

Bônus: integrando Spark ao Amazon S3

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! Nos últimos artigos, abordamos dois tópicos altamente relevantes e amplamente utilizados na construção de fluxos de trabalho no Spark: tratam-se dos processos de leitura e escrita de fontes externas através das classes DataFrameReader e DataFrameWriter, respectivamente. Se você perdeu algo, não deixe de conferir tais assuntos clicando nos links abaixo.
Nos artigos citados, a temática proposta envolveu um breve mergulho em conceitos teóricos seguidos de experimentações práticas focadas em situações reais de trabalho capazes de serem vivenciadas no dia a dia de uso do Spark. Em todas elas, os processos de leitura e escrita estiveram sempre atrelados a arquivos físicos salvos localmente em disco. Entretanto, sabe-se que, no universo de Big Data, os dados são de tal modo volumosos que seu armazenamento em um único disco se torna um processo inviável, exigindo assim algum tipo de armazenamento distribuído.
Assim, este artigo tem por objetivo centralizar exemplos e conceitos relacionados a leitura e escrita de dados presentes no Amazon S3 a partir de uma instância local do Apache Spark utilizando o pyspark em um Jupyter Notebook. A conexão será realizada através do conector s3a e as configurações para viabilizar esta rota serão dadas a partir da obtenção de arquivos JAR contendo as classes Java necessárias para o processo.
Por mais que tudo possa parecer meio complexo neste momento, os tópicos consolidados neste artigo possuem um objetivo claro de detalhar todos os principais pontos necessários para um completo entendimento. O leitor terá em mãos explicações teóricas, exemplos práticos e até desenhos de solução criados para facilitar o acompanhamento e o desenvolvimento dos códigos. Embarque nesta jornada!
Considerações gerais
De início, é importante citar que realizar a conexão e integração de uma instância local do Spark com o serviço S3 da AWS é um processo que exige algumas configurações relativamente complexas. De modo a proporcionar uma experiência completa ao leitor deste artigo, os tópicos abaixo irão endereçar premissas, desafios e obstáculos a serem mapeados durante o acompanhamento dos procedimentos.
Diagrama da solução
Visando esclarecer toda a estruturação proposta por este artigo, a imagem abaixo contempla um diagrama contendo alguns elementos fundamentais utilizados no processo:
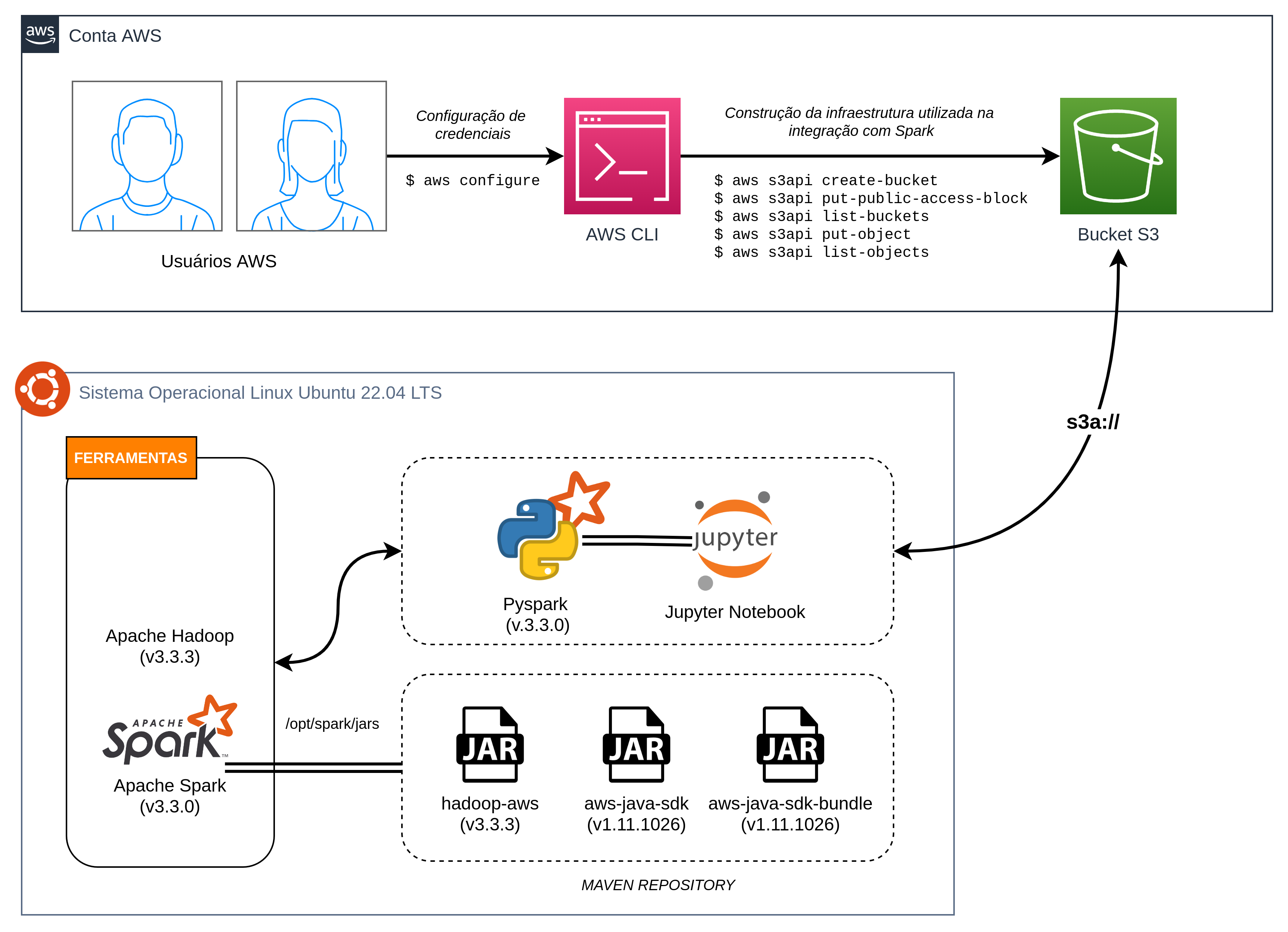
Analisando o diagrama, é possível perceber a presença de ferramentas e componentes externos ao Spark que precisam ser endereçados para o devido funcionamento da integração proposta. Na sequência, será fornecida uma visão importante sobre todos os recursos necessários para possibilitar operar no S3 através do Spark local.
Premissas e ferramentas necessárias
Em uma visão holística, a replicação dos passos a serem consolidados neste artigo depende dos seguintes elementos:
