

O Guia Definitivo de Transformações em Spark
Um resumo completo sobre métodos de funções utilizadas para criar fluxos de transformações via pyspark

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark!
Na última sequência de artigos, transpassamos uma valorosa flecha de conhecimento nos obstáculos mais profundos envolvendo a transformação de dados utilizando o Spark como nosso grande motor de processamento. E neste esplendoroso épico narrativo, aprendemos a ler, escrever, selecionar, modificar atributos, filtrar registros, agrupar e, por fim, juntar múltiplos conjuntos de dados de modo a moldar diferentes casos analíticos de processamento de dados de acordo com os propósitos de aprendizado estabelecidos.
E assim, após esta longa jornada intencionalmente apresentada em um tom epopeico, uma nova proposta de consolidação dos conhecimentos de transformação de dados em Spark se materializa através deste artigo como uma forma de documentar, em definitivo, grande parte dos métodos e funções abordados até aqui como uma espécie de resumo completo capaz de ser utilizado como fonte direta, prática e objetiva pelos leitores nos mais diferenciados níveis de conhecimento.
Embarque nesta jornada!
Uma nova proposta para os dados
O primeiro passo diante da proposta inédita de consolidação de conteúdo deste artigo envolveu uma tarefa crucial: a escolha de um conjunto de dados. A principal necessidade desta fundamental demanda envolvia a definição de bases suficientemente ricas e dinâmicas capazes de serem alvos consistentes das mais variadas transformações. Em outras palavras, era preciso encontrar uma fonte de dados apropriada para receber os métodos e funções abordados até este momento em um cenário de fácil entendimento pelo leitor.
Assim, considerando os aspectos exigidos e os benefícios a serem alcançados com esta abordagem, a fonte de dados escolhida para as exemplificações práticas envolve dados do e-commerce brasileiro disponibilizados pela companhia Olist e extraídos diretamente da plataforma Kaggle. Para o leitor que vê a ausência de fontes de dados eficientes como um principal ofensor na jornada de aprendizado, este conjunto pode ser um excelente benchmark não apenas para os assuntos que irão compor este artigo, mas também para as mais variadas explorações práticas envolvendo tratamento e análise de dados.
O e-commerce brasileiro em dados
Um dos fatores primordiais para o uso da fonte de dados Brazilian E-Commerce é, sem dúvidas, a presença de múltiplos conjuntos de dados que se relacionam entre si de modo a proporcionar uma série de cenários distintos de processamento e análise. Nesse sentido, seria possível unir, por exemplo, dados de vendas, de clientes e de produtos para analisar situações específicas sobre os produtos mais vendidos no comércio online para cada empresa parceira cadastrada. De modo a proporcionar uma visão holística das possibilidades, a tabela abaixo consolida os arquivos e fontes disponíveis no contexto analítico de vendas online no Brasil.
| Conjunto de dados | Descrição |
| orders | Dados contendo pedidos online realizados por clientes |
| order_items | Informações sobre cada item existente em cada pedido online realizado pelos clientes |
| order_reviews | Comentários, críticas e notas fornecidas pelos clientes para os produtos adquiridos online |
| products | Informações detalhadas sobre cada produto presente nos pedidos realizados |
| customers | Informações sobre os clientes compradores online |
| payments | Dados sobre os pagamentos realizados para os pedidos online solicitados |
| sellers | Informações sobre os vendedores/parceiros das vendas online |
| geolocation | Dados de geolocalização para os CEPs fornecidos pelos clientes ao realizarem seus respectivos pedidos |
Ainda visando ilustrar cenários de relacionamento entre os dados disponibilizados, o diagrama abaixo indica como as fontes estão organizadas de acordo com seus respectivos conteúdos e como estas se relacionam umas com as outras:
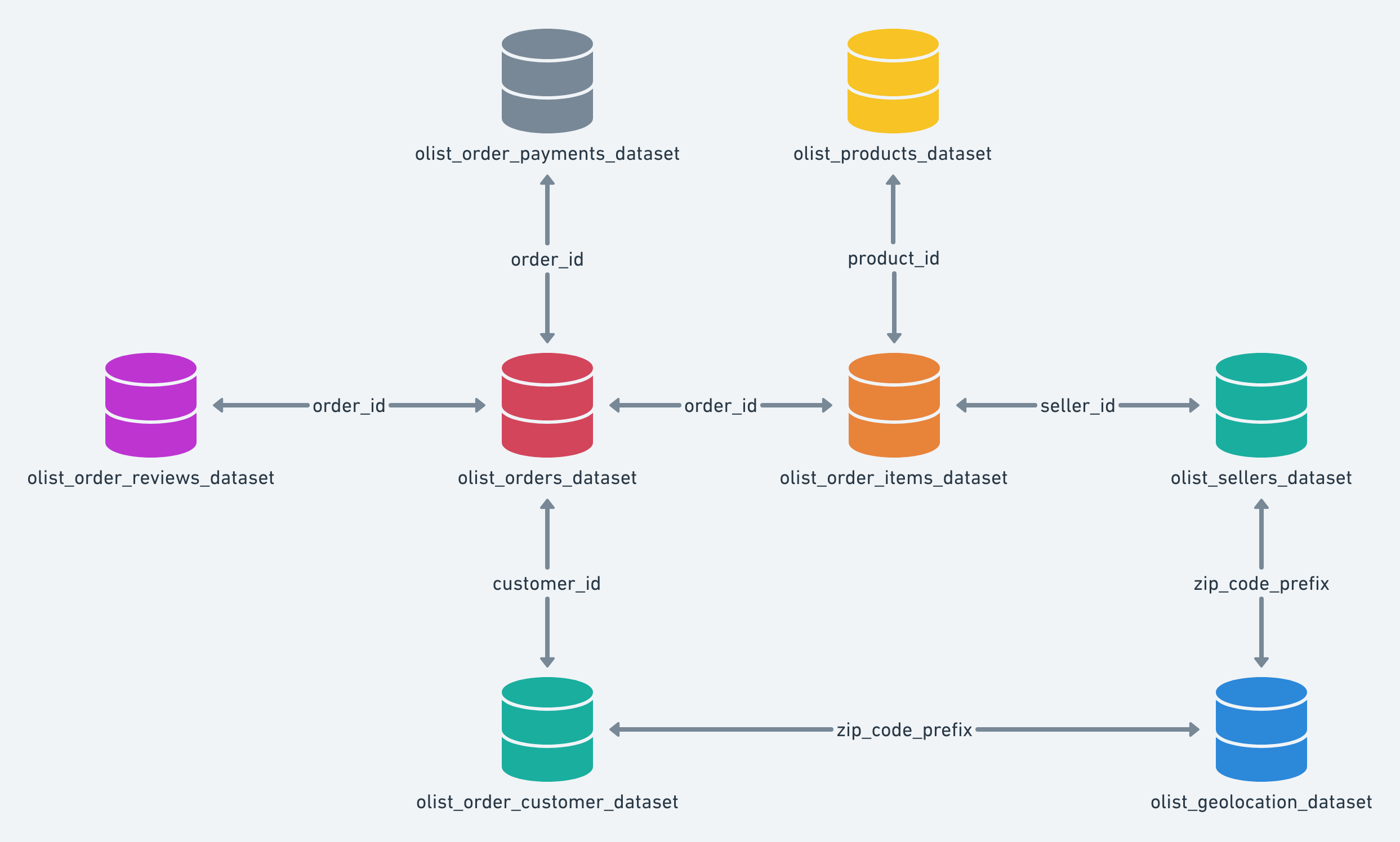
O uso dos dados neste artigo
Por fim, uma vez apresentado o contexto completo sobre os dados a serem utilizados nas explorações práticas deste artigo, é importante ressaltar o caráter didático e explanatório dos códigos a serem exemplificados. De fato, o objetivo deste processo é proporcionar ao leitor uma visão alternativa sobre todo o conteúdo abordado nos últimos 5 ou 6 artigos desta série. Eventualmente, no decorrer dos próximos artigos, será possível utilizar estas mesmas fontes de dados para construir aplicações mais complexas em cenários cada vez mais próximos do que pode ser definido como estado da arte em termos de utilização do Spark.
