

Criando Consultas no Spark: select() e selectExpr()

Olá, caro leitor! Seja muito bem vindo a mais um post desta série sobre o Apache Spark! Ao longo dos últimos artigos, construímos um vasto conhecimento em grande parte dos blocos fundamentais que formam a base do Spark no cenário de processamento distribuído de dados. Após compreender o que são DataFrames e como realizar os processos de leitura e escrita dos mesmos, navegamos por uma sequência fundamental de artigos abordando toda a dinâmica de transformação destes dados e a importância do SparkSQL como ferramenta universal para execução de queries SQL para transformação de dados sem perda alguma de performance.
Com tudo isso em mãos, estamos verdadeiramente prontos para mergulhar em uma nova etapa em nossa jornada de aprendizado: está dada a largada para um verdadeiro deep dive nos métodos de transformação das APIs estruturadas!
Embarque nessa nova temporada!
Um passo de cada vez: a proposta do artigo
Em muitas situações semelhantes dentro desta mesma série, assuntos inéditos foram introduzidos em etapas e com uma forte fundamentação teórica por trás. Neste caso, a abordagem não será diferente: para compreender e explorar os métodos de transformação de dados em DataFrames, é essencialmente fundamental entender a própria composição desta coleção distribuída de dados.
Assim, como um primeiro passo desta nova sequência de aprendizado, este artigo terá como objetivo apresentar os elementos de linhas, colunas e expressões que configuram toda a dinâmica de seleção de dados de um DataFrame. A partir desta exploração, será possível consolidar exemplos práticos de consultas criadas a partir de coleções distribuídas de dados.
Lendo dados para exploração
Assim, para navegar na proposta deste artigo, será preciso realizar a leitura de uma base de dados a ser utilizada na exploração dos conceitos. Conforme os conhecimentos adquiridos até o momento, o bloco de código abaixo será responsável por:
- Importar as bibliotecas necessárias e criar um objeto de sessão
spark - Definir variáveis para leitura local dos arquivos juntamente com um schema explícito
- Realizar a leitura de um arquivo CSV e armazenar o resultado em um DataFrame
- Validar o schema e mostrar alguns registros da base ao usuário
# Importando bibliotecas
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
import os
# Criando objeto de sessão
spark = (
SparkSession
.builder
.appName("art10-colunas-expressoes")
.getOrCreate()
)
# Definindo variáveis de diretório
home_path = os.path.expanduser('~')
data_path = os.path.join(home_path, 'dev/panini-tech-lab/data/flights-data/summary-data/csv/2015-summary.csv')
# Definindo schema para o arquivo CSV a ser lido
data_schema = StructType([
StructField("DEST_COUNTRY_NAME", StringType(), nullable=True, metadata={"description": "País de destino dos vôos contabilizados"}),
StructField("ORIGIN_COUNTRY_NAME", StringType(), nullable=True, metadata={"description": "País de origem dos vôos contabilizados"}),
StructField("count", IntegerType(), nullable=True, metadata={"description": "Contagem total de vôos entre os países de origem e de destino do registro"})
])
# Realizando a leitura dos dados
df = (
spark.read.format("csv")
.schema(data_schema)
.option("header", "true")
.load(data_path)
)
# Verificando amostra dos dados
df.printSchema()
df.show(5)
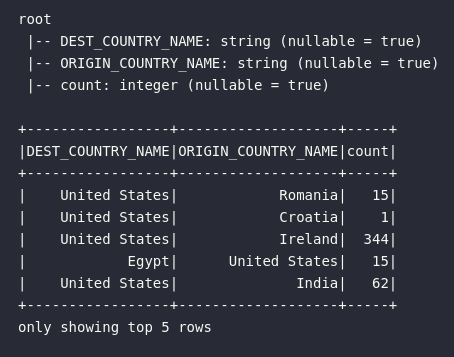
Com mais uma permissão para o uso da primeira pessoa nesta série, é simplesmente impossível não observar o código acima e sentir uma certa satisfação em chegar até este ponto e ter uma noção clara do que cada bloco faz. Se antes o Spark era uma verdadeira incógnita para nós, agora seus processos e seu funcionamento se tornam cada vez mais cristalinos. Simplesmente gratificante.
Os dados utilizados foram retirados do bureau dos Estados Unidos e contemplam registros de vôos realizados. Maiores detalhes sobre este conjunto já foram apresentados ao leitor em outros artigos desta série e estão disponíveis no link.