- Hadoop instalado na máquina
- Spark instalado na máquina
- Uma conta AWS e um usuário com permissões adequadas para operar no S3
- Bucket S3 com arquivos a serem utilizados na leitura via Spark
- JARs (Java Archive) específicas para permitir a integração entre Hadoop e AWS
Nem todos os itens acima estão sendo contemplados neste artigo, visto que seria um processo realmente longo. Alguns deles já foram explorados em artigos anteriores desta mesma série ou em outras séries deste mesmo blog. Por exemplo, a instalação e configuração do Apache Hadoop pode ser conferida neste link, enquanto a instalação do Apache Spark pode ser vista neste link.
Em relação ao ambiente AWS, é importante citar que o leitor pode se considerar livre para utilizar qualquer ambiente já existente e de sua posse, seja este contendo dados produtivos ou apenas exploratórios. De toda forma, visando abranger todos os públicos, este artigo trará algumas seções opcionais com detalhes sobre como criar um bucket no S3 e realizar a ingestão de arquivos através de chamadas de API via AWS CLI.
Por fim, também será possível visualizar, neste artigo, todos os passos necessários para obtenção dos arquivos JARs exigidos no processo de configuração da conexão entre Spark e S3.
Desafios de configuração
Ao consultar as diversas fontes disponíveis na internet para viabilizar o processo de integração entre Spark e S3, uma série de desafios se fizeram presentes. Grande parte deles envolveram as versões dos arquivos JARs para configurar as classes Java necessárias para garantir a conexão.
Após muito testar, errar, explorar, consertar e compreender, foi possível alcançar um cenário de sucesso a partir de uma rota envolvendo versões específicas do Hadoop, Spark e dos arquivos JARs necessários. Dessa forma, é importante registrar detalhes sobre o ambiente utilizado no processo:
- Apache Hadoop versão 3.3.3
- Apache Spark e
pysparkversão 3.3.0
A listagem acima não indica uma necessidade explícita do leitor em possuir as mesmas versões para efetivar a leitura e escrita de dados do S3 pelo Spark, mas as diferenças entre os ambientes terão impacto na escolha das versões das JARs a serem obtidas. Em outras palavras, para cada versão diferente do Hadoop instalado, um conjunto distinto de versões dos arquivos JAR se fazem presentes. Dessa forma, para o Hadoop versão 3.3.3 utilizado na construção dos exemplos deste artigo, as versões dos arquivos JAR são dadas por:
hadoop-aws-3.3.3.jaraws-java-sdk-bundle-1.11.1026.jar
É importante que as versões sejam estritamente respeitadas para o sucesso da operação. Qualquer diferença nas versões aceitas pelo Hadoop retornarão erros nas tentativas de ler ou escrever dados do S3 pelo Spark. Felizmente, os arquivos JAR necessários estão presentes por padrão na instalação do Hadoop, sendo possível obtê-los diretamente do sistema operacional. Este procedimento será detalhado futuramente neste artigo.
