

SparkSQL e a Transformação de Dados com SQL

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! No último artigo, foi possível discutir tópicos relacionados à transformação de dados no Spark e sua atuação dentro da dinâmica de planejamento e execução das instruções computacionais programadas.
Neste ponto da jornada de aprendizado, vimos como métodos específicos de transformação (where(), orderBy(), por exemplo) puderam ser aplicados em objetos DataFrames de modo a codificar instruções posteriormente avaliadas pelo Spark de maneira lazily. Em vias gerais, este tipo de abordagem exige, de certa forma, um certo conhecimento na linguagem de programação utilizada para interagir com o Spark. O quão fácil seria utilizar algo universal, não é mesmo?
Assim, o objetivo deste artigo é fornecer uma visão alternativa e extremamente poderosa à abordagem de transformação fornecida anteriormente de modo a viabilizar o uso de linguagem SQL para transformar os dados em Spark.
Embarque nessa jornada!
Conhecendo o SparkSQL
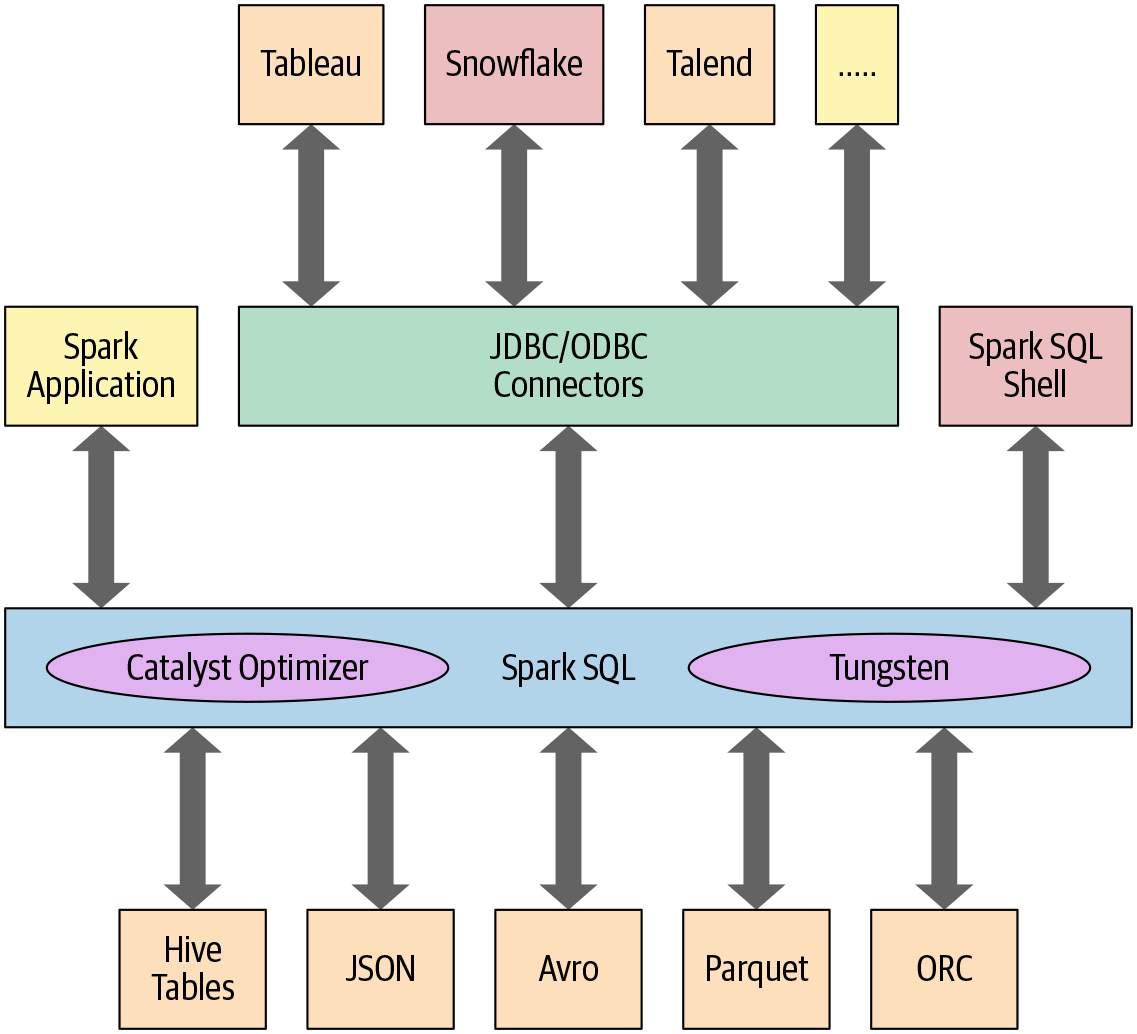
Em uma visão direta, o SparkSQL é um componente do Spark que possibilita aos desenvolvedores a submissão de queries SQL (compatíveis com ANSI SQL:2003) em dados estruturados. Desde sua introdução ao ecossistema a partir da versão 1.3 do Spark, uma série de evoluções e melhorias foram aplicadas até que, atualmente, o motor SparkSQL é uma das ferramentas substancialmente essenciais no uso do conjunto de aplicações de alto nível construídas em Spark. Algumas de suas principais características são:
- Unificação dos componentes Spark e uma abstração a DataFrames/Datasets em Java, Scala, Python e R, o que simplifica grandemente o trabalho com dados estruturados
- Conexão com o metastore do apache Hive e acesso às tabelas
- Leitura e escrita de dados estruturados com schema bem definido nos mais variados formatos (JSON, CSV, Text, Avro, Parquet, ORC, etc) e conversão de coleções distribuídas de dados em tabelas temporárias
- Rápida exploração de dados e consultas ad-hoc com Spark SQL shell
- Conexões via JDBC e ODBC
No decorrer dos tópicos subsequentes, uma visão técnica detalhada sobre os principais conceitos do SparkSQL será fornecida para que, no anseio da aplicação prática, os elementos e as operações estejam completamente endereçadas.
