usr/local/hadoop-3.2.2
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Obs:* certifique-se que a variável HADOOP_HOME aponte para a extração do Hadoop realizada nos passos anteriores.
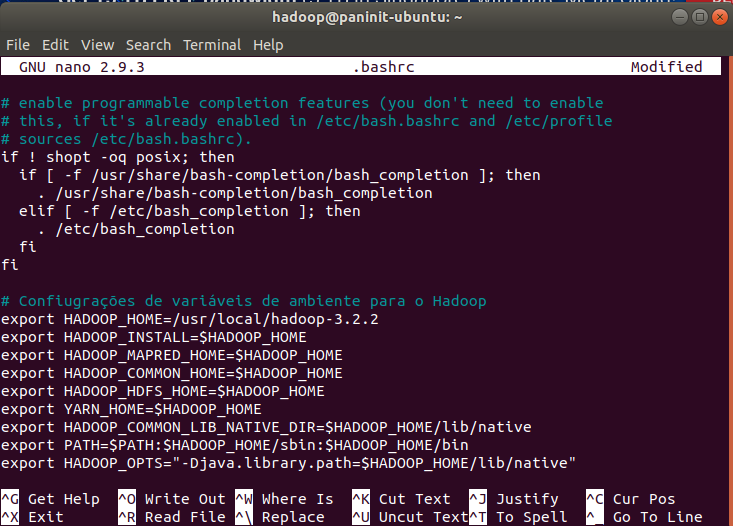
3) Salve e feche o arquivo
4) Execute o comando abaixo no terminal para ativar as configurações recém inseridas:
source ~/.bashrc
Configuração do arquivo hadoop-env.sh
1) Verifique a referência de instalação do Java presente na máquina através do comando:
which java

2) Na sequência, utilize este resultado como input do seguinte comando para coletar o local do Java a ser referenciado no arquivo hadoop-env.sh:
readlink -f /usr/bin/javac
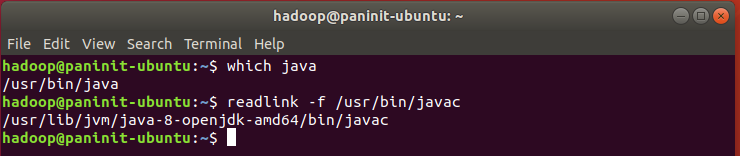
3) Copie o local de referência até o trecho /bin. Seguindo o exemplo da imagem acima, a referência a ser copiada seria: /usr/lib/jvm/java-8-openjdk-amd64
4) Usando um editor de texto presente no sistema operacional, abra o arquivo hadoop-env.sh:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
5) Encontre a linha comentada com a definição da variável JAVA_HOME (aproximadamente linha 54):
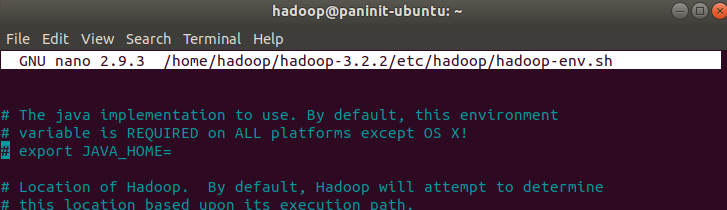
6) Retire o comentário da linha que define a variável JAVA_HOME e adicione a referência copiada do Java no passo anterior.