Documentação oficial
Quando se fala na integração entre Spark e S3, uma densa fundamentação teórica se faz presente, principalmente quando se deseja ir à fundo em tópicos como armazenamento distribuído ou conectores (s3, s3n ou s3a).
Como o objetivo deste artigo é simplesmente fornecer um passo a passo para leitura e escrita de dados do S3 utilizando o Spark, grande parte dos detalhes técnicos serão abstraídos. Entretanto, como forma de estabelecer uma fonte oficial de consulta aos leitores, o tutorial presente na documentação oficial de integração do Hadoop com o S3 aborda todos os tópicos necessários para um completo entendimento do relacionamento entre ambas as ferramentas.
E assim, todos os pontos prévios fundamentais para o consumo deste artigo foram devidamente mapeados. A partir deste ponto, o tutorial tomará forma e o leitor poderá consumir o conteúdo de acordo com sua necessidade, desde a configuração detalhada do acesso programático na AWS via AWS CLI ou mesmo indo direto ao ponto onde a obtenção dos arquivos JAR é explicada.
(Opcional) Configurando o ambiente AWS
Como informado anteriormente, é notório estabelecer que, para testar as operações de leitura e escrita de dados do S3 pelo Spark, é preciso ter um ambiente AWS com um bucket criado e dados disponíveis para uso. Neste ponto, é provável que parte dos leitores já possuam este ambiente devidamente configurado e pronto para uso. Entretanto, imaginando que este não é o cenário para a totalidade do público, esta seção possui um caráter opcional e pode ser consumida por aqueles que já possuem uma conta AWS criada, porém desejam criar um bucket específico para se tornar alvo da integração proposta.
Dessa forma, aqueles que desejam analisar os passos de integração feitos exclusivamente do lado do Spark podem avançar até a próxima seção. Para os demais, é feito um convite para seguir consumindo este artigo de maneira sequencial para habilitar toda a infraestrutura necessária.
(Opcional) Sobre o Amazon S3
Por mais que a intenção deste artigo (e de toda esta série sobre Spark) seja direcionar esforços para exemplificar temas característicos ao ecossistema Spark, quando suas fronteiras se expandem de tal forma a fazer intersecção com assuntos de cunho tecnológico relevante, é de grande valia reservar um pequeno espaço para explorar alguns outros conceitos complementares.
O Amazon S3 é um serviço AWS amplamente utilizado em cenários de armazenamento de dados, principalmente no universo de Big Data. Sua documentação oficial é rica em detalhes e pode ser consumida para um entendimento mais específico sobre o serviço.
No contexto deste artigo, o S3 será utilizado como principal ferramenta de armazenamento de dados a serem posteriormente lidos ou escritos através de uma instância local do Apache Spark. Existem diversos outros serviços nativos da AWS que facilitam essa integração, como o AWS Glue ou o Amazon EMR.
(Opcional) Instalando o AWS CLI
Como um primeiro passo no âmbito da configuração do ambiente, é importante considerar a instalação do AWS CLI, a linha de comando para utilização de chamadas de API para a AWS. Por meio dela, será possível executar alguns comandos essenciais no contexto proposto, como por exemplo:
- A criação de um bucket S3
- Upload de um arquivo CSV a ser posteriormente lido pelo Spark
Para instalar o AWS CLI, basta seguir as instruções propostas pelo link de acordo com o sistema operacional de uso. Após isso, para validar o sucesso da instalação, basta executar o comando abaixo:
aws --version

Com essa validação, será possível então seguir para a próxima etapa de configuração envolvendo o fornecimento das chaves de acesso de um usuário com acesso programático na AWS.
(Opcional) Fornecendo chaves de acesso
Possuir o AWS CLI é importante, porém sem a devida configuração necessária, seu uso se torna inviável. Assim, considerando os passos exemplificados na página oficial de setup do AWS CLI, é importante ter em mãos dois elementos fundamentais que contemplam a dinâmica de acesso programático na AWS:
- Uma chave de acesso (Access Key ID)
- Uma chave secreta de acesso (Secret Key ID)
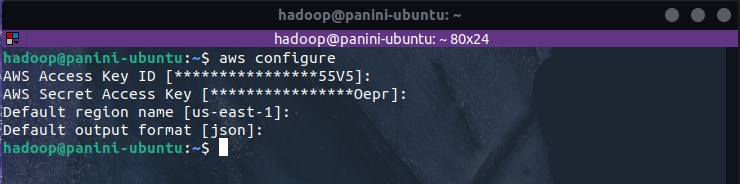
Assim, no terminal do sistema operacional, basta executar o comando aws configure e seguir as instruções solicitadas de modo a fornecer os parâmetros de configuração exigidos.