Dito isso, é possível iniciar os procedimentos práticos de construção do aprendizado a partir de um passo primordial: a preparação do ambiente.
Preparando o ambiente
Trazendo à tona uma simplória parcela teórica ao artigo, todo o conteúdo aqui consolidado será desenvolvido a partir de uma instalação do Apache Spark em seu modo local de trabalho o que, em linhas gerais, indica que os processos driver e executores atuam em uma única máquina. Dessa forma, a aplicação Spark é construída através do uso das APIs estruturadas (DataFrames e SparkSQL) utilizando a linguagem Python (pyspark) em um Jupyter Notebook instanciado em uma máquina virtual Linux.
Para o fornecimento e estruturação do caminho de usabilidade do Spark presente entre os usuários e a aplicação, faz-se necessária a presença de um objeto de sessão representado pela classe SparkSession. Somente assim os métodos de leitura, transformação e escrita dos dados podem ser executados via APIs estruturadas. Explanações teóricas sobre o objeto de sessão do Spark já foram fornecidas previamente em outras oportunidades desta série e uma lista de artigos relevantes pode ser encontrada logo abaixo:
SparkSession
Para a criação de um objeto de sessão do Spark utilizando pyspark, o código abaixo pode ser aplicado no ambiente de trabalho definido:
# Importando bibliotecas
from pyspark.sql import SparkSession
import os
# Construindo objeto de sessão
spark = SparkSession\
.builder\
.appName("transformacoes-pyspark")\
.getOrCreate()
Assim, nasce a variável spark contendo basicamente o objeto de sessão responsável por ser a porta de entrada para métodos das APIs estruturadas do Spark. A partir de então, é possível aplicar os processos de leitura das fontes de dados definidas para o projeto.
Lendo DataFrames
Sob a ótica do Spark, a leitura de fontes externas de dados é feita através da classe DataFrameReader com a possibilidade de aplicação das mais variadas configurações. Considerando o cenário de uso proposto, todos os conjuntos de dados do e-commerce brasileiro estão presentes em arquivos físicos no formato csv e, dessa forma, os processos de leitura para todos podem ser exemplificados pelo bloco de código abaixo:
# Realizando leitura dos dados: orders
df_orders = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(os.path.join(data_path, "orders/"))
# Realizando leitura dos dados: order items
df_order_items = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(os.path.join(data_path, "order_items/"))
# Realizando leitura dos dados: order payments
df_order_payments = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(os.path.join(data_path, "order_payments/"))
# Realizando leitura dos dados: order reviews
df_order_reviews = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(os.path.join(data_path, "order_reviews/"))
# Realizando leitura dos dados: products
df_products = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(os.path.join(data_path, "products/"))
# Realizando leitura dos dados: customers
df_customers = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(os.path.join(data_path, "customers/"))
# Realizando leitura dos dados: geolocation
df_geolocation = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(os.path.join(data_path, "geolocation/"))
# Realizando leitura dos dados: sellers
df_sellers = spark.read.format("csv")\
.option("inferSchema", "true")\
.option("header", "true")\
.load(os.path.join(data_path, "sellers/"))
Neste momento, é importante citar que a utilização da classe DataFrameReader para leitura de fontes externas no Spark implica no retorno de objetos do tipo DataFrame, aos quais trazem consigo todo o arcabolso de métodos de transformação contidos na linguagem. O processo de leitura acima exemplificado considera a configuração de opções específicas de inferência de schema e utilização da primeira linha dos conjuntos como header. De maneira alternativa, um schema explícito de dados poderia ser definido a partir da utilização dos tipos primitivos nativos do Spark em um cenário onde a presença de um layout padronizado de tabela se faz mandatória.
# Importando tipos primitivos
from pyspark.sql.types import StructType, StructField, \
StringType, IntegerType
# Definindo schema
customers_schema = StructType([
StructField("customer_id", StringType(), nullable=True, metadata={"description": "Id do cliente"}),
StructField("customer_unique_id", StringType(), nullable=True, metadata={"description": "Id único do cliente"}),
StructField("customer_zip_code_prefix", IntegerType(), nullable=True, metadata={"description": "Prefixo do CEP do cliente"}),
StructField("customer_city", StringType(), nullable=True, metadata={"description": "Cidade do cliente"}),
StructField("customer_state", StringType(), nullable=True, metadata={"description": "Estado do cliente"})
])
# Realizando a leitura dos dados
df_customers = spark.read.format("csv")\
.option("header", "true")\
.schema(customers_schema)\
.load(os.path.join(data_path, "customers/"))
# Verificando amostra dos dados
df_customers.printSchema()
df_customers.show(5)
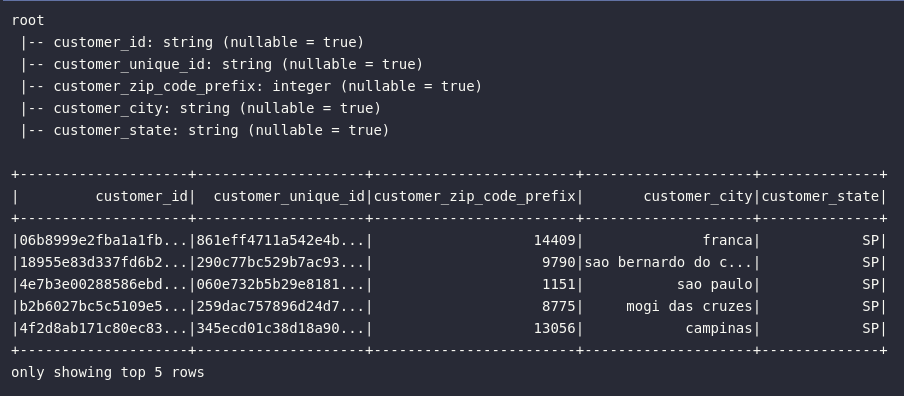
E assim, cada uma das fontes externas que contemplam o conjunto de dados do e-commerce brasileiro foram lidas e estão presentes, em memória, no ambiente de trabalho do Spark sob elementos do tipo DataFrame. A partir deste ponto, cenários específicos de transformação de dados serão apresentados e exemplificados para uma consolidação definitiva do conhecimento enriquecido neste âmbito. Ao leitor, é importante pontuar que os tópicos e subtópicos sequenciais irão abranger os grandes pilares de transformação já detalhados em outros posts desta série, retornando, desta vez, em um contexto muito mais prático e objetivo.