Por dentro de um DataFrame
Por mais que os DataFrames tenham sido explorados em artigos anteriores desta série e definidos como coleções distribuídas de dados em memória que representam planos de execução imutáveis com operações avaliadas de maneira lazily, sua composição em termos de linhas e colunas não foi observada em detalhes, até o momento. A importância deste ponto se dá em um cenário onde os métodos de transformação a serem explorados serão, de fato, aplicados em ambos os eixos horizontal e vertical da coleção estruturada, movimentando tanto registros como também atributos.
Em uma provocação simplória, como poderíamos selecionar uma linha específica de um DataFrame? E quanto a uma coluna? Seria este processo semelhante a estruturas análogas, como DataFrames do pandas em Python?
Registros de um DataFrame: o tipo Row
Assim, considerando a base de dados lida previamente e, sabendo que cada linha do conjunto representa a quantidade de vôos partindo de uma determinada origem até um determinado destino, o bloco de código abaixo utiliza a ação first do Spark para coletar, de forma direta, o primeiro registro do DataFrame alvo:
# Retornando a primeira linha do DataFrame
row = df.first()
Mas sobre o que se trata esta nova variável row? Qual seu conteúdo e seu tipo primitivo?
# Visualizando objeto
print(row)
print(type(row))

E assim, mesmo que de maneira simplista, é possível estabelecer que uma estrutura do tipo DataFrame no Spark é formada, no eixo horizontal, por uma série de elementos do tipo Row que, isoladamente, podem ser trabalhados, analisados e ter seus atributos chamados para os mais variados propósitos. Como um exemplo adicional, o código abaixo extrai os valores individuais de cada coluna do registro obtido:
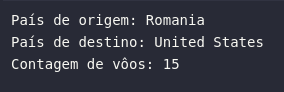
# Extraindo informações de um registro
print(f'País de origem: {row.ORIGIN_COUNTRY_NAME}')
print(f'País de destino: {row.DEST_COUNTRY_NAME}')
print(f'Contagem de vôos: {row[-1]}')
No primeiro bloco de código fornecido, a ação first() foi utilizada para extrair pontualmente o primeiro registro do DataFrame lido. Analogamente, a ação last() também poderia ser aplicada caso o objetivo fosse extrair a última linha da base de dados. Existem, ainda, outras ações capazes de coletar um maior número de elementos, como take(n) e collect() que podem ser utilizadas, respectivamente, para obter os n primeiros ou todos os registros de um DataFrame.
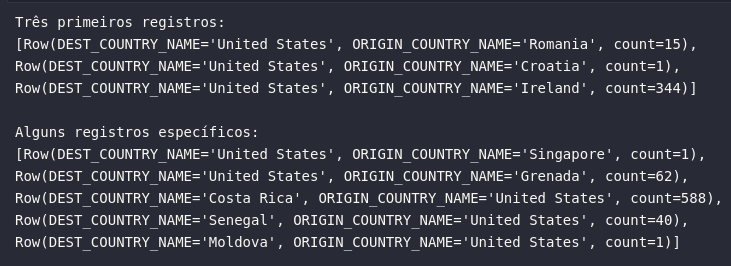
# Coletando as primeiras linhas de um DataFrame
n_rows = df.take(3)
print(f'Três primeiros registros: \n{n_rows}')
# Coletando todas as linhas de um DataFrame
all_rows = df.collect()
print(f'\nAlguns registros específicos: \n{all_rows[5:10]}')
Neste momento, é importante citar que todas as ações demonstradas são exemplos de operações utilizadas para coletar elementos de uma coleção distribuída de dados para uma análise em memória e que devem ser utilizadas com muita cautela. De acordo com um trecho presente no livro Spark: The Definitive Guide:
Qualquer coleta de dados ao driver pode ser uma operação extremamente custosa! Se você possui um conjunto volumoso de dados e executa a ação collect(), as chances de causar um "crash" no driver são altas.
Atributos de um DataFrame: o tipo Column
Uma vez explorados os elementos Row que compõem os registros de um DataFrame, é possível abordar os atributos desta coleção distribuída como componentes horizontais de uma base de dados.