Utilizando SparkSQL em uma SparkSession
Em outros momentos desta série, foi possível definir uma sessão (SparkSession) como um ponto central de entrada para aplicações Spark acessarem todas as funcionalidades disponíveis. Nas shells interativas (spark-shell, pyspark, spark-sql, sparkR), o objeto de sessão é criado automaticamente para o usuário e disponibilizado sob a variável spark. Em ambientes específicos e scripts próprios, é necessário que o usuário crie este objeto por conta própria e, por convenção, utiliza-se uma variável de mesmo nome.
Assim, para executar queries SQL em conjuntos de dados estruturados, basta chamar o método spark.sql() do objeto de sessão e passar uma query como argumento:
# Exemplo de query executada via SparkSQL
df = spark.sql("""
SELECT * FROM <table>
""")
No bloco de código acima, é possível notar uma propriedade interessante: as queries executadas neste formato resultam em um objeto DataFrame do Spark que, posteriormente, pode ser trabalhado através de múltiplas transformações ou mesmo utilizado para criar novas tabelas temporárias.
Bancos de dados, tabelas e views
No artigo sobre leitura de fontes externas via Spark, os exemplos construídos para obtenção de objetos DataFrame estavam associados, em sua totalidade, a arquivos físicos salvos localmente em disco.
Assim como em outras ferramentas análogas, o Spark possui um conceito de tabela como um elemento responsável por armazenar dados. Em sua concepção, uma tabela no Spark pode ser gerenciada internamente, externamente ou mesmo ser temporária (view). Associado a cada tabela no Spark estão seus metadados, schema, descrição, nome de referência, nome do banco de dados, nome das colunas, partições, localização física dos dados, entre outros. Em um ambiente distribuído, ao invés de utilizar um metastore separado por conta própria, o Spark, por padrão, utiliza o metastore do Apache Hive localizado em /user/hive/warehouse para persistir os metadados de suas tabelas.
Em uma visão holística, os subtópicos desta seção serão consolidados de modo a proporcionar um primeiro contato básico com as funcionalidades do SparkSQL direcionadas à criação dos elementos centrais de armazenamento de dados.