Criando consultas
De maneira primordial, aplicar consultas em Spark proporciona ao usuário uma gigantesca gama de possibilidades analíticas. Afinal, uma série transformações implícitas podem ser computadas no formato de expressões através dos métodos característicos de consulta de dados aplicados aos DataFrames. Para isto, é preciso compreender os elementos responsáveis por referenciar colunas em uma coleção distribuída de dados para que, dessa forma, novos conjuntos possam ser criados a partir dos métodos de seleção.
col()
A função col() permite retornar um objeto do tipo Column com base em um atributo de um DataFrame. Com isso, pode-se aplicar transformações, outras funções ou então operações aritiméticas envolvendo a referência de coluna estabelecida:
# Importando função
from pyspark.sql.functions import col
# Referenciando colunas e criando expressões
col("anomes") * 100 + 1
col("valor_A") > col("valor_B")
# Aplicando funções à referências de colunas
from pyspark.sql.functions import lpad, lower, split
lpad(col("moeda"), 2, "")
lower(col("sigla"))
split("nome_completo", " ")
expr()
Já a função expr() possui os mesmos objetivos gerais da função col(), porém com algumas particularidades que se mostram altamente interessantes em alguns cenários práticos de uso. Sua principal característica está associada à possibilidade de criar expressões de referência de colunas através de strings. Por mais simples que isto possa parecer, este comportamento proporciona aos usuários cenários de implementação de transformações, aplicação de funções e criação de operações aritméticas e lógicas em um formato próximo à própria linguagem SQL:
# Importando função
from pyspark.sql.functions import expr
# Criando expressões em formato de string
expr("(anomes * 100) + 1")
expr("valor_A > valor_B")
expr("lpad(moeda, 2, '')")
expr("lower(sigla)")
expr("split(nome_completo, '')")
No exemplo acima, as mesmas funções de transformação apresentadas no uso da função col() foram aplicadas como strings em expressões sem a necessidade explítica de importação. Isto foi possível pois, internamente, o Spark converte as expressões em um formato legível de acordo com algumas premissas de interpretação do código.
select()
Assim, conhecendo as formas de referenciar colunas através das funções col() e expr(), a criação de consultas em um DataFrame pode finalmente ser aplicada através do método select().
# Importando funções
from pyspark.sql.functions import upper, datediff
# Verificando detalhes sobre o pedido
df_orders_prep = df_orders.select(
expr("order_id AS id_pedido"),
expr("to_date(order_purchase_timestamp) AS dt_compra"),
expr("to_date(order_approved_at) AS dt_aprovacao"),
expr("to_date(order_delivered_customer_date) AS dt_entrega"),
upper(col("order_status")).alias("status_pedido"),
datediff(col("order_delivered_customer_date"), col("order_purchase_timestamp")).alias("dias_para_entrega"),
)
# Visualizando dados
df_orders_prep.show(5)
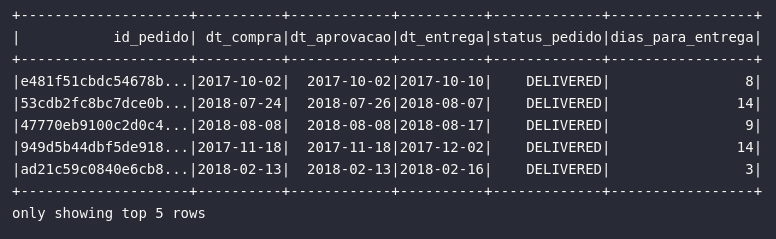
Um ponto interessante a ser comentado diz respeito à mescla entre as expressões que compõem uma consulta via select() no Spark: neste cenário, pode-se tranquilamente utilizar tanto col() quanto expr() para referenciar colunas e construir expressões de transformação. Invariavelmente, referências e expressões explicitamente escritas via expr() trazem uma certa facilidade pela menor quantidade de funções a serem importadas ou mesmo escritas, tornando assim seu uso conjunto com o método de select() uma espécie de padrão entre usuários Spark.
selectExpr()
Assim, como introduzido no último comentário do tópico anterior, métodos de consultas atrelados à expressões construídas com a função expr() se tornaram, ao longo do tempo, um padrão bastante comum de uso. Com isso, visando proporcionar uma maior facilidade à seus usuários, o Spark introduziu o método selectExpr() como uma possibilidade extremamente dinâmica de criar consultas com expressões embutidas via strings, sem a necessidade de criar expressões com a função expr().
# Verificando detalhes sobre o pedido
df_orders_prep = df_orders.selectExpr(
"order_id AS id_pedido",
"to_date(order_purchase_timestamp) AS dt_compra",
"to_date(order_approved_at) AS dt_aprovacao",
"to_date(order_delivered_customer_date) AS dt_entrega",
"upper(order_status) AS status_pedido",
"datediff(order_delivered_customer_date, order_purchase_timestamp) AS dias_para_entrega",
"case when upper(order_status) = 'DELIVERED' then 1 else 0 end as flag_entregue"
)
# Visualizando dados
df_orders_prep.show(5)
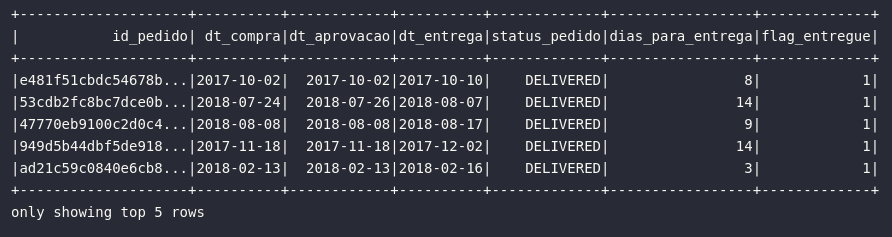
E assim, os processos de construção de consultas no Spark habilitam uma série de novas possibilidades em fluxos reais de trabalho. Com elas, verdadeiras expressões podem ser computadas de modo a alcançar um objetivo de transformação definido em um pipeline de dados. Na próxima seção, uma série de novos métodos serão apresentados em um cenário de aplicação de modificações em atributos de DataFrames.