Diferente da coleta de registros de um DataFrame para o driver local para análise em memória, a indexação de colunas em uma coleção distribuída pode ser feita de maneira estritamente semelhante à DataFrames do R ou do pandas:
# Visualizando colunas
print(f'Lista de colunas do DataFrame: {df.columns}')
# O que ocorre quando referenciamos colunas?
print(f'\nIndexando colunas: {df["DEST_COUNTRY_NAME"]}')
# Tipo primitivo
print(f'\nTipo primitivo da coluna: {type(df["DEST_COUNTRY_NAME"])}')

Neste cenário, o atributo columns de um DataFrame pode ser utilizado para retornar uma lista das colunas existentes. Ao aplicar a operação de indexação de um atributo em um DataFrame, é possível perceber que nenhum dado é retornado, mas sim apenas uma referência à coluna indexada como um objeto do tipo Column.
Para o Spark, as colunas são como construções lógicas que simplesmente representam um valor computado, registro a registro, através de uma expressão. Em outras palavras, para existir um valor real para uma coluna, é preciso existir um registro e, para existir um registro, é preciso enfim existir um DataFrame. Dessa forma, não é possível manipular uma coluna fora do contexto de um DataFrame, mas sim utilizando transformações em uma coleção distribuída de modo a modificar o conteúdo de um atributo no formato de uma expressão.
E assim, para que estas transformações em atributos possam ser aplicadas, é preciso conhecer as principais formas de referenciar uma coluna em um DataFrame de modo a permitir a construção de tais expressões.
col(), column() e expr()
Visando a construção de transformações aplicadas a atributos de uma coleção distribuída em Spark, as formas mais simples de referenciar uma coluna são representadas pelo uso das funções col(), column() e expr() presentes no módulo pyspark.sql.functions. A maneira mais rápida de entender seu uso é a partir de exemplos práticos:
# Importando funções de referenciamento de colunas
from pyspark.sql.functions import col, column, expr
# Construindo expressões via col
print(col("valor_A") + col("valor_B"))
# Construindo expressões via column
print(column("valor_A") + col("valor_B"))
# Construindo expressões via expr
print(expr("valor_A + valor_B"))
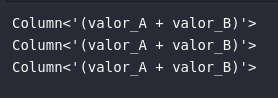
Sobre o bloco de código acima fornecido, é possível destacar:
- Todas as três funções utilizadas para referenciar colunas retornam o mesmo resultado
- Não há qualquer distinção no uso de
col()ecolumn()e, por facilidade, normalmente utiliza-se a funçãocol() - A função
expr()utiliza expressões completas de transformação em formato de string e permit construir operações em linguagem semelhante ao SQL
E assim, as operações demonstradas pelo bloco de código acima geram o mesmo resultado pois o Spark as compila em uma árvore lógica especificando a ordem das operações como uma grande expressão. Para visualizar esta propriedade, a expressão abaixo será utilizada para construção desta árvore lógica de operações:
# Criando expressão
(((col("SomeCol") + 5) * 200) - 6) < col("OtherCol")
# Modo alternativo
expr("(((some_col + 5) * 200) * 6) < other_col")
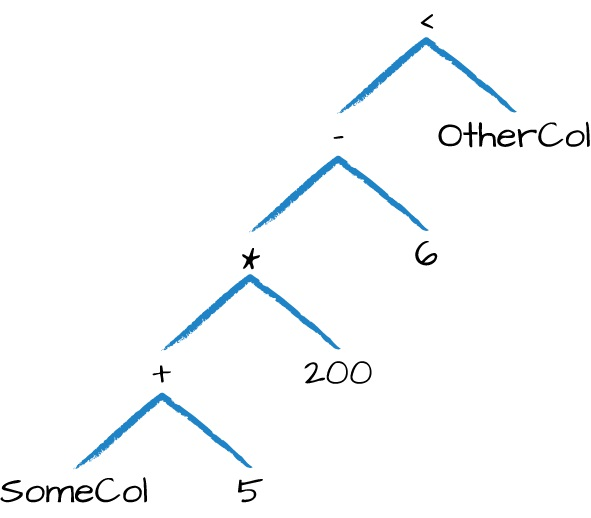
A árvore representada pela figura acima pode soar familiar, dado que trata-se de uma DAG (Directed Acyclic Graph). E aqui, mais uma vez é possível reforçar como a expressão construída via expr() representa algo estritamente similar a uma consulta criada na linguagem SQL. O fato de que ambas resultam na mesma árvore lógica corrobora ainda mais com um tema já explorado anteriormente nesta série envolvendo a compilação e o plano de execução de transformações no Spark.