Criando bancos de dados
Criar um banco de dados pode ser considerada uma tarefa opcional dentro da dinâmica de uso do SparkSQL. Considerando a instalação local utilizada nos exemplos propostos, o Spark cria automaticamente uma entrada local para armazenamento das tabelas temporárias em um diretório chamado spark-warehouse. De toda forma, a criação de bancos de dados pode ser uma atividade necessária em alguns cenários e, de maneira altamente intuitiva, sua execução segue a sintaxe padrão SQL para tal:
# Criando database via SparkSQL (opcional)
spark.sql("CREATE DATABASE IF NOT EXISTS paninitlab")
spark.sql("USE paninitlab")
Assim, ao executar este comando, um novo banco de dados chamado paninitlab é criado e selecionado para ser o elemento centralizador das queries posteriores. Visualmente, considerando novamente a instalação local do Spark, é possível notar a existência de um novo diretório para o banco de dados dentro de spark-warehouse:
spark-warehouse/
├── paninitlab.db
Criando tabelas gerenciadas externamente
O conceito de uma tabela gerenciada externamente (ou externally managed table ou simplesmente unmanaged table) segue os mesmos princípios de outras ferramentas, como o Hive, por exemplo: uma tabela desta categoria indica o gerenciamento apenas de seus metadados, e não dos arquivos físicos que a compõem. Como principal característica, dropar uma tabela gerenciada externamente não significa eliminar os arquivos físicos de sua formação.
Assim como nos bancos de dados, o processo de criação de tabelas em Spark, sejam estas gerenciadas externamente ou internamente, seguem as mesmas características encontradas em ferramentas análogas. No exemplo de código abaixo, uma nova tabela é criada utilizando o formato CSV como origem em uma localização física representada pelo do bloco LOCATION. Adicionalmente, uma opção de configuração para o header é inserida no bloco OPTION, informando assim que o arquivo original possui o cabeçalho na primeira linhas.
# Dropando e criando tabela
spark.sql("DROP TABLE IF EXISTS flights_data")
spark.sql("""
CREATE EXTERNAL TABLE IF NOT EXISTS flights_data (
DEST_COUNTRY_NAME STRING,
ORIGIN_COUNTRY_NAME STRING,
count INT
)
-- Definindo formato de origem
USING csv
-- Definindo opções
LOCATION '/home/hadoop/dev/panini-tech-lab/data/flights-data/summary-data/csv/2015-summary.csv'
OPTIONS (
header="true"
)
""")
E assim, a tabela no Spark agora existe e pode ser consultada através de uma query qualquer.
# Selecionando dados
df_flights_external = spark.sql("""
SELECT * FROM flights_data LIMIT 5
""")
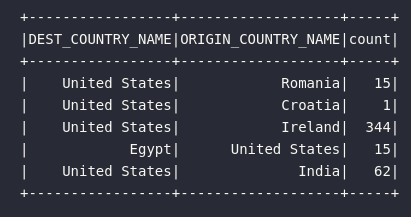
df_flights_external.show()
Com a aplicação da ação show(), é possível então visualizar o DataFrame resultante que, por sua vez, é essencialmente formado pelo conteúdo do arquivo CSV passado como parâmetro da query de criação da tabela:
Criando views (tabelas temporárias)
Em SparkSQL, o conceito de views está intimamente ligado à tabelas temporárias. Na prática, uma view criada no Spark não armazena qualquer tipo de dado e deixa de existir assim quando encerrada a aplicação. O processo de criação de views é análogo ao processo de criação de tabelas demonstrado anteriormente, entretanto existe uma particularidade extremamente poderosa: é possível criar views a partir de outros DataFrames utilizando o método característico createOrReplaceTempView().