Operando em colunas
Visando enriquecer ainda mais o conhecimento em Spark, algumas funções e métodos adicionais podem ser aplicados para a realização de operações em colunas de uma coleção distribuída de dados. O objetivo desta seção é apresentar estes elementos em cenários práticos de uso que podem ser combinados com os métodos de consulta demonstrados anteriormente.
withColumn()
O método withColumn() pode ser aplicado diretamente à DataFrames para realizar a adição de colunas e novos atributos a partir de expressões ou simplesmente referências de colunas.
from pyspark.sql.functions import split
# Adicionando colunas em um DataFrame
df_payments_prep = df_order_payments\
.withColumn("moeda", expr("'R$'"))\
.withColumn("vlr_pgto_moeda", expr("concat(moeda, cast(payment_value AS string))"))\
.withColumn("tipo_pagamento", split(col("payment_type"), "_")[0])
# Visualizando dados
df_payments_prep.show(5)
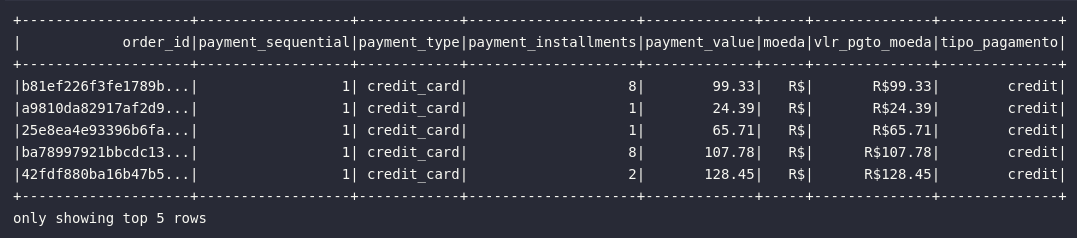
Como principal destaque, é possível pontuar a possibilidade de aplicação de múltiplas chamadas do método withColumn() para adição de diversas colunas em um mesmo bloco. Além disso, diferente das consultas, este método apenas adiciona colunas em um DataFrame já existente, mantendo intactos os atributos presentes.
withColumnRenamed()
Em uma outra possibilidade interessante de transformação, o método withColumnRenamed() pode ser utilizado para renomar atributos de um DataFrame.
# Tratando base de pagamentos através de métodos característicos
df_payments_prep = df_order_payments\
.withColumnRenamed("order_id", "id_pedido")\
.withColumnRenamed("payment_sequential", "parcela_pgto")\
.withColumnRenamed("payment_type", "tipo_pgto")\
.withColumnRenamed("payment_installments", "qtd_parcelas")\
.withColumnRenamed("payment_value", "vlr_pgto")\
.withColumn("moeda", expr("'R$'"))
# Visualizando resultado
df_payments_prep.show(5)
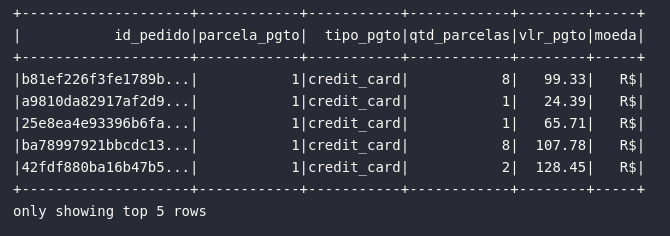
Neste momento, é notório perceber uma certa complexidade adicional em utilizar múltiplas chamadas de withColumnRenamed() e withColumn() para renomear ou adicionar colunas em um DataFrame quando, na verdade, um processo análogo e com um menor overhead poderia ser programado utilizando consultas. Na prática, o Spark sempre possibilidade diferentes cenários para operações semelhantes, deixando à cargo do usuário escolher o caminho de preferência em busca dos objetivos estabelecidos.
alias()
Seguindo adiante com os métodos e funções em um cenário de transformação de atributos de um DataFrame em Spark, o método alias() pode ser diretamente aplicado em referências de colunas via função col() para alterar sua nomenclatura. Na prática, trata-se a uma alternativa às formas exemplificadas via withColumnRenamed() ou mesmo via expressões (expr("col AS new_name")):
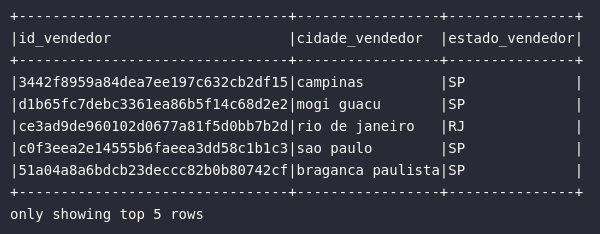
# Criando consulta e adicionando alias
df_sellers_prep = df_sellers.select(
col("seller_id").alias("id_vendedor"),
col("seller_city").alias("cidade_vendedor"),
col("seller_state").alias("estado_vendedor")
)
# Visualizando dados
df_sellers_prep.show(5, truncate=False)
drop()
Eventualmente, ao invés de selecionar um conjunto de atributos de um DataFrame para construir uma nova coleção distribuída de dados em meio a um fluxo de processamento, os usuários podem se deparar com situações onde é mais direto e objetivo eliminar um ou mais atributos, mantendo assim os demais dentro da estratégia de transformação dos dados. Para cenários assim, o método drop() pode ser aplicado diretamente à DataFrames da seguinte forma:
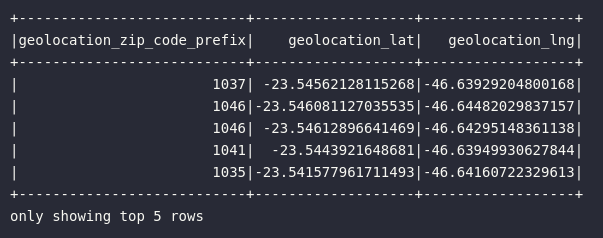
# DataFrame original de geolocalização
df_geolocation.show(5)
# Eliminando colunas de cidade
df_geo_dropped = df_geolocation.drop("geolocation_state")
df_geo_dropped.show(5)
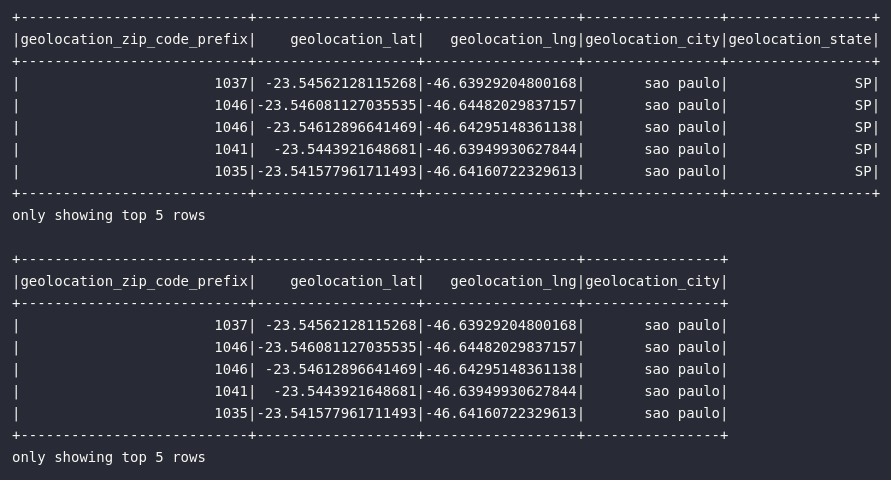