Configuração do arquivo core-site.xml
1) Usando um editor de texto presente no sistema operacional, abra o arquivo core-site.xml:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
2) Ao final do arquivo, adicione o seguinte trecho para sobrescrever a URL padrão do HDFS:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>
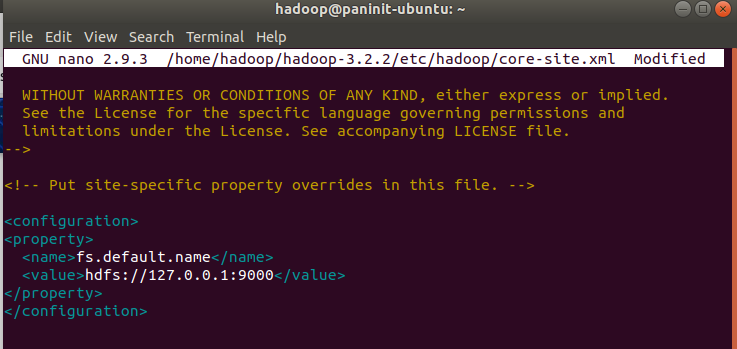
3) Salve e feche o arquivo
Configuração do arquivo hdfs-site.xml
1) Realize a criação dos diretórios responsáveis por armazenar os metadados dos nós, logs e outros arquivos relacionados aos namenodes e datanodes do Hadoop. No exemplo abaixo, tais diretórios foram escolhidos arbitrariamente no local /home/hadoop/data/hadoop/hdfs.
mkdir -p ~/data/hadoop/hdfs/{namenode,datanode}
2) Verifique se as pastas foram criadas corretamente via comando ls:

3) Usando um editor de texto presente no sistema operacional, abra o arquivo hdfs-site.xml:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
4) Adicione as seguintes propriedades para configurar os diretórios de armazenamento de dados dos namenodes e datanodes (pastas recém criadas). Adicionalmente, a propriedade dfs.replication igual a 1 indica que o Hadoop será armazenado em um modo single node.
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/data/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/data/hadoop/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
