

Principais Comandos do HDFS

“Quando o volume de dados extrapola a capacidade de armazenamento de uma única máquina, se faz necessário particionar o volume em um número de máquinas distintas. […]O Hadoop possui um elemento para armazenamento distribuído conhecido como HDFS […]desenhado para armazenamento de dados em larga escala em hardware commodity.”
Adaptado do livro Hadoop - The Definitive Guide de Tom White
Bem-vindos a mais um artigo da série "Visão Geral sobre o Ecossistema Hadoop"! Após uma jornada extremamente recompensadora no entendimento dos componentes principais do Hadoop como HDFS, MapReduce e YARN e na subsequente instalação e configuração completa de um ambiente Hadoop em seu modo pseudo-distribuído, os leitores desta série se aproximam cada vez mais da visão prática de uso deste importante framework criado para solucionar problemas na era do Big Data.
Aproveitando-se da presença do Hadoop em uma VM Linux, este artigo tem como principal objetivo alocar os principais comandos operacionais do HDFS, proporcionando aos leitores uma visão simples e resumida sobre as possibilidades de uso do sistema de armazenamento distribuído do Hadoop em cenários práticos. Além do detalhamento teórico dos comandos e suas respectivas explicações, ao final deste artigo serão fornecidos exemplos reais de aplicações dos comandos com explicações e imagens ilustrativas.
Para que o leitor possa seguir os testes práticos propostos ao longo deste artigo, é recomendado a leitura dos seguintes artigos para instalação de uma máquina virtual Linux e do ambiente Hadoop:
- Série Linux - Instalação e Configuração de uma Máquina Virtual Linux
- Série Hadoop - Instalação e Configuração do Ambiente Hadoop
Como complemento, para um entendimento geral sobre o sistema de armazenamento distribuído do Hadoop, o artigo abaixo também poderá ser utilizado como uma ótima referência:
Por fim, de forma simples e objetiva, os usuários estarão operando no sistema de armazenamento distribuído do Hadoop através da linha de comando. O diagrama abaixo exemplifica o cenário e o ambiente proposto para os testes.
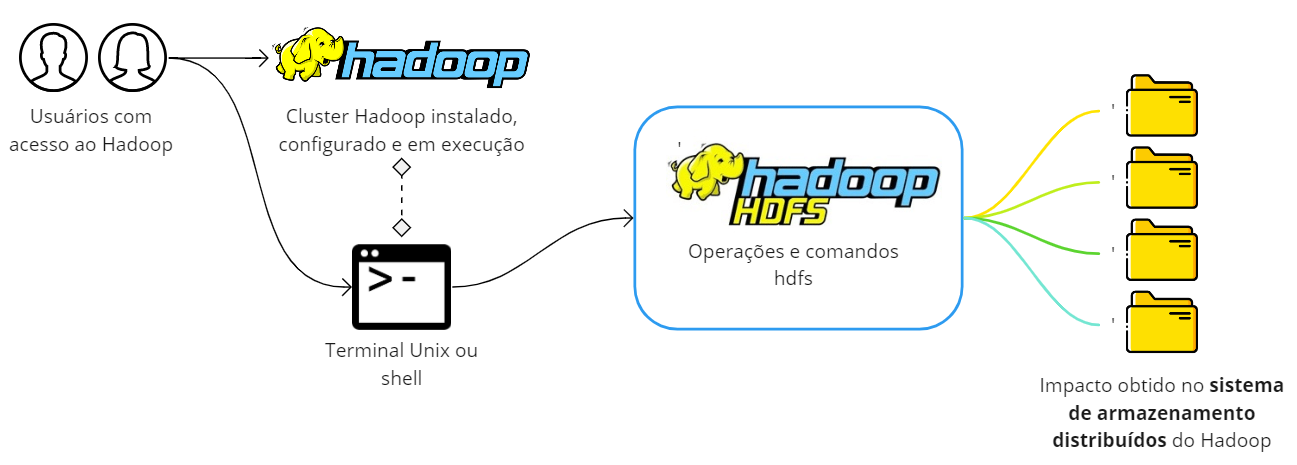
Principais Comandos do HDFS
Assim, chegando definitivamente ao objetivo deste artigo, a tabela abaixo consolida os principais comandos do HDFS listados através de uma experiência prática de uso. Como auxílio ao usuário, para cada comando listado na tabela, foi posicionado um link de acesso à documentação oficial do HDFS para detalhar opções adicionais que podem ser usadas junto aos comandos.
| Comando | Descrição | Exemplo de Uso |
| mkdir | Realiza a criação de diretórios no HDFS | hdfs dfs mkdir -p <path> |
| ls | Lista os diretórios e arquivos presentes em uma referência de caminho | hdfs dfs -ls <path> |
| put | Copia arquivos ou diretórios armazenados localmente para o HDFS | hdfs dfs -put <local path> <hdfs path> |
| copyFromLocal | Comando análogo ao put para copiar arquivos ou diretórios locais no sistema distribuído do HDFS | hdfs dfs -copyFromLocal <local path> <hdfs path> |
| get | Copia arquivos ou diretórios armazenados no HDFS para um armazenamento local | hdfs dfs -get <hdfs path> <local path> |
| copyToLocal | Comando análogo ao get para copiar arquivos do HDFS para o armazenamento local | hdfs dfs -copyToLocal <hdfs path> <local path> |
| cp | Realiza a cópia de arquivos ou diretórios dentro do HDFS | hdfs dfs -cp <hdfs src path> <hdfs dest path> |
| mv | Move arquivos ou diretórios dentro do HDFS. Diferente do comando cp, o mv não preserva ou mantém uma cópia do arquivo ou diretório no HDFS | hdfs dfs -mv <hdfs src path> <hdfs dest path> |
