

Filtrando e Ordenando Registros

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! No ultimo artigo, a criação de literais e a transformação de tipos primitivos foram os temas abordados e representados, respectivamente, através da função lit() e do método cast().
Considerando os recentes artigos publicados nesta série, é possível dizer que as funções e métodos apresentados tiveram ênfase em cenários de transformações de colunas de uma coleção distribuída de dados. Aprendemos a selecionar e a aplicar consultas com select() e selectExpr() (além das referências col() e expr()), a adicionar colunas com withColumn(), a também renomeá-las com withColumnRenamed() e outros atributos adicionais que fatalmente seguiram esta mesma linha de raciocínio.
Mergulhando agora em uma nova raia desta piscina do saber, é chegado o momento de complementar os conhecimentos adquiridos: deste artigo em diante, serão apresentados alguns métodos de transformação aplicados em registros de uma coleção distribuída. Afinal, filtrar, ordenar, limitar, agrupar e uma série de outras operações são, de fato, componentes fundamentais em fluxos produtivos de trabalho em ambientes analíticos.
Assim, abrindo as portas para esta fase complementar do aprendizado, este artigo tem como objetivo introduzir exemplos e apresentar ao leitor a utilização dos métodos where() para filtragem dos dados e orderBy() para ordenação dos registros de um DataFrame.
Embarque nesta jornada!
Dados para exploração
Assim como em outros artigos desta série, a base de dados utilizada para demonstração dos métodos de transformação aqui consolidados terá raízes nos registros de vôos extraídos do Bureau dos Estados Unidos.
Abstraindo todo o processo de importação de bibliotecas, criação de sessão e leitura dos dados, o objeto alvo de estudo está representado na variável df exemplificada logo a seguir:
# [...]
# Criando tabela temporária
df.createOrReplaceTempView("tbl_flights")
# Verificando amostra dos dados
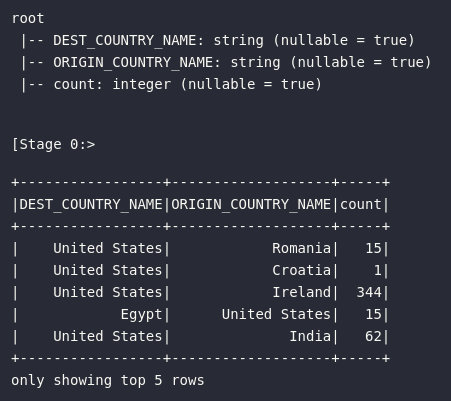
df.printSchema()
df.show(5)
Filtrando dados em um DataFrame
Aplicar filtros em um conjunto de dados é uma operação fundamental que pode ser utilizada em diversos cenários práticos. De forma direta, o Spark proporciona dois métodos análogos para realizar este processo: o filter() e o where(), ambos com a mesma funcionalidade e aplicabilidade.
Na prática, o método where() pode ser considerado mais comum por conta de sua nomenclatura próxima à cláusula homônima encontrada na linguagem SQL. Em essência, este método é simplesmente um alias para o método filter().
Assim, como uma primeira demonstração utilizando a base de vôos americanos, o bloco de código abaixo pode ser utilizado para selecionar apenas vôos com origem e destino no mesmo país. Como a base em si contempla apenas registros de viagens dos Estados Unidos, é esperado que apenas os vôos americanos sejam retornados.
# Vôos com origem e destino nos EUA
df_american_flights = df_flights.select(
col("ORIGIN_COUNTRY_NAME").alias("origem"),
col("DEST_COUNTRY_NAME").alias("destino"),
col("count").alias("quantidade")
).where(expr("DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME"))
# Visualizando novo conjunto
df_american_flights.show(5)
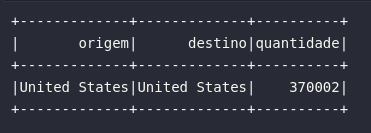
E assim como esperado, o resultado acima traz apenas os registros onde o país de origem do vôo é igual ao país de destino. Isto foi possível através da aplicação de um operador lógico como uma expressão expr() inserida dentro do método where(). De maneira análoga, a mesma regra poderia ser aplicada através de referência de colunas em um formato where(col("DEST_COUNTRY_NAME") == col("ORIGIN_COUNTRY_NAME").
Em linha com o princípio de que o Spark proporciona uma série de formas alternativas para realizar uma mesma operação, esta mesma operação de filtragem poderia ser realizada através da criação de uma flag capaz de identificar se os país de origem e destino são iguais. Nessa lógica, o filtro, em si, seria aplicado na própria coluna de flag utilizando o seguinte formato:
# Criando flag para vôos de mesma origem e destino
df_american_flights = df_flights.withColumn(
"flag_within_country", expr("DEST_COUNTRY_NAME = ORIGIN_COUNTRY_NAME")
).select("*").where(col("flag_within_country"))
# Visualizando dados
df_american_flights.show(5)
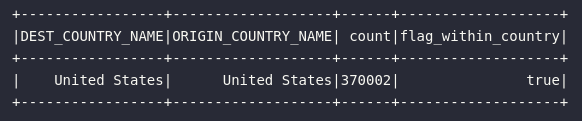
Unindo os conhecimentos já adquiridos até o momento, o bloco de código acima utiliza o método withColumn() para criar uma coluna denominada flag_within_country contendo uma regra que identifica se a coluna de país origem possui o mesmo valor que a coluna de país destino. Com isso, o resultado obtido após essa transformação é utilizado como alvo do método select() para selecionar dados apenas onde essa nova flag possuir o valor verdadeiro.
