

Hadoop Core: YARN

Bem-vindos a mais um artigo da série "Visão Geral sobre o Ecossistema Hadoop"! Na última sequência de artigos, o objetivo estabelecido esteve relacionado a obtenção de conhecimentos detalhados sobre os três componentes fundamentais que formam a base das operações no Hadoop: o HDFS, o MapReduce e o YARN.
No primeiro artigo desta sequência, conhecemos o HDFS como o sistema de armazenamento distribuído do Hadoop capaz de armazenar grandes volumes de dados de maneira distribuída em um cluster de computadores, garantindo disponibilidade, replicação e eficiência.
Sequencialmente, vimos como o MapReduce atua para processar e extrair valor de dados já armazenados de maneira distribuída. O processamento paralelo é um dos grandes paradigmas da era de Big Data e a construção de um modelo de programação capaz de endereçar tal desafio foi um grande marco na evolução tecnológica.
Por fim, dentro do contexto de armazenamento e processamento de dados de forma distribuída em um cluster de computadores, é de suma importância compreender o funcionamento das engrenagens que garantem, entre outros fatores, o gerenciamento dos recursos disponíveis, o agendamento das solicitações de processamento ou até mesmo a dinâmica de interação entre os recursos para que a grande magia possa, de fato, acontecer. Neste ponto, apresentamos o YARN como o grande gerenciador de recursos de um cluster Hadoop
Perdeu algo? Confira a tabela abaixo para garantir o conhecimento necessário dentro desta jornada de entendimento sobre o Hadoop:
| Componente | Resumo | Artigo |
| HDFS | Sistema de armazenamento distribuído do Hadoop | Link |
| MapReduce | Modelo de programação para processamento paralelo | Link |
| YARN | Gerenciador de recursos do cluster Hadoop | Este artigo |
Um Negociador de Recursos
YARN é acrônimo para Yet Another Resource Negotiator e, como mencionado anteriormente, sua atuação está intimamente ligada ao gerenciamento dos recursos presentes em um cluster Hadoop.
Neste momento, é importante sempre reforçar que o cenário de trabalho na era do Big Data envolve a utilização de múltiplas máquinas para armazenar e processar quantidades de dados que superam as capacidades físicas e tecnológicas de processadores individuais. Com isso, uma série de novos desafios se fazem presentes, como por exemplo, a necessidade de garantir que os dados armazenados em múltiplas máquinas estarão disponíveis sempre que necessário, a existência de uma comunicação eficiente entre diferentes máquinas para obtenção e processamento dos dados, a otimização de recursos para que as solicitações sejam entregues ao solicitante da melhor forma possível, entre outros.
Presente a partir do Hadoop 2, o YARN foi implementado para aprimorar a existente relação de gerenciamento de recursos feita diretamente pelo MapReduce. O desacoplamento desta atividade administrativa garantiu uma série de benefícios ao framework como um todo, permitindo um ganho de eficiência das atividades operacionais e um aumento em seu desempenho geral.
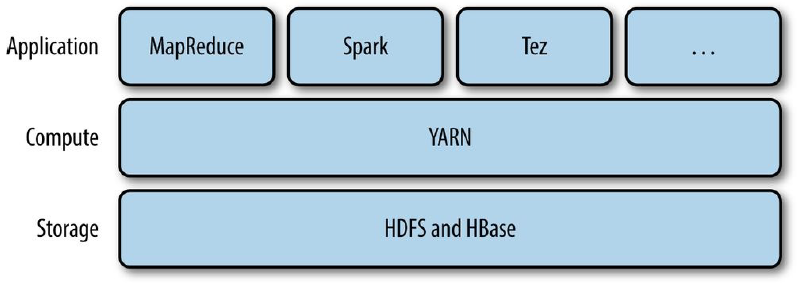
O funcionamento do YARN está baseado na disponibilização de APIs responsáveis por entregar informações dos recursos presentes em um cluster de computadores. Em geral, estas APIs são transparentes aos usuários do Hadoop, sendo papel das aplicações de alto nível (como o MapReduce, por exemplo) realizar este contato de modo a tomar ações com base nas informações obtidas. Assim, é correto pontuar que o YARN atua em uma camada separada entre o armazenamento e aplicações de alto nível, sendo um grande intermediador entre as partes.
Em uma definição formal, Frank Kane da Sundog Education elucida que:
O YARN é onde o processamento de dados tem início. Ele é basicamente o sistema que gerencia os recursos no cluster de computadores, decidindo quem executa as tarefas, quando as mesmas serão executadas, quais nós estão disponíveis para receber demandas e quais estão totalmente ocupados. O YARN é como o coração que permite o funcionamento do cluster.
Elementos do YARN
Uma breve experiência prática com os componentes do Hadoop Core permite dizer que o YARN provavelmente é o mais complexo entre eles. Grande parte desta relativa complexidade está intimamente relacionada a forma como os usuários visualizam sua atuação. Diferente do HDFS ou do MapReduce, o gerenciamento de recursos em um cluster Hadoop é uma atividade, muitas vezes, invisível ao usuário final que, por sua vez, solicita jobs de processamento de dados utilizando uma engine específica e simplesmente aguarda o retorno do resultado.