Para demonstrar as funcionalidades de tabelas temporárias no Spark, o bloco de código abaixo realiza a leitura de um arquivo CSV salvo localmente em um DataFrame com a posteior criação de uma view para consulta:
# Lendo dados
csv_path = '/home/hadoop/dev/panini-tech-lab/data/flights-data/summary-data/csv/2015-summary.csv'
df_flights = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load(csv_path)
# Criando tabela temporária (view)
df_flights.createOrReplaceTempView("vw_flights_data")
E assim, a tabela temporária existe dentro da aplicação Spark (por não ser uma GlobalTempView, este elemento é restrito apenas à sessão de origem) e pode ser consultada através da linguagem SQL:
# Consultando view
df_flights_view = spark.sql("""
SELECT * FROM vw_flights_data LIMIT 5
""")
# Visualizando dados
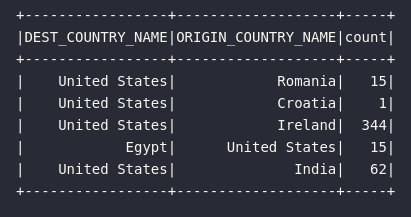
df_flights_view.show()
Como esperado, o resultado é um DataFrame capaz de ser posteriormente transformado ou então utilizado para criação de uma nova tabela temporária.
Em termos práticos, pode ser muito mais fácil para um usuário Spark seguir esta linha de raciocínio para testar e validar consultas SQL dentro de um pipeline de transformação de dados. A criação de tabelas temporárias pode auxiliar no desenvolvimento de um fluxo de uma maneira mais veloz.
Visualizando metadados
Por fim, ao navegar pelos procedimentos de criação das principais estruturas de dados dentro do universo do SparkSQL, é possível utilizar alguns comandos característicos em uma sessão para retornar os metadados disponíveis. Os métodos disponíveis estão presentes dentro do módulo spark.catalog e alguns exemplos podem ser visualizados abaixo:
# Visualizando databases
spark.catalog.listDatabases()
# Visualizando tabelas
spark.catalog.listTables()
# Visualizando colunas de uma tabelas
spark.catalog.listColumns("flights_data")
Operando com SparkSQL
Uma vez conhecidas as principais formas de obter os dados para posterior utilização do SparkSQL, é possível explorar detalhes técnicos e exemplos práticos envolvendo sua operação em si. Sendo uma linguagem universal, o SQL, por sí só, traz consigo uma gigantesca facilidade para seus usuários, permitindo abstrair grande parte da relativa complexidade existente em uma linguagem de programação específica. Afinal, até este ponto da série, os exemplos de transformações fornecidos foram codificados utilizando métodos característicos de DataFrames dentro do cenário de uso do pyspark. O quão necessário seria conhecer sobre a linguagem para possuir autonomia no assunto?
Uma visão de performance
O SparkSQL pode ser considerada uma API estruturada no Spark extremamente poderosa que fornece, a seus usuários, a possibilidade de realizar todo o tipo de transformações utilizando puramente a linguagem SQL. Em outras palavras, operações de filtragem , agrupamento, casting, ordenação e várias outras poderiam, facilmente, serem codificados utilizando SQL em cima de tabelas temporárias no Spark.
E neste momento, é possível pensar que, dada esta facilidade, algum ônus de performance possa existir, afinal, não existe almoço grátis. A excelente notícia vem aí: não há nenhuma diferença de performance entre um fluxo de trabalho construído utilizando métodos de transformação em DataFrames do que o mesmo procedimento escrito puramente em SparkSQL! Parece mágico!