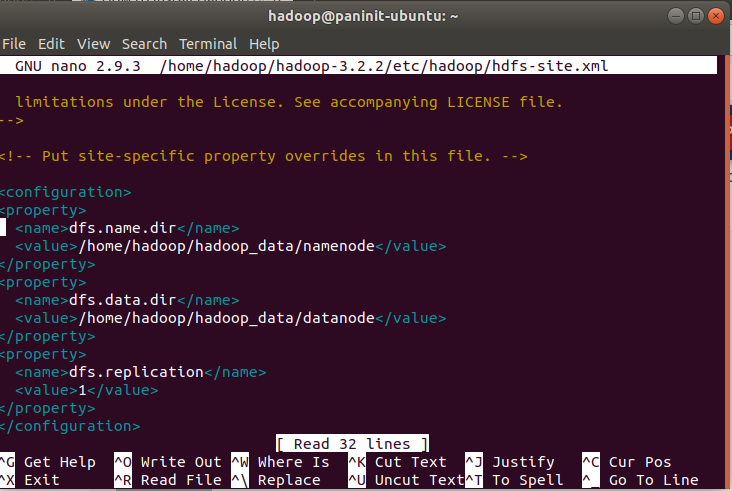
5) Salve e feche o arquivo
Configuração do arquivo mapred-site.xml
1) Usando um editor de texto presente no sistema operacional, abra o arquivo mapred-site.xml:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
2) Adicione o seguinte conteúdo:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
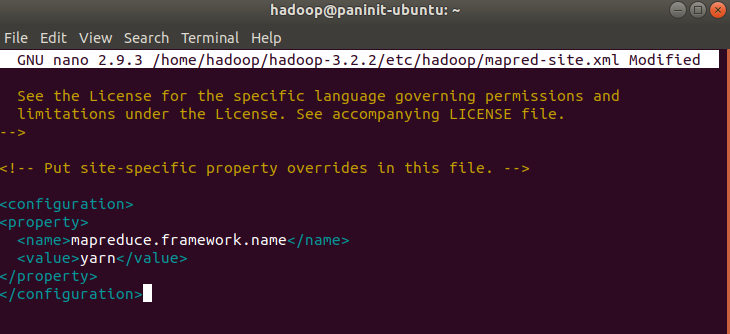
3) Salve e feche o arquivo
Configuração do arquivo yarn-site.xml
1) Usando um editor de texto presente no sistema operacional, abra o arquivo yarn-site.xml
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
2) Adicione o seguinte conteúdo:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
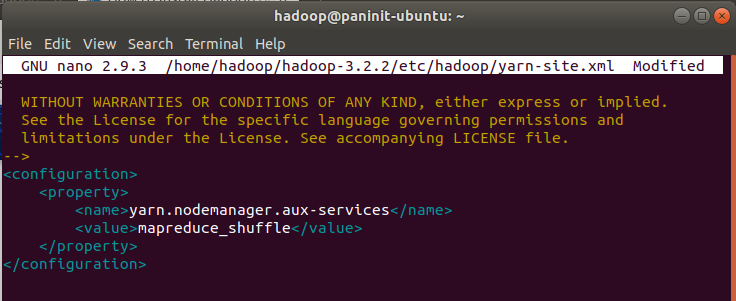
3) Salve e feche o arquivo
Formatando o HDFS
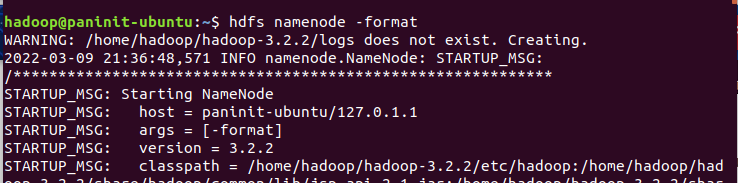
1) Para finalizar as configurações e começar a utilizar o Hadoop, é preciso formatar o HDFS através do comando:
hdfs namenode -format
 ...
...

E assim está feito! Após uma longa jornada de configuração de variáveis e propriedades do Hadoop, é possível finalmente seguir para sua inicialziação.
Inicializando o HDFS e o YARN
1) Inicialize o sistema de arquivos distribuídos do Hadoop (HDFS) pelo comando:
start-dfs.sh

2) Inicialize o gerenciador de recursos do Hadoop (YARN) pelo comando:
start-yarn.sh