Em complemento ao exemplo demonstrado acima, é válido citar que o método drop() aceita mais de uma referência de coluna como argumento, fomentando assim a eliminação de múltiplas colunas em um só comando:
# Eliminando múltiplas colunas
df_geolocation.drop("geolocation_city", "geolocation_state").show(5)
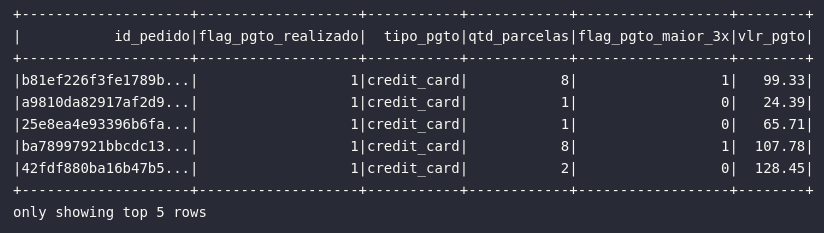
lit()
Em alguns casos específicos, o usuário Spark pode manifestar o desejo de inserir um valor literal em uma consulta de dados para criar um novo DataFrame capaz de utilizar este novo atributo para análises específicas. Para tal, a função lit() se faz presente e seus principais casos de uso englobam a fixação de valores específicos e criação de flags (1 ou 0).
# Importando função
from pyspark.sql.functions import lit, when
# Analisando pagamentos online
df_pgtos = df_order_payments.select(
col("order_id").alias("id_pedido"),
lit(1).alias("flag_pgto_realizado"),
col("payment_type").alias("tipo_pgto"),
col("payment_installments").alias("qtd_parcelas"),
when(col("payment_installments") >= 3, lit(1)).otherwise(lit(0)).alias("flag_pgto_maior_3x"),
col("payment_value").alias("vlr_pgto")
)
# Visualizando dados
df_pgtos.show(5)
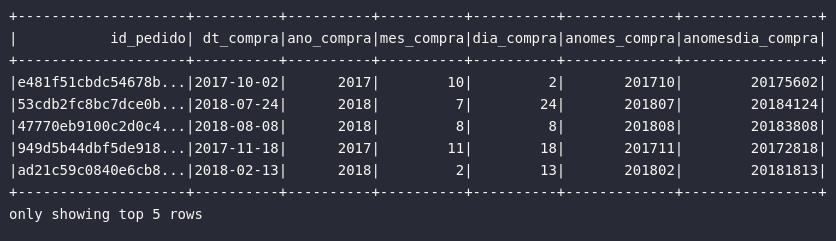
cast()
Um dos processos mais comuns envolvendo consultas de dados está relacionado à alterações nos tipos primitivos dos atributos de uma base. Conhecido como casting, este tipo de operação pode ser utilizada, por exemplo, para converter atributos de um determinado tipo primitivo para outro mais adequado dentro das propostas e objetivos do fluxo. Sob a ótica do Spark, este processo pode ser aplicado tanto com a função cast(), como também através de expressões (expr("cast(col AS <type>) AS new_col)").
# Importando função e tipos primitivos
from pyspark.sql.functions import cast, year, month, dayofmonth
from pyspark.sql.types import DateType, IntegerType
# Referenciando expressões de transformação
ano_compra = year(col("order_purchase_timestamp").cast(DateType()))
mes_compra = month(col("order_purchase_timestamp").cast(DateType()))
dia_compra = dayofmonth(col("order_purchase_timestamp").cast(DateType()))
# Transformando datas de base de pedidos
df_orders_prep = df_orders.select(
col("order_id").alias("id_pedido"),
col("order_purchase_timestamp").cast(DateType()).alias("dt_compra"),
ano_compra.alias("ano_compra"),
mes_compra.alias("mes_compra"),
dia_compra.alias("dia_compra"),
((ano_compra * 100) + mes_compra).cast(IntegerType()).alias("anomes_compra"),
expr("cast(date_format(order_purchase_timestamp, 'yyyymmdd') AS INT) AS anomesdia_compra")
)
# Visualizando dados
df_orders_prep.show(5)
E assim, esta primeira seção relacionada à operações Spark aplicadas em atributos de dados chega ao fim. No próximo bloco, uma
Operando em registros
Após uma jornada enriquecedora nos pilares de criação de consultas e operação em colunas de DataFrames no Spark, uma maior ênfase nos métodos aplicados diretamente em registros de uma coleção distribuída será fornecida para complementar ainda mais o know how na ferramenta. Neste contexto, serão abordados métodos de filtragem, ordenação e agregação de dados em suas mais variadas nuances e particularidades práticas.
where() e filter()
Filtrar dados em um pipeline de transformação é, de fato, uma operação extremamente comum. Para tal, de maneira objetiva, o Spark proporciona os métodos where() e filter() com funções literalmente análogas em todos os aspectos.
Oficialmente, a própria documentação do pyspark indica que o método where() é basicamente um alias para o método filter(). Em linhas gerais, na visão do usuário, é provavelmente mais comum aplicar processos de filtragem através do termo "WHERE", simulando até mesmo o formato SQL de criação de consultas. Dessa forma, por mais que where() e filter() sejam idênticos, há uma certa preferência pelo primeiro caso por uma questão generalista.