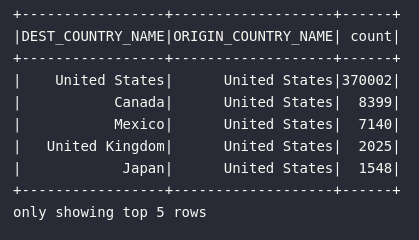
No artigo anterior, um exemplo prático foi fornecido envolvendo a leitura de um arquivo físico e a posterior aplicação de filtros e ordenação dos dados. O objetivo era obter uma visão dos principais vôos (ordenação por contagem) com irgem nos Estados Unidos. Seu código foi dado por:
# Principais destinos de vôos americanos
df_flights_eua_ordered = (df_flights.where("ORIGIN_COUNTRY_NAME = 'United States'")
.orderBy(desc("count")))
# Visualizando dados
df_flights_eua_ordered.show(5)
Posteriormente, ao longo do mesmo artigo citado, o método explain() foi introduzido como uma forma de proporcionar, ao usuário, uma visão sobre as etapas de execução do grafo de instruções de um DataFrame. Para o caso acima, o resultado do método de explicação pode ser visualizado abaixo e, a partir dele, é possível identificar algumas etapas características, como os processos de filtragem e ordenação:
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Sort [count#382 DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(count#382 DESC NULLS LAST, 200), ENSURE_REQUIREMENTS, [id=#659]
+- Filter (isnotnull(ORIGIN_COUNTRY_NAME#381) AND (ORIGIN_COUNTRY_NAME#381 = United States))
+- FileScan csv [DEST_COUNTRY_NAME#380,ORIGIN_COUNTRY_NAME#381,count#382] Batched: false, DataFilters: [isnotnull(ORIGIN_COUNTRY_NAME#381), (ORIGIN_COUNTRY_NAME#381 = United States)], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/hadoop/dev/panini-tech-lab/data/flights-data/summary-data/c..., PartitionFilters: [], PushedFilters: [IsNotNull(ORIGIN_COUNTRY_NAME), EqualTo(ORIGIN_COUNTRY_NAME,United States)], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:int>
Esta retomada foi estrategicamente fornecida para comprovar que o mesmo procedimento ilustrado acima poderia facilmente ser reproduzido utilizando pura e simplesmente a linguagem SQL no Spark e sem nenhuma perda de performance. Para tal, os próximos blocos de código serão responsáveis por simular a mesma transformação de dados (tabela ordenada de vôos com origem nos Estados Unidos) em SparkSQL seguida da validação do plano de execução compilado.
# Principais destinos de vôos americanos (SparkSQL)
df_sql = spark.sql("""
SELECT * FROM vw_flights_data
WHERE ORIGIN_COUNTRY_NAME = 'United States'
ORDER BY count DESC
""")
# Visualizando dados
df_sql.show(5)
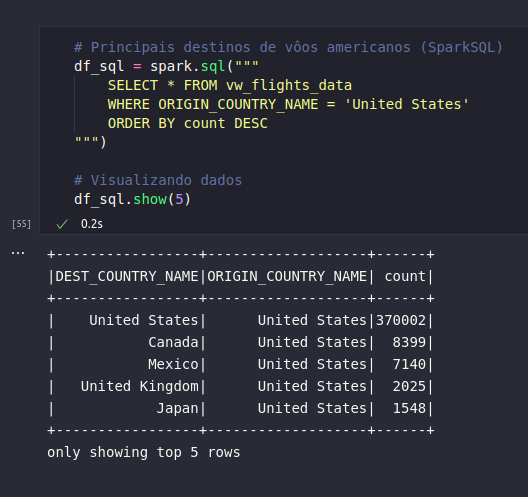
De largada, é possível verificar que o mesmo conjunto de dados foi obtido, indicando assim que a query retornou os dados esperados dentro da proposta de transformação. Por fim, o método explain() será aplicado para visualização do plano de execução criado pelo Spark:
# Visualizando plano de execução
df_sql.explain()
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Sort [count#382 DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(count#382 DESC NULLS LAST, 200), ENSURE_REQUIREMENTS, [id=#689]
+- Filter (isnotnull(ORIGIN_COUNTRY_NAME#381) AND (ORIGIN_COUNTRY_NAME#381 = United States))
+- FileScan csv [DEST_COUNTRY_NAME#380,ORIGIN_COUNTRY_NAME#381,count#382] Batched: false, DataFilters: [isnotnull(ORIGIN_COUNTRY_NAME#381), (ORIGIN_COUNTRY_NAME#381 = United States)], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/hadoop/dev/panini-tech-lab/data/flights-data/summary-data/c..., PartitionFilters: [], PushedFilters: [IsNotNull(ORIGIN_COUNTRY_NAME), EqualTo(ORIGIN_COUNTRY_NAME,United States)], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:int>
O resultado é direto: as transformações desenvolvidas através de métodos aplicados a DataFrames e as query aplicada via SparkSQL resultam no mesmo plano de execução compilado pelo Spark, garantindo assim que ambos os processos terão a mesma performance. Em outras palavras, não há qualquer perda de performance em construir a lógica de transformação de uma aplicação Spark puramente via SparkSQL.