(Opcional) Criando bucket S3
O próximo passo da jornada de configuração envolve a criação de um bucket S3 a ser tomado como alvo dos processos de leitura e escrita dentro do Spark. Este processo pode ser feito de várias maneiras distintas, seja utilizando o console, ou de maneira programática via AWS CLI ou algum SDK de preferência.
Considerando um maior nível de reprodutibilidade do processo, é possível utilizar o código abaixo para criação de um bucket S3 através da linha de comando. Basta substituir o termo bucket_name por um nome de bucket globalmente único.
aws s3api create-bucket --bucket <bucket_name> --acl private
Na sequência, visando garantir um nível maior de segurança para os objetos a serem posicionados neste bucket (mesmo que não seja obrigatório para as atividades deste artigo, mas aproveitando o momento para navegar por mais exemplos do AWS CLI), o código abaixo pode ser utilizado para bloquear todo acesso público ao bucket recém criado:
aws s3api put-public-access-block \
--bucket <bucket_name> \
--public-access-block-configuration "BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=true"
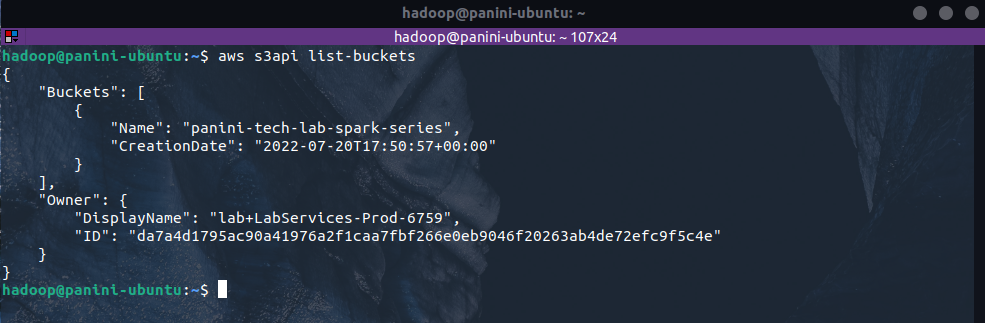
Assim, para validar o sucesso dos códigos executados, é possível utilizar mais uma chamada de API para listagem dos buckets existentes na conta. Sua sintaxe é dada por:
aws s3api list-buckets
Como a conta utilizada para a consolidação dos exemplos possui apenas o bucket recém criado, o resultado esperado é formado apenas por um elemento dentro da chave "Buckets" do JSON de retorno.
E assim a infraestrutura está criada e pronta para uso. Como próximo passo, uma nova chamada de API será realizada para aplicar o processo de upload de um objeto ao bucket recém criado.
Para maiores detalhes sobre os comandos utilizados até o momento, seguem abaixo os links da documentação oficial da AWS:
(Opcional) Realizando upload de arquivo no bucket
A última etapa necessária para preparação do ambiente AWS envolve a ingestão de um arquivo salvo localmente para o armazenamento em nuvem recém criado. Neste momento, é importante citar que o arquivo escolhido para exemplificação dos códigos deste artigo contém dados de vôos realizados nos Estados Unidos. Esta mesma base de dados foi utilizada nos exemplos de leitura e escrita de arquivos consolidados nos dois últimos artigos desta série. Sua obtenção pode ser dada através do github oficial do livro Spark: The Definitive Guide.