De toda forma, ambos os métodos de filtragem são aplicados à DataFrames e estão intimamente associados à operações lógicas, permitindo assim a criação implícita de booleanos que são avaliados e utilizados como regra principal para seleção de registros:
# Filtrando clientes de uma cidade em específico
city_filter = col("customer_city") == "campinas"
# Criando consulta
df_customers_campinas = df_customers.selectExpr(
"customer_id AS id_cliente",
"customer_city AS cidade_cliente",
"customer_state AS estado_cliente"
).where(city_filter)
#.where(expr("customer_city = 'campinas'"))
# Visualizando resultado
df_customers_campinas.show(5, truncate=False)
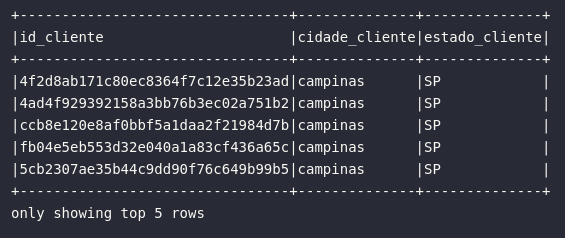
No código acima, é possível notar que o operador lógico de igualdade foi definido previamente e armazenado em uma variável denominada city_filter que, por sua vez, continua a regra associada ao filtro de cidade. Em Spark, isto é tranquilamente possível e pode até ser considerada uma prática interessante de organização de código quando os filtros ou as expressões são grandes demais para serem colocadas em uma consulta de maneira legível. Para proporcionar uma visão alternativa ao usuário, a linha comentada tem a mesma função do filtro da variável, porém utiliza uma expressão criada de maneira explícita dentro do método de filtragem.
sort() e orderBy()
No meio analítico, a ordenação de conjuntos de dados facilita a retirada de insights em contextos específicos. Com esta operação, é possível analisar, por exemplo, os principais elementos de acordo com um determinado valor numérico. Em Spark, este procedimento pode ser aplicado pelos métodos sort() e orderBy, ambos retornando o mesmo resultado ao usuário.
Os métodos de ordenação possuem uma facilidade adicional envolvendo o parâmetro ascending presente em suas respectivas chamadas, permitindo definir se a ordenação será ascendente ou descendente para a coluna. Em caso de ordenação por múltiplos atributos, os argumentos devem ser passados como uma lista e, caso a ascendência da ordenação seja diferente entre os atributos, as listas de colunas e de ascendência devem possuir a mesma quantidade de elementos.
Adicionalmente, é possível utilizar as funções desc() e asc() para definir a ascendência da ordenação.
# Retornando itens mais caros
df_expensive_items = df_order_items.selectExpr(
"product_id AS id_produto",
"price AS vlr_produto",
"freight_value AS vlr_frete"
).sort(["price", "freight_value"], ascending=[False, True])
# Visualizando dados
df_expensive_items.show(5)
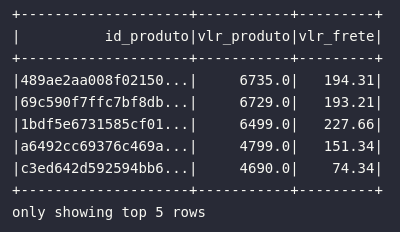
Por padrão, as ordenações possuem ordem ascendente, sendo desnecessário fornecer o argumento ascending caso este seja o comportamento desejado para todos os atributos referenciados.
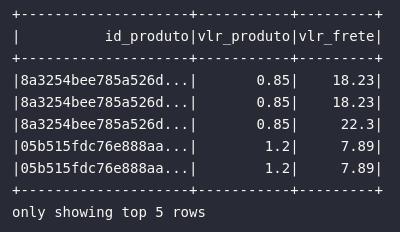
# Retornando itens mais baratos
df_cheap_items = df_order_items.selectExpr(
"product_id AS id_produto",
"price AS vlr_produto",
"freight_value AS vlr_frete"
).orderBy("vlr_produto")
# Visualizando dados
df_cheap_items.show(5)
groupBy() e agg()
Alcançando agora um marco importante nos processos de transformação, os métodos de agrupamento de dados se fazem presentes como uma via fundamental para análises específicas em conjuntos de dados. No leque de possibilidades disponibilizado pelo Spark, uma série de funções de agregação podem ser importadas diretamente do módulo pyspark.sql.functions para a aplicação dos mais diferentes formatos de consolidação de dados. Unindo isso aos métodos groupBy e agg, tem-se em mãos uma rota simples e dinâmica para a codificação das mais variadas transformações de agrupamento.
Antes de demonstrar alguns exemplos práticos, é importante citar que o método groupBy(), aplicado à DataFrames em Spark, resulta em um objetivo do tipo RelationalGroupedDataset que, por sua vez, pode ser alvo de aplicação das mais variadas funções de agregação de acordo com os propósitos estabelecidos. Desse modo, o método agg() se faz presente como uma forma de consolidar a aplicação de tais funções para os atributos numéricos do conjunto de dados.
Em linhas gerais, o groupBy() recebe a(s) coluna(s) categórica(s) de agrupamento e, o método agg() aplica as funções de agregação nos atributos numéricos selecionados.
# Importando funções
from pyspark.sql.functions import count, avg, max, min, round
# Retornando os produtos mais caros vendidos
df_items_prep = df_order_items.groupBy("product_id").agg(
count("*").alias("qtd_vendas"),
round(avg("price"), 2).alias("avg_price"),
expr("max(price) AS max_price"),
min("price").alias("min_price"),
expr("round(max(price) - min(price), 2) AS dif_max_min_price")
).orderBy("qtd_vendas", ascending=False)
# Visualizando dados
df_items_prep.show(5, truncate=False)
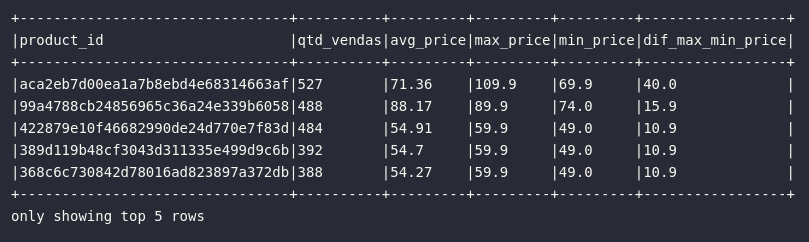
No bloco de código acima, é possível visualizar como a dinâmica de expressões pode ser mesclada com as referências de colunas em meio a aplicação de funções de agregação. O usuário pode tranquilamente escolher entre importar as funções diretamente do módulo pyspark.sql.functions e aplicar utilizando referências explícitas de colunas via col(); ou então aplicar uma expressão diretamente via expr() de uma forma interpretável pelo Spark para alcançar os mesmos resultados.