Exemplos de transformação
Considerando os pontos explicados, o poder do SparkSQL pôde ser demonstrado através de exemplos relativamente simples. Sua capacidade total se mostra ainda mais relevante quando existem necessidades atreladas à construção de jobs complexos com múltiplas transformações que poderiam gerar um script mais denso caso programados unicamente através de métodos de DataFrames. Além de tudo, os cenários não são exclusivos: é tranquilamente possível mesclar o uso dos métodos com SparkSQL dentro de uma aplicação. Afinal, no fundo, tudo vira bytecode Java compilado e otimizada para execução dentro do cluster de computadores.
Para demonstrar algumas outras transformações, os blocos de código abaixo serão estrategicamente codificados para retornar dados de vôos em alguns cenários específicos.
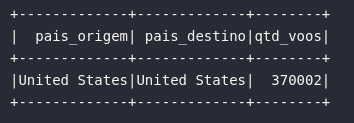
1) Vôos com origem e destino nos EUA
# Vôos com origem e destino nos EUA
df1 = spark.sql("""
SELECT
ORIGIN_COUNTRY_NAME AS pais_origem,
DEST_COUNTRY_NAME AS pais_destino,
count AS qtd_voos
FROM vw_flights_data
WHERE ORIGIN_COUNTRY_NAME = 'United States'
AND DEST_COUNTRY_NAME = 'United States'
""").show(5)
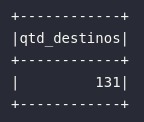
2) Quantidade de países distintos escolhidos como destino de vôos americanos
# Quantidade de destinos
df2 = spark.sql("""
SELECT
count(1) AS qtd_destinos
FROM (
SELECT
DEST_COUNTRY_NAME
FROM vw_flights_data
WHERE ORIGIN_COUNTRY_NAME = 'United States'
AND DEST_COUNTRY_NAME != 'United States'
)
""").show()
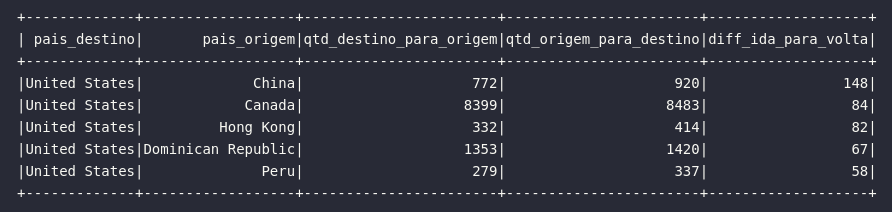
3) País com maiores diferenças entre idas para os EUA do que viagens vindas do EUA
# Retornando top 5 países com maior diferença entre viagens de ida para os EUA do que viagens de volta
df3 = spark.sql("""
WITH american_flights_destination AS (
SELECT
ORIGIN_COUNTRY_NAME,
DEST_COUNTRY_NAME,
count
FROM vw_flights_data
WHERE DEST_COUNTRY_NAME = 'United States'
AND ORIGIN_COUNTRY_NAME != 'United States'
),
american_flights_origin AS (
SELECT
ORIGIN_COUNTRY_NAME,
DEST_COUNTRY_NAME,
count
FROM vw_flights_data
WHERE ORIGIN_COUNTRY_NAME = 'United States'
AND DEST_COUNTRY_NAME != 'United States'
)
-- Países com maior diferença entre viagens de ida e volta
SELECT
d.DEST_COUNTRY_NAME AS pais_destino,
d.ORIGIN_COUNTRY_NAME AS pais_origem,
o.count AS qtd_destino_para_origem,
d.count AS qtd_origem_para_destino,
(d.count - o.count) AS diff_ida_para_volta
FROM american_flights_destination AS d
INNER JOIN american_flights_origin AS o
ON (d.ORIGIN_COUNTRY_NAME = o.DEST_COUNTRY_NAME)
ORDER BY diff_ida_para_volta DESC
LIMIT 5
""")
df3.show()
Conclusão e encerramento
E assim, encerramos mais um importante artigo desta sólida série sobre o Apache Spark. Conhecer as funcionalidades do SparkSQL é um milestone extremamente relevante dentro da jornada de aprendizado. Seu poder torna o uso do Spark universal.
Foi ótimo ter você por aqui. Te aguardo no próximo artigo!