Para as demonstrações sequenciais, o arquivo 2015-summary.csv será escolhido para ingestão no S3 e, para aplicar tal processo, basta navegar até o diretório local onde o arquivo está armazenado e executar o seguinte comando:
aws s3api put-object --bucket <bucket_name> --key data/flights-data/summary-data/csv/2015-summary.csv --body 2015-summary.csv
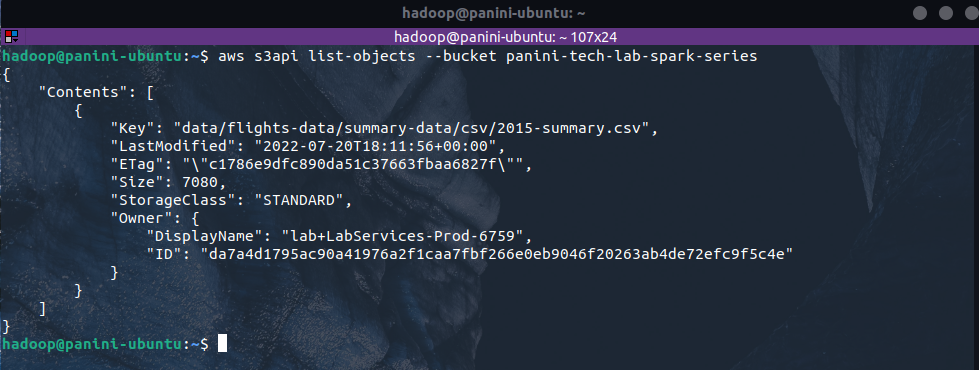
Assim, é esperado que o arquivo alvo esteja agora armazenado no S3 dentro dos prefixos data/flights-data/summary-data/csv/ passados como argumentos da chamada de upload. Para verificar o sucesso da operação, basta executar o comando abaixo para listagem de objetos em um bucket:
aws s3api list-objects --bucket <bucket_name>
O resultado esperado envolve um retorno de chamada contendo informações sobre os objetos presentes no bucket alvo. Nele, será possível identificar o arquivo recém ingerido.
E assim, foi possível concluir todas as etapas preparatórias para configuração do ambiente AWS a ser utilizado nos exemplos de leitura e escrita de dados a partir de uma instância local do Apache Spark instalada. Todos os passos acima foram especialmente descritos e exemplificados para que todos os leitores, independentes do nível de conhecimento em nuvem AWS, possam acompanhar os passos sequenciais de integração. É provável que muitos já possuam seu próprio ambiente configurado com seus próprios buckets e arquivos, o que pode facilitar todo o processo de aprendizagem proposto.
Deste ponto em diante, o foco do artigo será direcionado para nuances, desafios e parâmetros de configuração envolvendo exclusivamente o Apache Spark.
Configurando o ambiente Spark
Após a garantia de que a infraestrutura AWS foi criada e devidamente configurada, é chegado o momento de explorar as ações necessárias pelo lado do Spark para que sua integração com a AWS possa ser realizada.
Em um primeiro disclaimer, é importante citar que a proposta do artigo envolve a utilização do Spark instalado no modo local para ler e escrever dados em um bucket S3 na AWS. Existem outras formas de realizar essa integração, como a própria utilização de alguns serviços nativos da AWS (Glue, EMR, entre outros) mas, considerando possíveis necessidades de testar fluxos em um ambiente local de maneira prévia, saber exatamente a forma de validar este processo é fundamental.
Verificando a versão do Hadoop
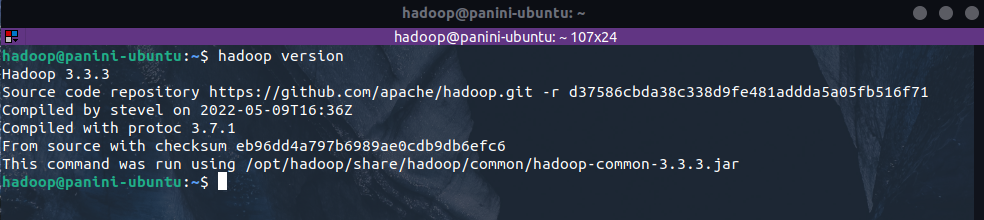
O primeiro passo necessário para uma correta configuração do ambiente é a verificação da versão do Hadoop instalada na máquina. Este processo é importante para selecionar as versões corretas dos arquivos JARs a serem obtidos posteriormente. Para tal, basta inserir o seguinte comando no terminal:
hadoop version
Obtendo JARs
Em software, JAR (Java ARchive) é um arquivo/ficheiro compactado usado para distribuir um conjunto de classes Java, um aplicativo java, ou outros itens como imagens, XMLs, entre outros. É usado para armazenar classes compiladas e metadados associados que podem constituir um programa.
Para viabilizar a conexão via s3a, são necessários dois arquivos JARs:
Arquivos JAR podem ser obtidos através do repositório Maven (links para os dois arquivos necessários dentro do procedimento foram deixados acima). Entretanto, ao instalar o Hadoop no ambiente, alguns arquivos JARs já existem por padrão, incluindo os dois acima citados. Dessa forma, para que o Spark consiga obter as classes Java necessárias para integração com S3, basta validar as versões dos arquivos presentes na instalação do Hadoop e copiá-los até o diretório de jars do Spark.
