

Transformando Tipos Primitivos (Casting)

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! No último artigo, três novos métodos de transformação foram apresentados ao leitor como forma de habilitar capacidades de adição, renomeação e eliminação de colunas em fluxos de trabalho no Spark.
Em linha com a jornada evolutiva de aprendizado, este artigo tem como objetivo introduzir dois método igualmente interessantes para a transformação de colunas de uma coleção distribuída de dados:
| Método | Descrição |
lit() | Cria literais que podem ser utilizados para enriquecer DataFrames |
cast() | Transforma tipos primitivos de atributos de um DataFrame |
Embarque nessa jornada!
Dados para exploração
Assim como em outros artigos desta série, a base de dados utilizada para demonstração dos métodos de transformação aqui consolidados terá raízes nos registros de vôos extraídos do Bureau dos Estados Unidos.
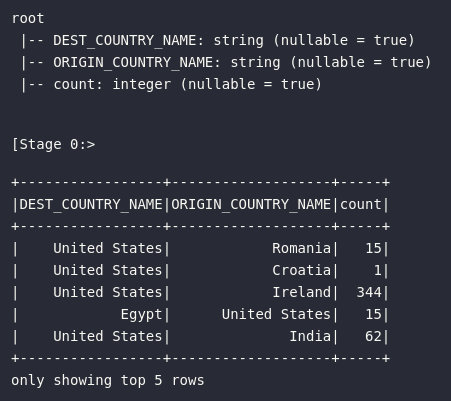
Abstraindo todo o processo de importação de bibliotecas, criação de sessão e leitura dos dados, o objeto alvo de estudo está representado na variável df exemplificada logo a seguir:
# [...]
# Criando tabela temporária
df.createOrReplaceTempView("tbl_flights")
# Verificando amostra dos dados
df.printSchema()
df.show(5)
Literais
Em alguns cenários, seja para fins analíticos ou até mesmo auxiliares, é possível encontrar necessidades específicas envolvendo a criação de literais como colunas em uma base de dados. No português mais clássico (com perdão ao leitor), seria algo análogo a "chumbar" um valor em uma consulta para gerar um record set personalizado.
No mundo do Spark e das APIs estruturadas, esta ação pode ser realizada através da aplicação do método lit():
# Importando funções
from pyspark.sql.functions import lit, col, expr
# Criando literais em consultas
df_lit = df.select(
col("*"),
lit(1).alias("lit_one"),
expr("2 as lit_two"),
lit("str").alias("lit_str"),
expr("'str_expr' AS lit_str_expr")
)
# Verificando schema
df_lit.printSchema()
df_lit.show(5)
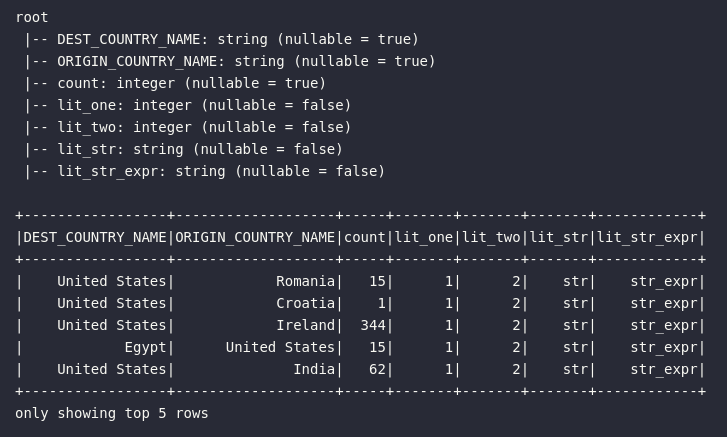
Neste momento, é válido pontuar que, no Spark, existem diferentes formas de realizar uma mesma operação. No exemplo de código acima, a função lit() foi utilizada para gerar literais inteiros ou em formato de string. De maneira análoga, este mesmo processo também foi demonstrado através da criação de uma expressão via expr() com uma leve alteração da sintaxe. Para validar o resultado obtido com a criação de literais em ambos os métodos, o schema do DataFrame resultante foi extraído e, a partir dele, é possível notar que o Spark automaticamente assinalou os tipos integer e string para os respectivos literais criados. Ademais, esta assunção automática do tipo primitivo poderia não ser a mais adequada em cenários específicos de trabalho. Dessa forma, como seria possível aplicar o processo de casting para alterar tipos primitivos de uma coleção estruturada de dados?