3) Verifique se os daemons estão funcionando através do comando jps (verifica processos Java):

Visualizando o Funcionamento do Hadoop
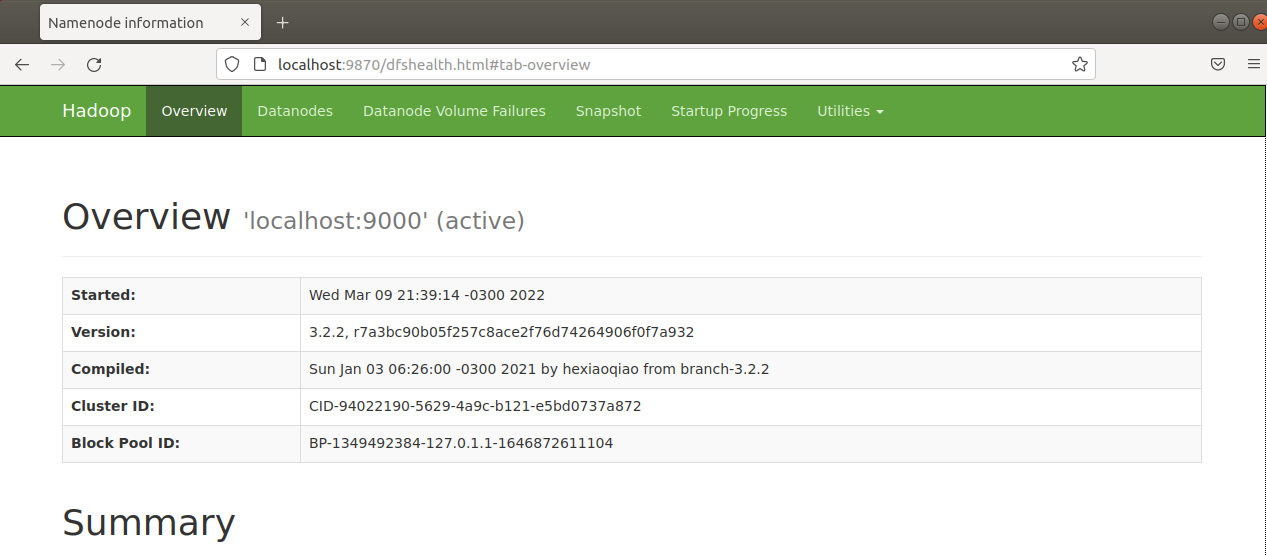
1) Visualize a interface dos namenodes do Hadoop na porta 9870 via http://localhost:9870:
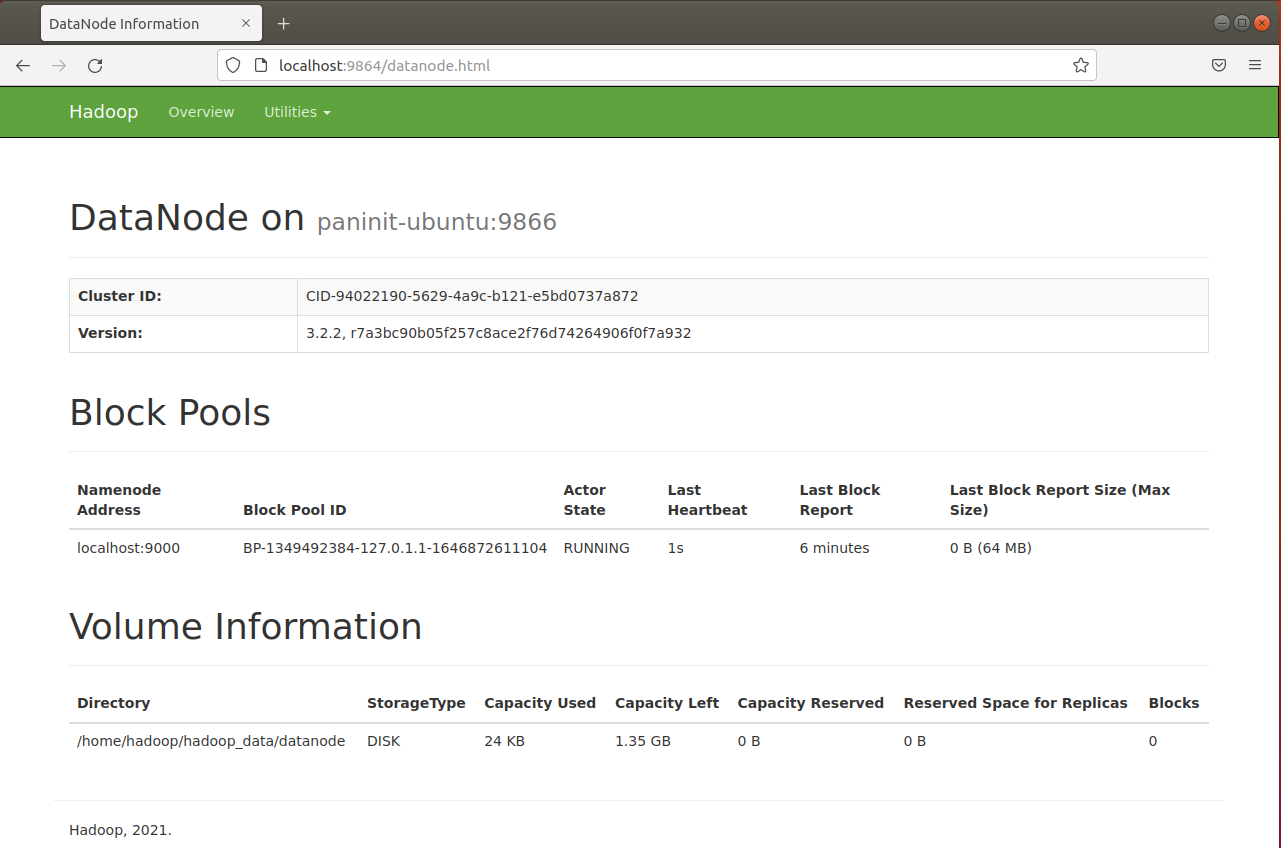
2) Visualize a interface dos datanodes do Hadoop na porta 9864 via http://localhost:9864:
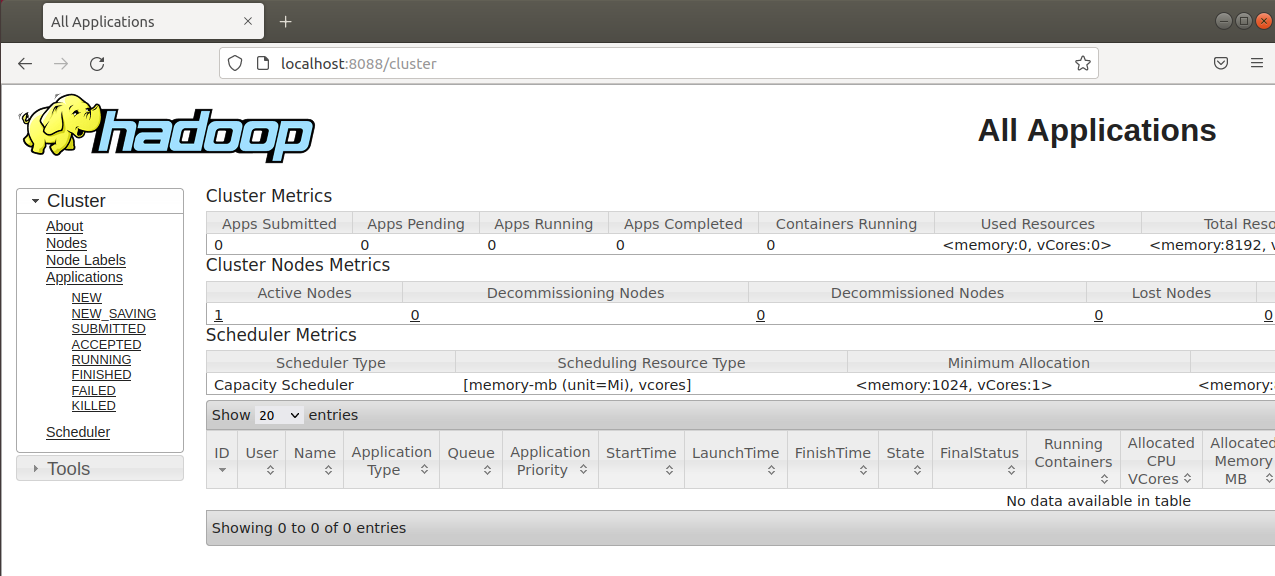
3) Visualize a interface do gerenciador de recursos (YARN) na porta 8088 via http://localhost:8088:
Testando Comandos do HDFS
Ainda nesta série sobre o ecossistema Hadoop, um artigo específico sobre os principais comandos do HDFS será fornecido aos leitores. Por enquanto, para aproveitar o sucesso desta instalação do Hadoop, a sequência de códigos abaixo poderá ser utilizada para criar alguns diretórios no sistema de armazenamento distribuído.
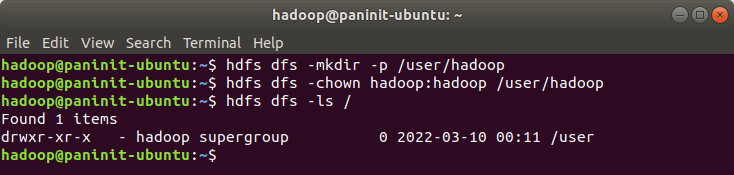
1) Execute o comando abaixo para criar um diretório para o usuário hadoop no HDFS:
hdfs dfs -mkdir -p /user/hadoop
2) Altere as permissões de owner do diretório para o usuário hadoop com o código abaixo:
hdfs dfs -chown hadoop:hadoop /user/hadoop
3) Verifique a existência do diretório no HDFS a partir do comando abaixo:
hdfs dfs -ls /
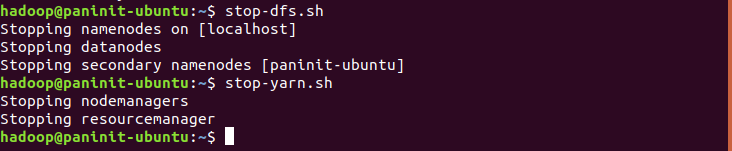
Finalizando Recursos do Hadoop
Para finalizar o cluster Hadoop basta executar os scripts shell:
stop-dfs.sh