| moveFromLocal | Move arquivos ou diretórios de um ambiente local para o HDFS. Diferente dos comandos put ou copyFromLocal, o moveFromLocal não preserva ou mantém uma cópia do arquivo ou diretório no armazenamento local | hdfs dfs moveFromLocal <local path> <hdfs path> |
| cat | Concatena o conteúdo de múltiplos arquivos no HDFS. Este comando também é comumente usado para enviar e mostrar o conteúdo de um arquivo no HDFS para a saída local do sistema (stdout) | hdfs dfs -cat <hdfs file path> |
| rm | Elimina um arquivo no HDFS | hdfs dfs -rm <hdfs file path> |
| rmdir | Elimina um diretório no HDFS | hdfs dfs -rmdir <hdfs dir path> |
| rmr | Elimina arquivos no HDFS de forma recursiva. Pode ser utilizado para eliminação de diretórios não vazios | hdfs dfs -rmr <hdfs path> |
| du | Mostra o tamanho de arquivos e diretórios presentes em um caminho especificado do HDFS | hdfs dfs -du <hdfs path> |
| dus | Mostra um resumo geral sobre o tamanho de um diretório no HDFS | hdfs dfs -dus <hdfs path> |
| stat | Mostra a data de última modificação e estatísticas adicionais de um diretório ou arquivo no HDFS | hdfs dfs -stat <hdfs path> |
Para maiores informações, a documentação oficial do HDFS poderá ser usada como sua principal referência.
A seguir, uma seção especial será disponibilizada com exemplos reais de execução de alguns dos comandos acima listados no ambiente Hadoop instalado.
Exemplos Práticos
Para que os comandos do HDFS possam ser executados, é preciso que os processos do sistema de armazenamento distribuído e do YARN tenham sido inicializados no sistema. Para tal, é possível executar os seguintes comandos abaixo:
su - hadoop
start-dfs.sh
start-yarn.sh
Observação: seguindo os passos do artigo de instalação e configuração do Hadoop, um usuário nomeado hadoop foi criado para centralizar as configurações do sistema e, dessa forma, é preciso acessá-lo através do comando su - hadoop antes de executar as operações.
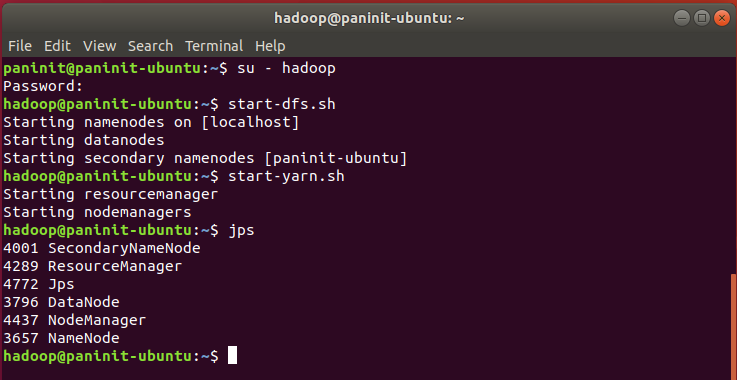
Para verificar se o cluster Hadoop está em execução, basta analisar os processos Java pelo comando:
jps
Assim, os comandos podem então ser executados no Hadoop para operação no HDFS. Os exemplos práticos serão divididos em subseções deste bloco.
mkdir e ls
Como primeira interação oficial com o HDFS, o comando abaixo poderá ser utilizado para criar o diretório /user/confluence/hdfs no sistema de armazenamento distribuído:
hdfs dfs -mkdir -p /user/confluence/hdfs
Como o caminho de criação solicitado possui, em sua formação, diretórios que ainda não existiam no HDFS, o parâmetro -p foi adicionado ao comando para garantir que os diretórios "pais" sejam criados ao longo do processo. Para visualizar o resultado, o comando ls pode ser utilizado na seguinte sintaxe:
hdfs dfs -ls /user/confluence
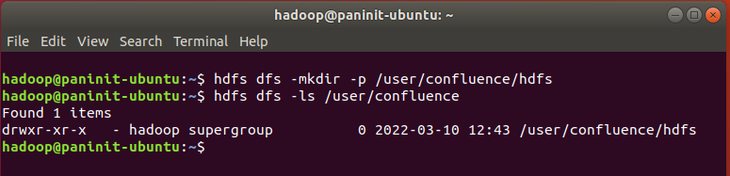
Neste ponto, é importante reforçar que o novo diretório foi criado e existe apenas no HDFS. Esta é a grande virada de chave que precisa ser realizada para que se possa compreender, de fato, a atuação de um sistema de armazenamento distribuído na instalação do Hadoop realizada. Como comprovação, caso o usuário tente listar este diretório utilizando um comando Unix (como o ls puro), nenhum resultado será obtido.
put e copyFromLocal
Os comandos put e copyFromLocal copiam arquivos presentes no sistema de armazenamento local para o HDFS. Ambos possuem o mesmo efeito. Para testá-los, serão criados arquivos de testes no ambiente local para sua posterior cópia para o HDFS. Para isso, os comandos Linux podem ser utilizados:
echo "Arquivo de teste 01" > put_file.txt
echo "Arquivo de teste 02" > copyfromlocal_file.txt
Antes de executar os comandos, é possível listar novamente o conteúdo do diretório recém criado no HDFS e garantir que não há nenhum arquivo presente:
hdfs dfs -ls /user/confluence/hdfs