Normalmente, os arquivos JARs estão presentes no diretório $HADOOP_HOME/share/hadoop/tools/lib/, onde $HADOOP_HOME é o diretório de instalação do Hadoop configurado no arquivo .bashrc. Para validar as versões presentes, os comandos abaixo podem ser utilizados:
ls $HADOOP_HOME/share/hadoop/tools/lib/hadoop-aws*
ls $HADOOP_HOME/share/hadoop/tools/lib/aws-java-sdk*
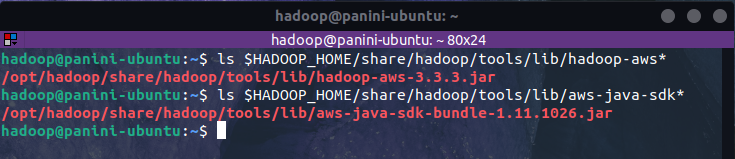
No caso do ambiente utilizado na criação deste artigo, é possível verificar que a JAR hadoop-aws está presente na versão 3.3.3, enquanto a JAR aws-java-sdk-bundle existe na versão 1.11.1026. Isto é extremamente importante pois versões incorretas posicionadas no diretório de JAR do Spark fatalmente retornarão erros nas tentativas de conexão com o S3.
Assim, para copiar os arquivos para o diretório de jars do Spark, os comandos abaixo podem ser utilizados (lembrando de alterar as versões conforme o resultado do comando ls executado previamente):
cp $HADOOP_HOME/share/hadoop/tools/lib/hadoop-aws-3.3.3.jar $SPARK_HOME/jars
cp $HADOOP_HOME/share/hadoop/tools/lib/aws-java-sdk-bundle-1.11.1026.jar $SPARK_HOME/jars
Em caso de erros nos testes posteriores de conexão, é possível que novos arquivos JARs extraídos diretamente do repositório Maven sejam soluções plausíveis.
Lendo dados do S3 com Spark
Enfim, após uma longa jornada de configuração do ambiente, é possível colocar a mão na massa com códigos específicos para integrar o Spark com o S3. Como um primeiro passo, o bloco abaixo realiza a criação de uma SparkSession e aplica alguns parâmetros de configuração necessários para a devida conexão.
# Importando bibliotecas
from pyspark.sql import SparkSession
# Inicializando sessão
spark = SparkSession\
.builder\
.appName("spark-s3")\
.getOrCreate()
# Configurando contexto para integração com AWS
spark._jsc.hadoopConfiguration().set("fs.s3a.access.key", "")
spark._jsc.hadoopConfiguration().set("fs.s3a.secret.key", "")
spark._jsc.hadoopConfiguration().set("fs.s3a.endpoint", "s3.amazonaws.com")
Neste ponto, é importante passar as chaves de acesso nos parâmetros de configuração "fs.s3a.acces.key" e "fs.s3a.secret.key". Com isso, é possível então aplicar o comando de leitura de fontes externas já conhecido, atentando-se apenas à alterar o argumento do método .load() para apontar para a URI correta do objeto presente no bucket S3 escolhido como alvo:
# Lendo dados presentes no S3
df_s3 = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load("s3a://panini-tech-lab-spark-series/data/flights-data/summary-data/csv/2015-summary.csv")
# Visualizando amostra
df_s3.show(5)
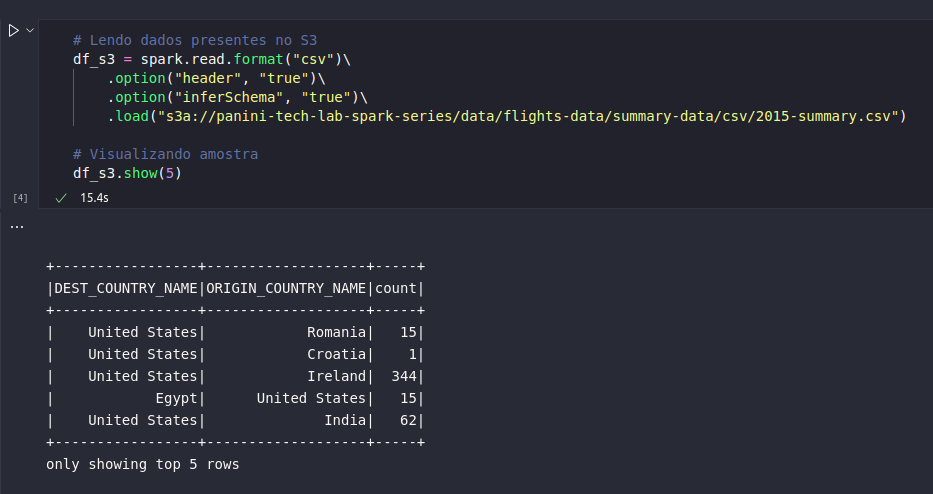
Incrível! Após toda uma densa jornada de configuração, a instalação local do Spark agora se vê pronta para consumir dados presentes no S3 (desde que as permissões AWS estejam estabelecidas). Como principal destaque, vale citar que o comando realizado também utiliza a classe DataFrameReader e possui as mesmas possibilidades de configurações adicionais, como inferência de schema, por exemplo. A grande diferença está no bloco .load() que, ao invés de apontar para caminhos locais de arquivos, agora aponta para a URI do objeto no S3 através do protocolo s3a.