Casting
De maneira universal, o processo de alteração de tipos primitivos pode ser considerada uma etapa fundamentalmente essencial em fluxos de preparação e transformação de dados. Invariavelmente, as chances de encontrar este tipo de necessidade são altas e, dessa forma, é preciso estar preparado para encarar este tipo de desafio.
Felizmente, o Spark conta com um método extremamente simples e eficaz para aplicação do processo de casting em fluxos de transformação. Tão intuitivo quanto o nome pede, o método cast() é aplicado em objetos de coluna (Column) e pode ser utilizado da seguinte forma:
# Criando literais e alterando tipo primitivo
df_casting1 = df.select(
lit(1).alias("lit_int"),
lit(1).cast("string").alias("lit_str_cast")
)
# Visualizando schema e amostra
df_casting1.printSchema()
df_casting1.show(5)
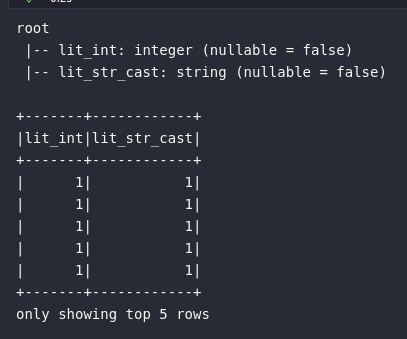
No bloco de código acima, um exemplo de consulta foi aplicada à um DataFrame para retornar duas colunas: uma contendo a criação pura de um literal no formato inteiro e, a segunda, contendo uma transformação do tipo original do literal para o formato string. Apesar do próprio schema da base resultante já fornecer explicitamente a resposta sobre os tipos primitivos gerados, é possível ainda aplicar uma ação de coleta de dados para o driver (como a take(), por exemplo) para analisar visualmente que o segundo elemento da coleção resultante é, de fato, uma string:
# Coletando uma linha
df_casting1.take(1)

E assim, a grande chave para o uso do método cast() se resume na informação do tipo primitivo alvo da conversão a ser passado como argumento. No exemplo fornecido, o objetivo foi converter um inteiro em um campo de texto, exigindo assim a passagem do argumento "string" no método. Em um cenário complementar, seria também possível passar os tipos primitivos explícitos do Spark para garantir uma maior confiabilidade no processo de conversão:
# Importando tipos primitivos
from tokenize import Double
from pyspark.sql.types import StringType, DoubleType, BooleanType
# Criando literais e alterando tipo primitivo
df_casting2 = df.select(
lit(1).alias("int"),
lit(1).cast(StringType()).alias("str"),
lit(1).cast(DoubleType()).alias("double"),
lit(1).cast(BooleanType()).alias("bool_true"),
lit(0).cast(BooleanType()).alias("bool_false")
)
# Visualizando schema e amostra
df_casting2.printSchema()
df_casting2.show(5)
# Coletando registro no driver
row = df_casting2.take(1)
print(row)
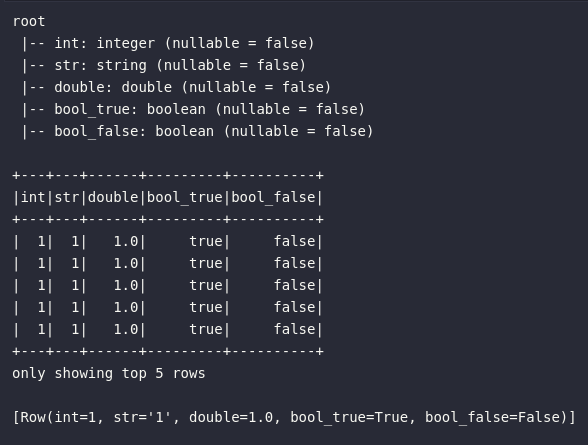
Observando o resultado acima, é possível notar claramente as transformações feitas pelo Spark de acordo com as solicitações de conversão codificadas. O destaque principal do conjunto de operações acima pode ser designado ao processo de casting para o tipo booleano, onde nota-se a assunção automática dos tipos True para o literal 1 e False para o literal 0.