stop-yarn.sh
Bônus: criando script para facilitar a inicialização e finalização do Hadoop
1) Crie um diretório bin na home do usuário através do comando:
mkdir ~/bin
2) Usando um editor de texto, crie um script shell através do comando:
nano bin/start-hadoop.sh
3) Insira o seguinte conteúdo no script recém aberto:
#!/bin/sh
# Comando para inicializar o HDFS
echo "------------------"
echo "Inicializando HDFS"
echo "------------------"
start-dfs.sh
# Comando para inicializar o YARN
echo ""
echo "------------------"
echo "Inicializando YARN"
echo "------------------"
start-yarn.sh
4) Feche e salve o arquivo
5) Edite o arquivo ~/.bashrc:
nano ~/.bashrc
6) Adicione o caminho para o diretório bin recém criado nas variáveis de ambiente:
# Configuração de scripts de inicializacao
export PATH=$PATH:$HOME/bin
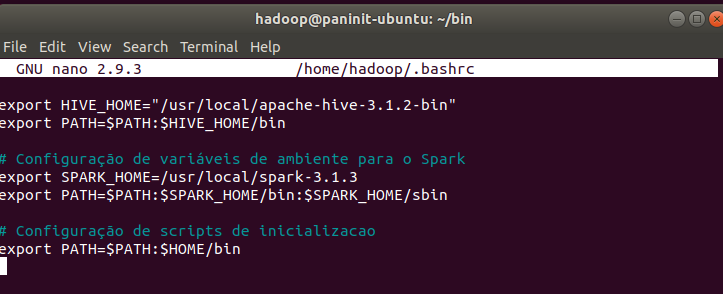
7) Salve e feche o arquivo
8) Ative as alterações a partir do comando:
source ~/.bashrc
9) Realize uma cópia do script start-hadoop.sh recém criado alterando o nome para stop-hadoop.sh a partir do comando:
cp ~/bin/start-hadoop.sh ~/bin/stop-hadoop.sh
10) Edite o script stop-hadoop.sh utilizando um editor de texto:
nano ~/bin/stop-hadoop.sh
11) Insira o seguinte conteúdo:
#!/bin/sh
# Comando para inicializar o HDFS
echo "----------------"
echo "Finalizando HDFS"
echo "----------------"
stop-dfs.sh
# Comando para inicializar o YARN
echo ""