Assim, a cópia dos arquivos locais pra este diretório do HDFS pode então ser feita via:
hdfs dfs -put /home/hadoop/put_file.txt /user/confluence/hdfs
hdfs dfs -copyFromLocal /home/hadoop/copyfromlocal_file.txt /user/confluence/hdfs
Após isso, é possível validar novamente a existência dos arquivos no diretório alvo do HDFS.

Por fim, é importante citar que os arquivos put_file.txt e copyfromlocal_file.txt permanecem existentes no ambiente local, visto que foi realizada uma cópia e não uma movimentação.
get e copyToLocal
Para garantir e validar a eficiência dos comandos get e copyToLocal, vamos primeiro deletar os arquivos put_file.txt e copyfromlocal_file.txt criados anteriormente para testes em comandos anteriores. Assim, será possível analisar se os arquivos do HDFS foram devidamente copiados para o ambiente local.
rm put_file.txt copyfromlocal_file.txt

Para realizar a cópia dos arquivos presentes no HDFS para o ambiente local, é possível então executar os comandos:
hdfs dfs -get /user/confluence/hdfs/put_file.txt /home/hadoop
hdfs dfs -copyToLocal /user/confluence/hdfs/copyfromlocal.txt /home/hadoop
Com uma nova verificação no armazenamento local, é possível visualizar os arquivos copiados do HDFS