De forma alternativa, para agrupamentos pontuais utilizando uma única função de agregação, o objeto resultante do método groupBy() pode ser utilizado como alvo direto de aplicação de métodos estatísticos, como no exemplo abaixo:
# Média de pagamentos por tipo
df_payment_types = df_order_payments.groupBy("payment_type").avg("payment_value")
# Visualizando dados
df_payment_types.show()
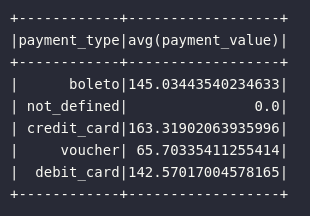
Entretanto, em situações onde seja necessário aplicar diferentes funções de agregação em diferentes atributos de um conjunto distribuído, o combo groupBy() e agg() se faz mais eficiente:
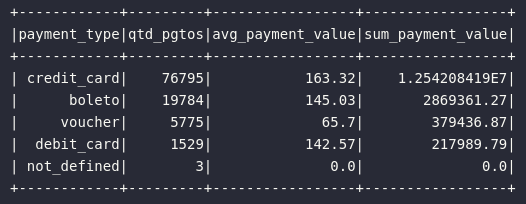
# Média de pagamentos por tipo
df_payment_types = df_order_payments\
.groupBy("payment_type").agg(
expr("count(1) AS qtd_pgtos"),
expr("round(avg(payment_value), 2) AS avg_payment_value"),
expr("round(sum(payment_value), 2) AS sum_payment_value")
).sort("qtd_pgtos", ascending=False)
# Visualizando dados
df_payment_types.show()
Juntando dados
Por fim, após selecionar, modificar atributos e operar em registros, é chegado o momento de abordar situações que englobam dois ou mais conjuntos distribuídos de dados. Afinal, em um pipeline produtivo, invariavelmente o usuário estará tratando com diversas bases de dados de modo a alcançar um objetivo comum. Neste cenário, serão apresentados os métodos considerados pelo Spark para unir dados tanto na vertical quanto na horizontal.
union()
Em alguns fluxos de trabalho, podem existir necessidades de empilhar diferentes DataFrames na vertical, seja para completar um público de análise ou mesmo para construir uma base única capaz de ser trabalhada posteriormente. Para isso, o método union() pode ser aplicado em um DataFrame original considerando a referência à um segundo DataFrame alvo do processo. No bloco de código abaixo, o método where() será utilizado de maneira auxiliar para gerar um conjunto de dados alternativo para a posterior união.
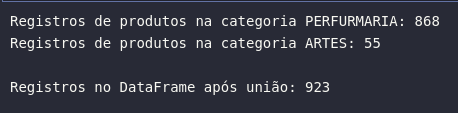
# Gerando DataFrames específicos para posterior união
df_perfurmaria = df_products.where(expr("product_category_name = 'perfumaria'"))
df_artes = df_products.where(expr("product_category_name = 'artes'"))
# Contabilizando registros
print(f'Registros de produtos na categoria PERFURMARIA: {df_perfurmaria.count()}')
print(f'Registros de produtos na categoria ARTES: {df_artes.count()}')
# Unindo DataFrames
df_perfurmaria_artes = df_perfurmaria.union(df_artes)
print(f'\nRegistros no DataFrame após união: {df_perfurmaria_artes.count()}')
Na prática, este processo pode ser considerado análogo a aplicação de um UNION ALL na linguagem SQL que, por sua vez, une dois record sets sem retirar dados duplicados. Para aplicar a deduplicação no Spark, é possível combinar a execução do método distinct() após a união.
Adicionalmente, é importante citar que, assim como no padrão SQL, o método union() resolve as colunas por posição e não por nome. Ao tentar unir DataFrames que possuem um número diferente de colunas, um erro será retornado:
# Unindo DataFrames diferentes
df_orders.union(df_order_payments)
[...]
AnalysisException: Union can only be performed on tables with the same number of columns, but the first table has 8 columns and the second table has 5 columns;
'Union false, false
join()
E assim, alcançando o último assunto deste completo resumo consolidado sobre transformações em Spark, é chegado o momento de abordar os joins como formas eficientes de cruzar dois DataFrames com o objetivo de formar um conjunto único dentro das necessidades e regras exigidas.
Diferente dos processos de união de dois conjuntos com o método union(), onde os conjuntos alvo são unidos na vertical, o método join() proporciona um cruzamento horizontal dos atributos de ambos os DataFrames através de uma forma característica e uma operação lógica. Entre as opções de joins disponíveis, é possível listar:
| Opção de Join (Spark) | Atuação |
inner | Mantém registros com a chave existente em ambos os conjuntos da esquerda e da direita |
left ou left_outer | Mantém registros com a chave existente apenas no conjunto da esquerda |
right ou right_outer | Mantém registros com a chave existente apenas no conjunto da direita |
left_semi | Mantém registros onde a chave existe em ambos os conjuntos da esquerda e da direita, porém preserva apenas as colunas do conjunto da esquerda |
left_anti | Realiza o direto oposto do left_semi, mantendo registros apenas onde a chave não existe nos conjuntos da esquerda e da direita |
outer ou full ou full_outer | Mantém todos os registros de ambos os conjuntos da esquerda e da direita |
Na prática, é provável que processos de left join sejam os mais comuns, visto que corroboram para cenários de enriquecimento de atributos em uma base já consolidada (esquerda). O inner join também é uma outra opção bastante frequente em fluxos de trabalho, dada sua característica em trazer apenas registros onde a validação da operação lógica é verdadeira para ambos os conjuntos. Os demais tipos de joins podem aparecer em situações bem específicas em um fluxo de trabalho.
Para aplicar o cruzamento de dados no Spark, o método join() se faz presente com basicamente três grandes argumentos necessários:
other=para especificação do segundo DataFrame alvo do processoon=para especificação da chave de cruzamento no formato de uma ou mais operações lógicashow=para especificação do tipo de join utilizado (left, inner, etc...)