Escrevendo dados no S3 com Spark
De maneira análoga, é possível escrever dados no S3 com o Spark através do comando de escrita já conhecido. No caso do bloco de código abaixo, o mesmo DataFrame lido e armazenado na variável df_s3 será escrito como um objeto parquet em um folder diferente do arquivo original presente no bucket.
# Escrevendo dados no S3
df_s3.write.format("parquet").save("s3a://panini-tech-lab-spark-series/data/flights-data/summary-data/parquet/")
Ao analisar os resultados através do console da AWS, é possível verificar a presença do arquivo no local especificado:
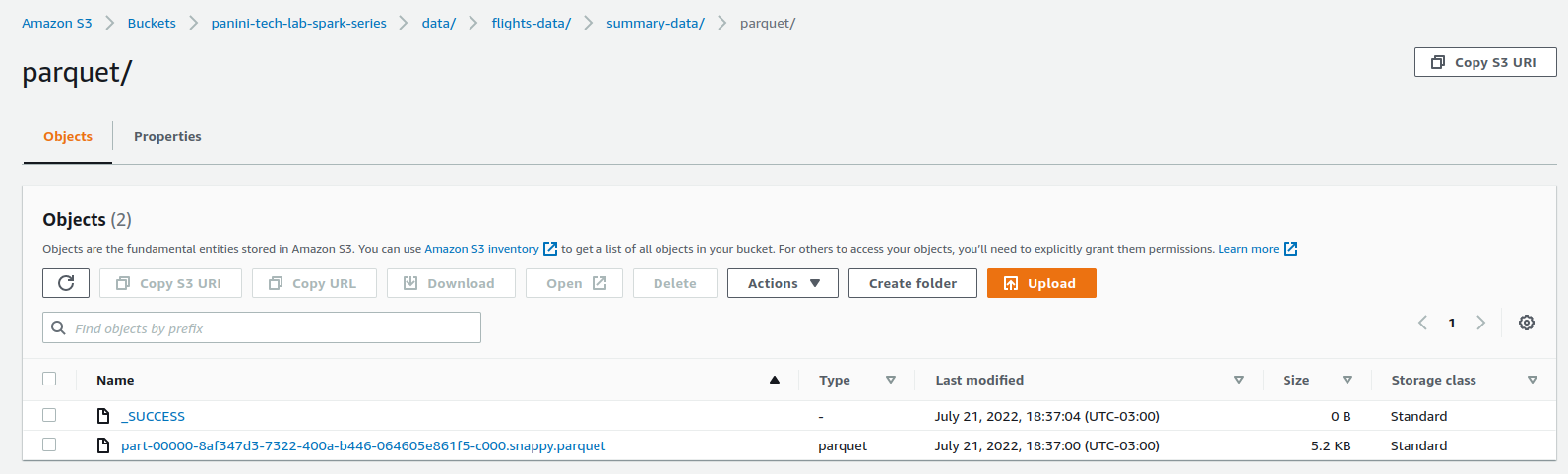
Os mesmos parâmetros de configuração do comando de escrita de DataFrames podem ser utilizados. No exemplo abaixo, será aplicado o processo de particionamento na base para que uma nova partição para cada entrada na coluna DEST_COUNTRY_NAME seja criada.