Por fim, como também já evidenciado anteriormente nesta série, o SparkSQL pode atuar como uma ferramenta altamente poderosa capaz de ser utilizada para as mais variadas transformações com a simples inserção de linguagem SQL:
# Filtrando registros com SparkSQL
df_american_flights = spark.sql("""
SELECT
ORIGIN_COUNTRY_NAME AS pais_origem,
DEST_COUNTRY_NAME AS pais_destino,
count AS qtd_voos
FROM tbl_flights
WHERE ORIGIN_COUNTRY_NAME = DEST_COUNTRY_NAME
""")
# Visualizando dados
df_american_flights.show(5)
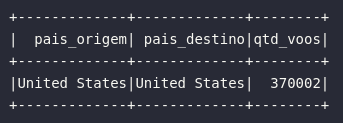
E assim, um novo leque se abre em meio aos processos de filtragem de dados em um fluxo de trabalho em Spark. O método where() pode ser aplicado diretamente em DataFrames para que operadores lógicos possam especificar conjuntos restritos de dados a serem retornados ao usuário. O SparkSQL também atua como uma ótima alternativa para aplicação de filtros a partir da própria linguagem SQL.
Ordenando registros em um DataFrame
A ordenação dos dados é um procedimento utilizado, principalmente, em conjuntos de dados já agregados para responder questões específicas de negócio. De fato, aplicar processos de ordenação em fluxos de trabalho não é tão comum quanto a filtragem de registros. Por outro lado, compreender a forma de aplicar este processo em jobs Spark pode auxiliar na obtenção de conjuntos de dados perfeitos para as melhores tomadas de decisão.
De forma direta, o Spark utiliza o método orderBy() aplicado à DataFrames para ordenar registros em tais coleções. No exemplo abaixo, este processo é aplicado para ordenar as viagens menos comuns para os americanos:
# Ordenando vôos menos comuns
df_flights.orderBy("count").show(5)

Para ordernar de forma descendente, visando obter os destinos mais comuns, seria preciso importar a função desc do módulo pyspark.sql.funtions:
# Importando função
from pyspark.sql.functions import desc
# Ordenando principais registros de vôos
df_flights.orderBy(desc("count")).show(10)
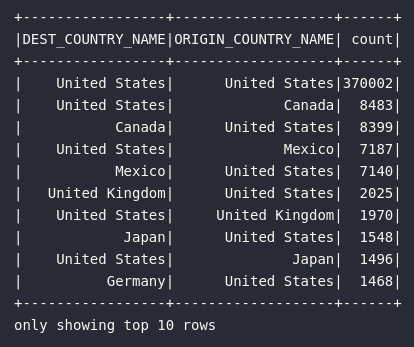
O uso conjunto da filtragem e ordenação também pode ser um poderoso combo dentro dos objetivos analíticos do fluxo de preparação de dados. No bloco abaixo, o objetivo será trazer à tona os principais registros de vôos com pelo menos 2.000 contagens realizadas:
# Top vôos com pelo menos 2000 registros
df_flights.where(expr("count > 2000")).orderBy(desc("count")).show()

Os processos de ordenação descendentes exemplificados utilizaram a função desc em conjunto com a referência de colunas col(). Como já visto anteriormente, este processo poderia ser realizado através da construção de uma query via SparkSQL:
# Filtrando e ordenando dados via SparkSQL
spark.sql("""
SELECT * FROM tbl_flights
WHERE count >= 2000
ORDER BY count DESC
""").show()
E assim, os processos de filtragem e ordenação de dados foram demonstrados em suas aplicações diretas através dos métodos where() (ou filter()) e orderBy(). Visando complementar ainda mais o conteúdo abordado, uma seção bônus será consolidada neste artigo para aproveitar a exemplificação dos métodos citados e explorar um assunto teórico relevante dentro das premissas de transformações de dados no Spark.
Diferentes tipos de transformações
Em um pequeno flashback, o oitavo artigo desta série abordou, de forma detalhada, toda a dinâmica de transformações aplicadas em processos produtivos criados no Spark. Daquele ponto em diante, foi possível compreender o que, de fato, são as transformações e como as instruções codificadas se comportam como grafos acíclicos (ou DAGs) capazes de definir, otimizar e executar planos de processamento dos dados. Em essência, sem os elementos de tal fundamentação teórica, os exemplos práticos trazidos no atual artigo e na recente sequência de artigos seriam apenas tutoriais vazios.
Propositalmente, um assunto específico envolvendo conceitos teóricos sobre transformações de dados foi guardado para este momento atual: a definição de narrow e wide transformations como os dois diferentes tipos de transformações encontradas na dinâmica de processamento de dados em um cluster de computadores.