Entretanto, nem sempre as conversões podem ser realizadas de maneira bem sucedidas. Tentar converter uma string em um inteiro nem sempre funciona. Nestes casos, o Spark adota um comportamento padrão de assinalar o valor nulo para resultados incalculáveis:
# Gerando erros de conversão
df_casting3 = df.select(
"DEST_COUNTRY_NAME",
col("DEST_COUNTRY_NAME").cast(DoubleType()).alias("dest_country_double")
)
# Verificando tipo primitivo e amostra
df_casting3.printSchema()
df_casting3.show(5)
# Coletando registro no driver
row = df_casting3.take(1)
print(row)
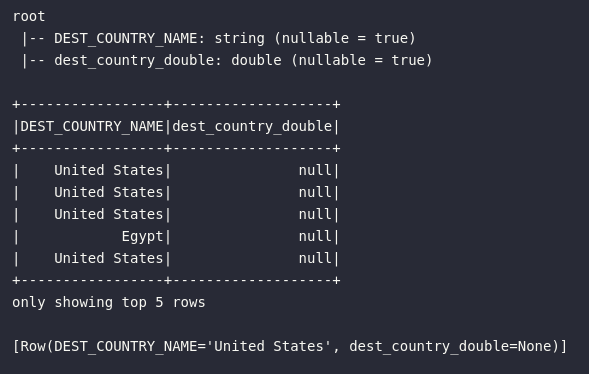
No exemplo acima, ao tentar converter uma coluna de texto literal contendo informações de países em um tipo LongType(), o Spark entende que trata-se de uma operação impossível e, dessa forma, assinala valores nulos à operação.
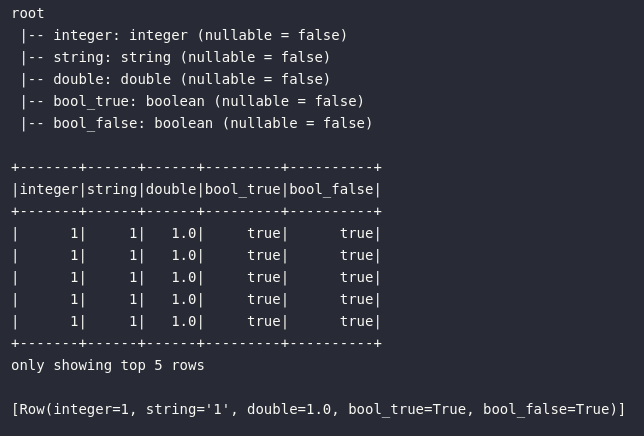
Por fim, finalizando os exemplos de transformação de tipos primitivos em Spark, é importante demonstrar que todas as etapas acima poderiam ser escritas utilizando SparkSQL em processos padrão de conversão de tipos:
# Convertendo via SparkSQL
df_casting4 = spark.sql("""
SELECT
1 AS integer,
cast(1 AS string) AS string,
cast(1 AS double) AS double,
cast(1 AS boolean) AS bool_true,
cast(1 AS boolean) AS bool_false
FROM tbl_flights
""")
# Verificando schema e amostra
df_casting4.printSchema()
df_casting4.show(5)
# Coletando amostra para o driver
print(df_casting4.take(1))
Conclusão e encerramento
E assim, mais um artigo desta nova etapa envolvendo métodos de transformação de dados em Spark chega ao fim. Desta vez, dois importantes elementos foram apresentados de modo a proporcionar aos usuários as habilidades de criação de literais em consultas e o importante processo de transformação de tipos primitivos (ou casting).
Com isso, cada vez mais poder pode ser encontrado nas mãos dos desenvolvedores e seguidores desta série. Ao longo do processo de aprendizado, uma série de outros elementos ainda serão abordados visando proporcionada uma autonomia cada vez maior em processos de construção de fluxos de trabalho em Spark.
Foi ótimo ter você aqui, caro leitor! Até a próxima!