Mesmo assim, possuir uma noção simplificada sobre como esta atividade de gerenciamento é, de fato, realizada na dinâmica de um cluster de computadores pode garantir alguns benefícios adicionais. A imagem abaixo ilustra um exemplo de operação do sistema ao ser acionado por um client.
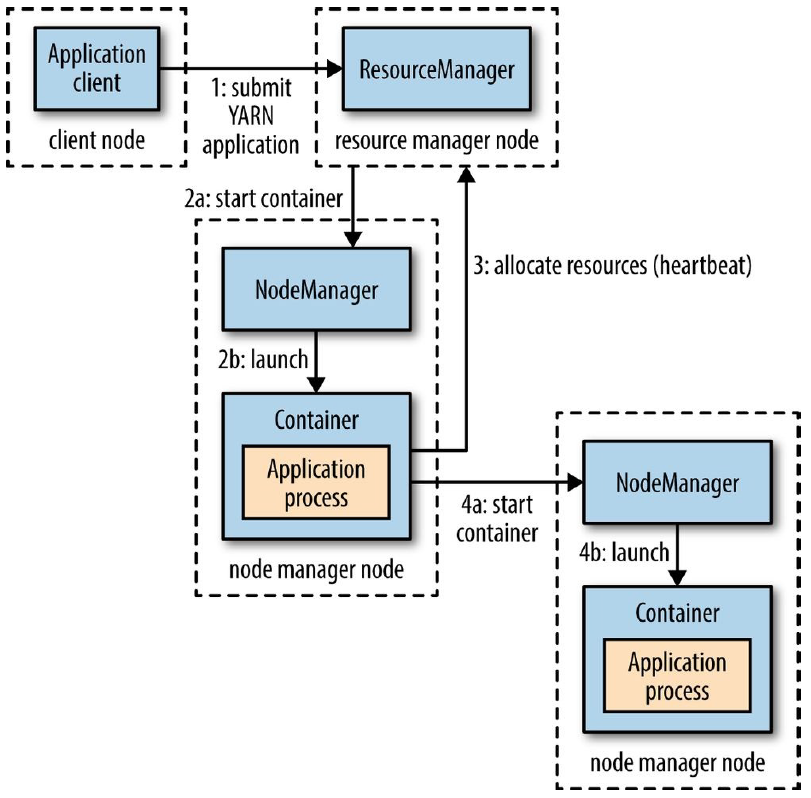
Neste ponto, alguns termos comumente encontrados na literatura do Hadoop se fazem presentes. A listagem abaixo visa fornecer uma breve explicação sobre cada um deles para que o YARN possa, aos poucos, ser decifrado:
Application Client:
- Programa solicitado pelo usuário
- Pode ser um job de MapReduce, por exemplo
Resource Manager:
- Gerencia e aloca recursos do cluster
- Possui dois principais elementos: o scheduler e o application manager
- Atua como um agendador global de recursos
Node Manager:
- Presente em todos os nós do cluster
- Executa e monitora os containers
Container:
- Referência ao pacote de recursos incluindo RAM, CPU, Rede, HD, entre outros
- Responsável por executar a aplicação com um conjunto restrito de recursos disponibilizados
- Dependendo de como o YARN é configurado, um container é basicamente um processo Unix ou um cgroup Linux
Application Process:
- Basicamente é o job submetido ao framework utilizado (ex: MapReduce)
A Evolução do YARN e do MapReduce
Em tópicos anteriores deste artigo, foi mencionado que o YARN surgiu a partir do Hadoop 2 para otimizar as relações de gerenciamento de recursos antes realizada diretamente pelo MapReduce (considerado em algumas literaturas como MapReduce 1).
Por maiores que tenham sido os avanços, ainda é possível encontrar termos relacionados à época onde o gerenciamento dos recursos era feito pelo MapReduce 1. Dessa forma, visando proporcionar um entendimento claro de alguns elementos importantes nesta dinâmica, a tabela disponibilizada no livro Hadoop: the Definitive Guide traz uma visão comparativa entre as ferramentas e seus respectivos termos:
| MapReduce 1 | YARN |
| Job Tracker | Resource Manager, Application Master, Timeline Server |
| Task Tracker | Node Manager |
| Slot | Container |
Assim, se forem encontrados termos específicos relacionados ao gerenciamento de recursos no MapReduce 1, é possível consumir a tabela acima para verificar seu significado relacionado no contexto de uso do YARN.
Considerações Finais
A intenção deste artigo foi proporcionar uma visão resumida e simplificada de um dos componentes principais do Hadoop responsáveis por garantir uma grande escalabilidade ao framework. A partir da implementação do YARN, a eficiência do Hadoop como um todo aumentou significativamente, permitindo que suas capacidades alcançassem níveis antes inimagináveis.
Sem a pretensão de garantir uma especialização completa e um aprofundamento avançado nos tópicos relacionados ao YARN, ter uma noção clara de seus componentes e de como estes atuam para proporcionar um gerenciamento completo de um cluster de computadores é um conhecimento extremamente rico.
Espero que esta tenha sido mais uma jornada extremamente relevante dentro de seu plano de aprendizado. Até a próxima!