Considerando o embalo trazido pela abordagem dos métodos de filtragem e ordenação dos dados, possuir uma visão geral do que realmente acontece dentro da dinâmica de armazenamento e movimentação dos dados em múltiplas máquinas de processamento é importante para que decisões estratégicas possam ser tomadas em meio a cenários práticos e reais de trabalho. De forma simples e direta, é justamente este o gap a ser preenchido logo a seguir.
Narrow Transformations
Como já informado, as transformações em Spark podem ser categorizadas em dois tipos distintos e tudo está basicamente relacionado aos efeitos práticos obtidos na dinâmica de posicionamento e movimentação dos dados no cluster de computadores.
Qualquer transformação onde uma única partição de saída dos dados pode ser computada a partir de uma única partição de entrada é conhecida como uma narrow transformation. Em outras palavras, as transformações to tipo narrow indicam que cada única partição de entrada dos dados (ou cada fatia de processamento) contribui exatamente para uma única partição de saída.
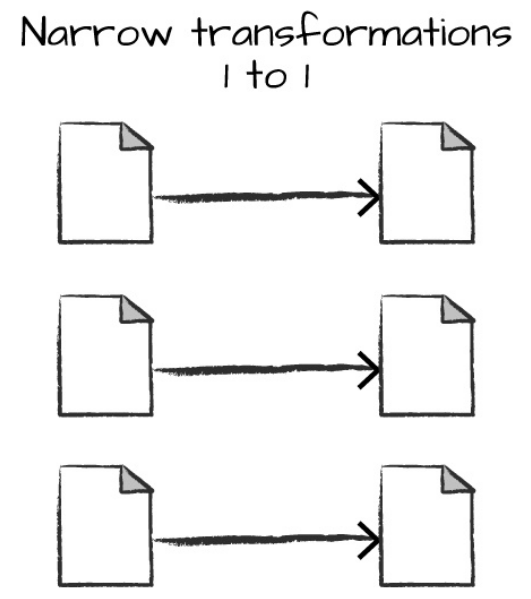
Assim, métodos como o where() e filter() são exemplos de narrow transformations pois, de certa forma, são transformações que, ao serem aplicadas em uma única partição de dados, certamente irão resultar em partições de mesma ordem na saída, sem nenhum tipo de troca ou movimentação de arquivos físicos entre máquinas do cluster.
Wide Transformations
Do outro lado do espectro, quando um método de transformação aplicado em uma coleção distribuída de dados no Spark indica que as partições de entrada podem contribuir com múltiplas partições de saída, tem-se em mãos uma wide transformation (também conhecidas como shuffle de dados).
Transformações do tipo wide exige do Spark uma espécie de intercâmbio de partições (dados) ao longo do cluster de computadores para o cálculo das instruções codificadas.
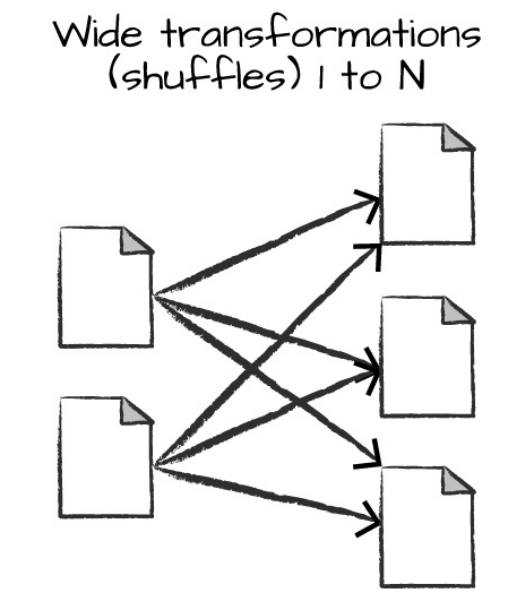
Como exemplo prático, o método orderBy(), utilizado para ordenação dos dados, é caracterizado como uma wide transformation pois, em sua essência, necessita do output de outras partições de dados para realizar a ordenação final instruída.
Conclusão e encerramento
E assim, mais um importante conhecimento pôde ser adicionado na prateleira de aprendizado do Apache Spark. Cada vez mais, estamos ganhando autonomia para a construção de fluxos completos de trabalho utilizando as mais variadas formas de transformação presentes neste vasto leque de possibilidades.
Filtrar e ordenar dados foram os dois primeiros métodos abordados na dinâmica de transformação de dados aplicada horizontal à registros de uma coleção distribuída em Spark. Esta foi a porta de entrada para explorações mais refinadas, como agrupamento, joins e outras mais.
Adicionalmente, compreender a dinâmica de transformações sob a ótica dos dados armazenados em sistemas distribuídos em um cluster de computadores é fundamental para analisar cenários de otimização presentes em fluxos produtivos. Definir e identificar narrow e wide dependencies é parte de um bloco fundamentalmente importante de conhecimento no Spark.
Foi ótimo ter você aqui, caro leitor. Até a próxima!