# Escrevendo dados no S3 com partição
df_s3.write.format("parquet")\
.partitionBy("DEST_COUNTRY_NAME")\
.save("s3a://panini-tech-lab-spark-series/data/flights-data/summary-data/parquet_partitioned/")
Por se tratar de um processo de criação de múltiplos arquivos, o tempo de processamento será mais elevado que o obtido no comando anterior. De toda forma, espera-se que o bucket S3 seja populado com um folder para cada partição da base:
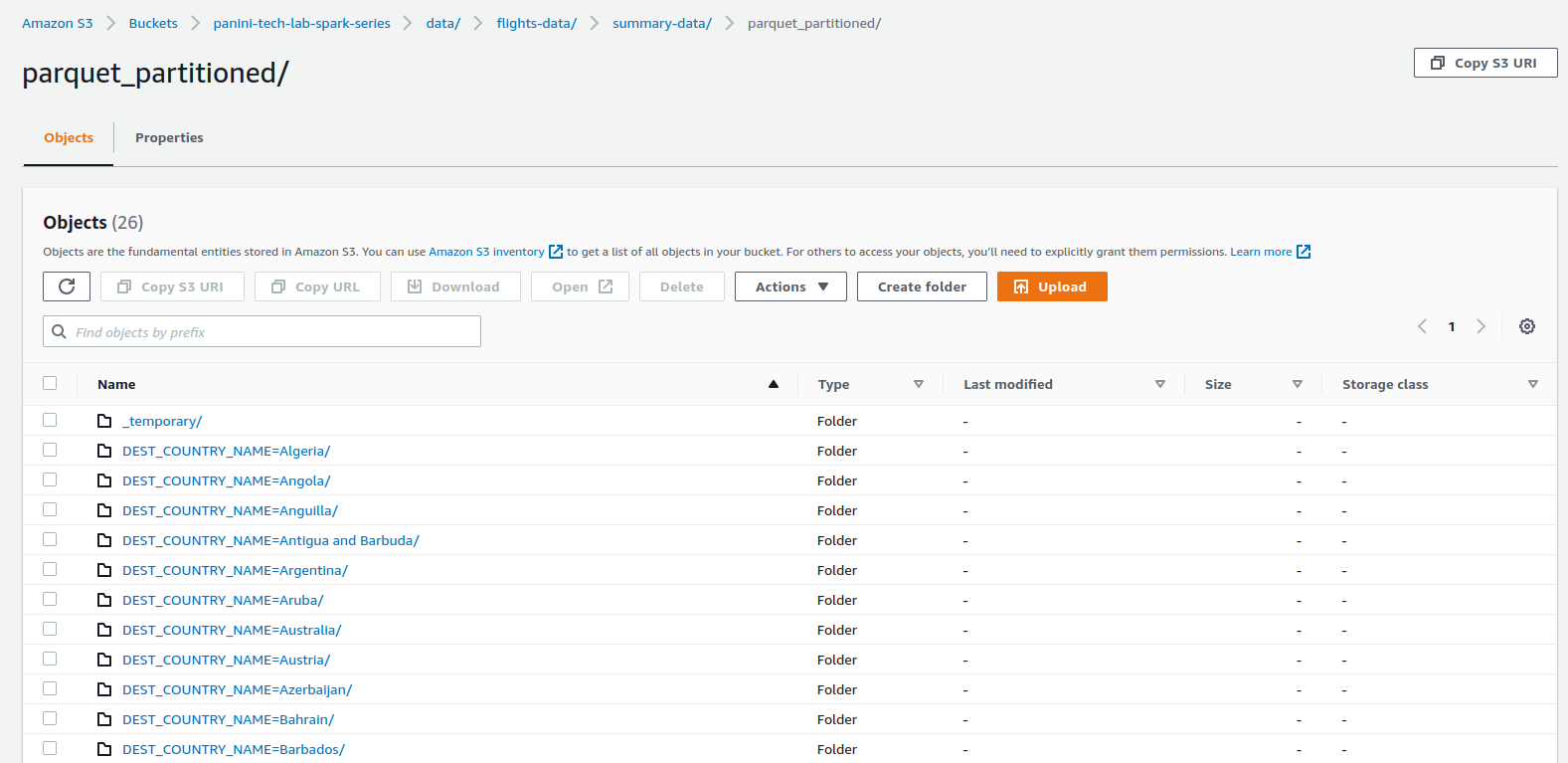
Conclusão e encerramento
Por mais denso que todo este processo tenha sido, o encerramento deste artigo, em especial, é dado com extrema satisfação. Ao longo desta longa jornada, foi possível compreender um pouco melhor sobre o funcionamento prático do Spark em meio às necessidades de consumir dados de sistemas de armazenamento distribuído (no caso, o S3).
De maneira honesta, este artigo não estava presente no planejamento original da série mas, após a criação dos artigos de leitura e escrita de dados (links fornecidos no início), um grande anseio se fez presente por meio de uma fundamental questão: na prática, os usuários terão desafios que dificilmente envolverão leitura e escrita de arquivos locais em disco, afinal, isto basicamente fere os princípios de Big Data... dessa forma, por que não proporcionar um exemplo prático envolvendo a integração do Spark com algo que possa fazer mais sentido na vida real destes usuários, como o S3?
E a resposta para esta pergunta compôs o carma dos últimos dias de escrita deste artigo onde uma série de desafios, obstáculos, pesquisa e testes foram necessários até se chegar a um ponto ótimo de ensinamento. Felizmente, tudo correu bem e uma nova etapa no conhecimento dos leitores pôde ser habilitada.