mv
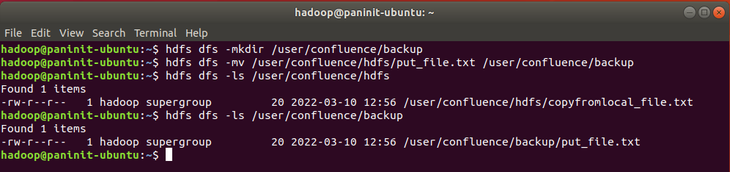
Para validar a execução do comando mv no HDFS, será criado um novo diretório através do comando:
hdfs dfs -mkdir /user/confluence/backup
Com isso, será possível mover um arquivo entre diretórios através do comando:
hdfs dfs -mv /user/confluence/hdfs/put_file.txt /user/confluence/backup
Para validar o sucesso, é possível listar os arquivos nos diretórios antigo e novo. Neste caso, é possível perceber que o arquivo foi literalmente movido para o novo diretório, se tornando inexistente no caminho antigo.
moveFromLocal
O comando moveFromLocal pode ser utilizado para mover arquivos de ambientes locais para o HDFS.
hdfs dfs -moveFromLocal /home/hadoop/put_file.txt /user/confluence/hdfs
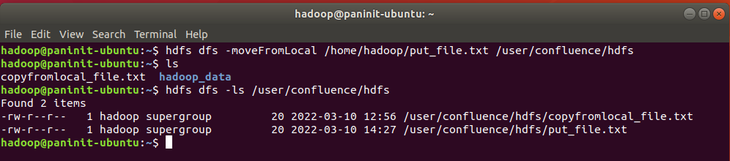
cat
Para visualizar o conteúdo de um arquivo no HDFS, o comando abaixo pode ser utilizado:
hdfs dfs -cat /user/confluence/hdfs/put_file.txt

rm, rmr e rmdir
Antes de testar os três comandos de remoção de arquivos ou diretórios no HDFS, vamos avaliar o conteúdo presente nos diretórios alvos da aplicação:
hdfs dfs -ls /user/confluence/hdfs
hdfs dfs -ls /user/confluence/backup
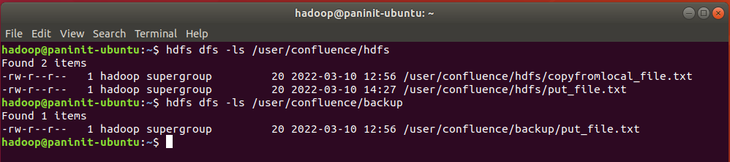
Através dos resultados dos comandos, é possível perceber que o diretório /user/confluence/hdfs possui os arquivos put_file.txt e copyfromlocal_file.txt. Já o diretório /user/confluence/backup possui apenas o arquivo put_file.txt.
Para remover o arquivo copyfromlocal_file.txt é possível utilizar o comando:
hdfs dfs -rm /user/confluence/hdfs/copyfromlocal_file.txt

Ao tentar remover um diretório com o comando rm, o seguinte resultado é obtido:
hdfs dfs -rm /user/confluence/hdfs

Dessa forma, o comando rm é utilizado apenas para remoção de arquivos. Para remover diretórios vazios, o comando rmdir pode ser utilizado no seguinte formato:
hdfs dfs -rmdir /user/confluence/backup
Entretanto, considerando que o diretório fornecido não está vazio, o seguinte resultado é obtido:

De modo a propor uma solução definitiva, o comando rmr (ou rm - r em versões mais recentes) atua como uma remoção recursiva, permitindo assim que eliminações possam ser feitas em diretórios que não estão vazios.
hdfs dfs -rmr /user/confluence/backup

Após a deleção recursiva, é possível visualizar agora quais diretórios estão presentes no caminho /user/confluence. Com o resultado da imagem abaixo, percebe-se que o diretório /user/confluence/backup foi eliminado assim como o arquivo put_file.txt que estava armazenado no mesmo.

du e dus
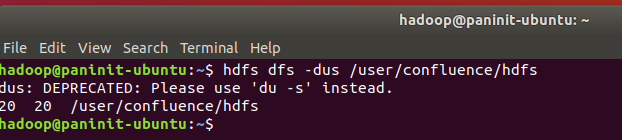
Para visualizar dados relacionados ao volume de cada arquivo presente em um diretório específico, o comando du pode ser utilizado no seguinte formato:
hdfs dfs -du /user/confluence/hdfs

No exemplo acima, apenas o arquivo put_file.txt existe abaixo do diretório alvo. Caso o objetivo seja analisar o volume resumido do diretório, o parâmetro -s pode ser adicionado ao comando du ou o então o comando dus (em versões antigas) pode ser utilizado.
hdfs dfs dus /user/confluence/hdfs
stat
Para visualizar a data de última modificação do arquivo, o comando stat pode ser utilizado na seguinte sintaxe:
hdfs dfs -stat /user/confluence/hdfs/put_file.txt