echo "----------------"
echo "Finalizando YARN"
echo "----------------"
stop-yarn.sh
12) Salve e feche o arquivo
13) Altere as permissões de ambos os arquivos através dos comandos:
chmod +x ~/bin/start-hadoop.sh
chmod +x ~/bin/stop-hadoop.sh
Pronto! Agora você pode inicializar e finalizar o HDFS e o YARN com um único comando!
Considerações Finais
Ao final desta longa saga, foi possível passar por todas as etapas necessárias para a instalação e configuração do Hadoop no modo pseudo distribuído em uma máquina virtual Linux. Por mais denso que tenha sido este conteúdo, ele é de fundamental importância para uma visão prática das funcionalidades do Hadoop.
A partir deste ponto, os leitores desta série alcançam um novo nível de conhecimento e aprimoramento técnico sobre a usabilidade prática do Hadoop.
Espero que este tenha sido um artigo extremamente proveitoso dentro de sua jornada de aprendizado. Fique ligado para mais conteúdos sobre Hadoop nesta série!
Referências
- DataFlair- What are the different modes in which Hadoop run?
- GeeksForGeeks - Hadoop – Different Modes of Operation
- DevMedia - Hadoop: fundamentos e instalação
- ProfissionaisLinux - OpenSSH
- phoenixNap - Install Hadoop on Ubuntu
- HowToForge - How to Install and Configure Apache Hadoop
- TecAdmin - Setup Hadoop on Ubuntu
- Guru99 - Introduction to Shell Scripting