Em exemplos anteriores fornecidos neste artigo, foram realizados processos de agregação e agrupamento para analisar diversas estatísticas sobre os preços dos produtos, sendo estes baseados na coluna product_id do DataFrame df_order_items. E se fosse preciso aplicar esta mesma análise com base na categoria do produto? Afinal, para usuários que não possuem uma noção clara sobre a referência de cada id para cada nome de produto, esta seria uma tarefa impossível de se resolvida apenas com o DataFrame df_order_items. Dessa forma, se faz necessária a realização de um processo de agrupamento com base no atributo product_category_name presente apenas no DataFrame df_products. A junção deste dois conjuntos e o subsequente agrupamento são exemplificados pelo código abaixo:
# Analisando média de preços de produtos
df_product_category = df_order_items.join(
other=df_products,
on=[df_order_items.product_id == df_products.product_id],
how="left"
).groupBy("product_category_name").agg(
expr("count(1) AS qty_cat_sales"),
expr("round(sum(price), 2) AS sum_cat_sales"),
expr("round(avg(price), 2) AS avg_cat_price"),
expr("max(price) AS max_cat_price"),
expr("min(price) AS min_cat_price")
).orderBy("qty_cat_sales", ascending=False)
# Visualizando dados
df_product_category.show(10, truncate=False)
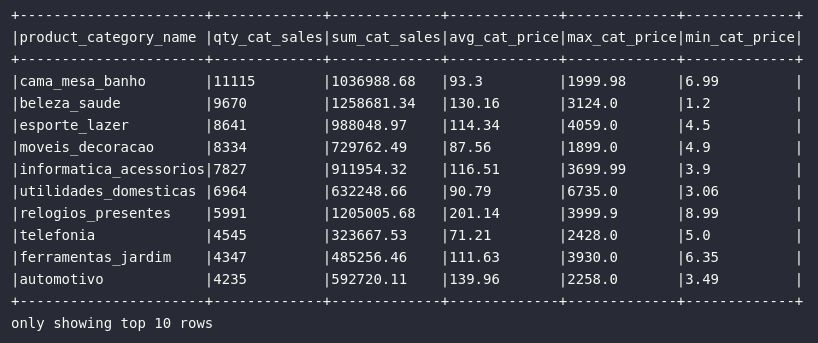
Com a junção proposta, novos insights podem ser retirados do pipeline de dados, incluindo informações específicas sobre a categoria preferida pelos compradores online em termos de quantidade de vendas registradas. Em um outro exemplo, é possível aplicar múltiplas operações de joins para a construção de conjuntos de dados desnormalizados partindo de bases altamente normalizadas, seguindo assim um fluxo analítico relativamente comum em termos de geração e armazenamento de dados em Data Lakes:
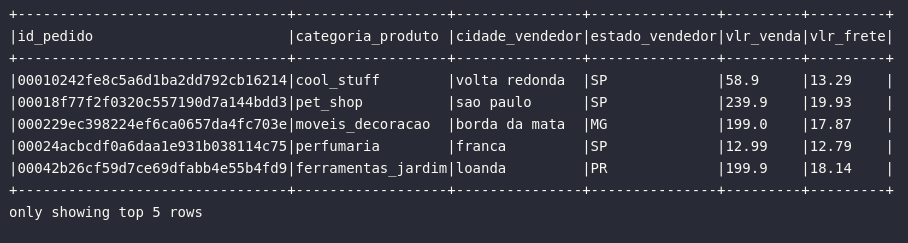
# Cruzando dados de múltiplos conjuntos
df_sales = df_order_items.join(
other=df_products,
on=[df_order_items.product_id == df_products.product_id],
how='left'
).join(
other=df_sellers,
on=[df_order_items.seller_id == df_sellers.seller_id],
how='left'
).selectExpr(
"order_id AS id_pedido",
"product_category_name AS categoria_produto",
"seller_city AS cidade_vendedor",
"seller_state AS estado_vendedor",
"price AS vlr_venda",
"freight_value AS vlr_frete"
)
# Visualizando resultado
df_sales.show(5, truncate=False)
SparkSQL
Por mim, mas não menos importante, a seção derradeira deste abrangente artigo visa abordar o SparkSQL como uma forma alternativa (e não menos eficiente) para a transformação de dados em um fluxo de trabalho. Sem a intenção de explorar detalhes técnicos, uma vez que isto já foi proporcionado em outro artigo desta série, o bloco de código abaixo visa fornecer uma demonstração básica sobre como seria possível aplicar as transformações abordadas anteriormente utilizando apenas a linguagem SQL:
# Criando tabelas temporárias
df_orders.createOrReplaceTempView("tbl_orders")
df_order_items.createOrReplaceTempView("tbl_order_items")
# Gerando visão história de vendas
df_ecommerce_hist = spark.sql("""
SELECT
anomes_pedido,
anomesdia_pedido,
count(DISTINCT id_pedido) AS qtd_pedidos,
count(id_item) AS qtd_produtos,
round(sum(vlr_item), 2) AS soma_vendas,
round(sum(vlr_frete), 2) AS soma_frete
FROM (
SELECT
o.order_id AS id_pedido,
i.product_id AS id_item,
i.price AS vlr_item,
i.freight_value AS vlr_frete,
date_format(o.order_purchase_timestamp, 'yyyyMM') AS anomes_pedido,
date_format(o.order_purchase_timestamp, 'yyyyMMdd') AS anomesdia_pedido
FROM tbl_orders AS o
LEFT JOIN tbl_order_items AS i
ON o.order_id = i.order_id
WHERE lower(o.order_status) = 'delivered'
)
GROUP BY
anomes_pedido,
anomesdia_pedido
ORDER BY anomesdia_pedido ASC
""")
# Visualizando conjunto
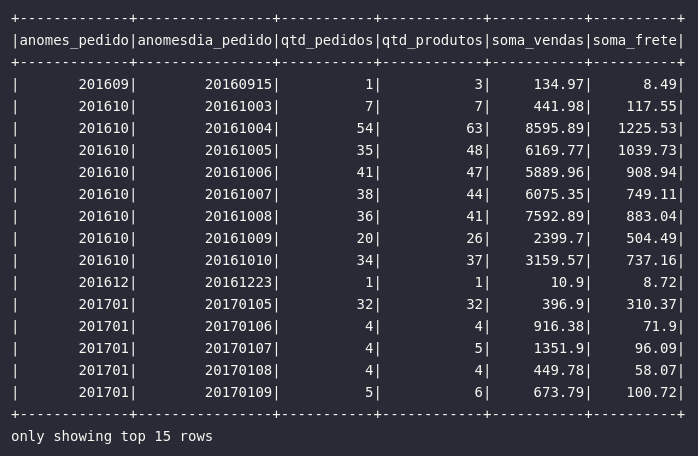
df_ecommerce_hist.show(15)
Conclusão e encerramento
Transformar dados com Spark é maravilhoso, não é mesmo? Considerando a vasta documentação existente e o grande número de exemplos disponíveis em diversas fontes de estudo, os desenvolvedores e entusiastas podem facilmente praticar, aprender e literalmente construir e aplicar fluxos de trabalho em Spark para a solução das mais variadas necessidades de dados, sejam estas atacadas através dos métodos característicos de DataFrames ou simplesmente com SQL via SparkSQL.
Referências
- pyspark.sql.functions.col
- pyspark.sql.functions.expr
- pyspark.sql.DataFrame.select
- pyspark.sql.DataFrame.withColumn
- pyspark.sql.DataFrame.withColumnRenamed
- pyspark.sql.Column.alias
- pyspark.sql.DataFrame.drop
- pyspark.sql.functions.lit
- pyspark.sql.Column.cast
- pyspark.sql.DataFrame.where
- pyspark.sql.DataFrame.filter
- pyspark.sql.DataFrame.sort
- pyspark.sql.DataFrame.orderBy
- pyspark.sql.DataFrame.groupBy
- pyspark.sql.DataFrame.agg
- pyspark.sql.DataFrame.union
- pyspark.sql.DataFrame.join
- pyspark.sql.SparkSession.sql