Assim, ao compreender como expressões podem ser construídas e aplicadas para referenciar e aplicar operações em atributos de um DataFrame no Spark, é possível dar um passo adicional e abordar, de maneira completa, como estes elementos são utilizados na prática dentro de consultas em um conjunto estruturado de dados.
Construindo consultas
De maneira isolada, referenciar colunas ou construir expressões com base em atributos de um conjunto de dados não providenciam qualquer retorno ao usuário a não ser a própria expressão como uma lógica de transformação que pode posteriormente ser aplicada em um DataFrame. Isto significa que, para que as operações escritas possam ser, de fato, computadas, é preciso que exista uma ou mais formas de vinculá-las aos DataFrames.
Para proporcionar este vínculo, dois poderoso métodos de seleção de dados se fazem presentes neste momento: select() e selectExpr().
O método select()
Finalmente unindo alguns pontos neste artigo, o método select() permite a construção de verdadeiras consultas em uma coleção de dados distribuída através da referência de colunas:
# Selecionando coluna
df.select("DEST_COUNTRY_NAME").show(2)
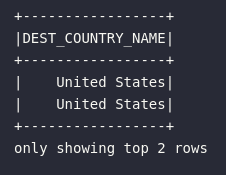
Considerando as diferentes formas de referenciar um atributo em um DataFrame, o bloco de código é ainda mais esclarecedor no sentido de abordar praticamente todas as maneiras distintas de selecionar e trazer dados de uma única coluna de uma coleção distribuída:
# Diferentes formas aplicar uma consulta
df.select(
"DEST_COUNTRY_NAME",
col("DEST_COUNTRY_NAME"),
column("DEST_COUNTRY_NAME"),
expr("DEST_COUNTRY_NAME")
).show(2)
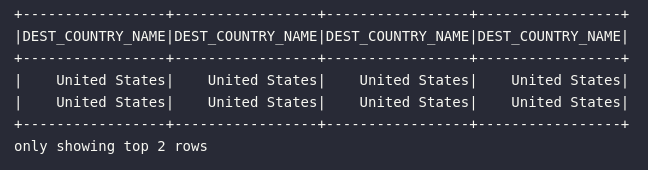
E assim, além de selecionar uma única coluna através das funções de referência, o método select() permite também a utilização de verdadeiras expressões computadas de acordo com a necessidade operacional do usuário:
# Exemplificando operações
df.select(
"count",
col("count") * 2,
expr("count * 2")
).show(2)
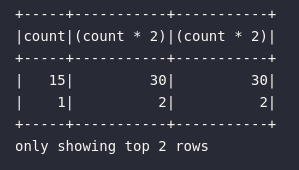
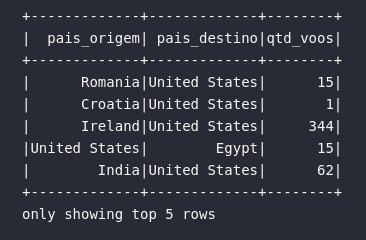
Além disso, é possível utilizar alguns métodos específicos do objeto Column para adicionar ainda mais elementos de transformação ao código. Um deles é o método alias() que permite fornecer um outro nome para uma coluna ou expressão calculada:
# Adicionando alias às expressões
df.select(
col("ORIGIN_COUNTRY_NAME").alias("pais_origem"),
col("DEST_COUNTRY_NAME").alias("pais_destino"),
col("count").alias("qtd_voos")
).show(5)
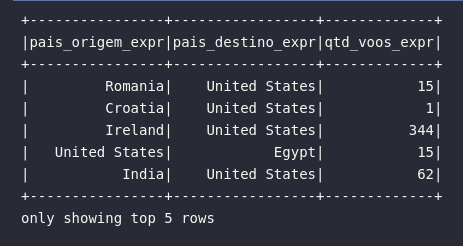
A mesma consulta acima também poderia ser construída única e exclusivamente através de expressões com expr(). O sufixo _expr foi adicionado apenas para diferenciar o resultado obtido previamente:
# Criando consulta com nomes modificados
df.select(
expr("ORIGIN_COUNTRY_NAME AS pais_origem_expr"),
expr("DEST_COUNTRY_NAME AS pais_destino_expr"),
expr("count AS qtd_voos_expr")
).show(5)
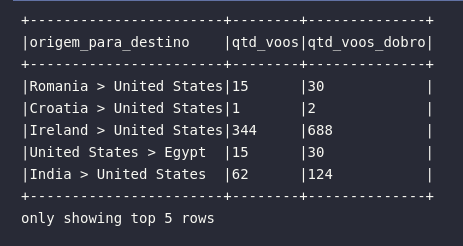
Neste momento, é possível notar a flexibilidade da função expr() como uma forma de construir expressões capazes de serem utilizadas para as mais variadas operações em consultas. Sua possibilidade de aplicar um parse em uma string como uma operação escrita dentro das premissas da linguagem SQL trazem um grande dinanismo sob o ponto de vista do usuário. No exemplo acima, a alteração do nome de uma coluna foi proporcionada pelo simples uso do bloco AS. Adicionalmente, também é possível aplicar funções dentro de expressões que compilam para uma operação lógica compreensível pelo Spark:
# Criando consulta com múltiplos expr()
df.select(
expr("concat(ORIGIN_COUNTRY_NAME, ' > ', DEST_COUNTRY_NAME) AS origem_para_destino"),
expr("count AS qtd_voos"),
expr("count * 2 AS qtd_voos_dobro")
).show(5, truncate=False)
Dessa forma, consultas unindo o método select() com mútiplas expressões expr() acaba sendo um padrão comumente encontrado em fluxos de transformação. Visando proporcionar uma maior facilidade aos usuários, o Spark introduziu o método selectExpr() como uma forma de alocar consultas com múltiplas expressões sem a necessidade de referenciar explicitamente a função expr().
O método selectExpr()
De maneira direta, para exemplificar o poder do uso do método selectExpr(), o último bloco de código acima referenciado será reescrito através de sua aplicação:
# Reconstruindo consulta anterior com selectExpr()
df.selectExpr(
"concat(ORIGIN_COUNTRY_NAME, ' > ', DEST_COUNTRY_NAME) AS origem_para_destino",
"count AS qtd_voos",
"count * 2 AS qtd_voos_dobro"
).show(5, truncate=False)
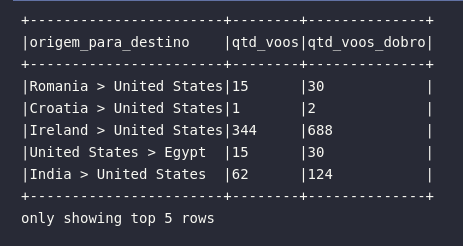
O resultado é idêntico e habilita uma funcionalidade altamente interessante dentro da dinâmica prática de uso do Spark na criação de consultas em DataFrames: com selectExpr(), as expressões inseridas dentro do método podem ser escritas como simples elementos do tipo string que, por sua vez, são resolvidos e avaliados para retornar o resultado esperado. Tais expressões podem unir referências de colunas, cálculos matemáticos, operadores lógicos ou até mesmo funções SQL:
# Mais um exemplo de consulta
df.selectExpr(
"*",
"upper(DEST_COUNTRY_NAME) AS upper_dest",
"power(count, 2) AS power2_count"
).show(5)
Obviamente, caso o Spark não consiga resolver o conteúdo das expressões, um erro será retornado ao usuário. No exemplo abaixo, uma consulta será escrita propositalmente chamando uma coluna inexistente na base:
# Consultando coluna inexistente
df.selectExpr(
"ERROR_DEST_COUNTRY_NAME"
).show(5)
Ao executar o código acima, uma exceção do tipo AnalysisException será retornada com a seguinte descrição:
AnalysisException: Column 'ERROR_DEST_COUNTRY_NAME' does not exist. Did you mean one of the following? [DEST_COUNTRY_NAME, ORIGIN_COUNTRY_NAME, count]; line 1 pos 0;
'Project ['ERROR_DEST_COUNTRY_NAME]
+- Relation [DEST_COUNTRY_NAME#32,ORIGIN_COUNTRY_NAME#33,count#34] csv
E assim, uma série de portas se abrem para as mais variadas consultas em DataFrames do Spark. Seja qual for o método ou a função utilizada, o poder de criação das transformações em atributos existe e pode ser amplamente explorado pelos usuários.
Conclusão e encerramento
Em suma, os ensinamentos consolidados neste artigo contemplaram propostas essencialmente relevantes dentro da dinâmica operacional de exploração de dados e criação de consultas no Spark. Compreender os elementos que foram um DataFrame e como os atributos podem ser referenciados a partir de diferentes formatos proporcionam, aos leitores, um grande poder adicional dentro da jornada de aprendizado.
Em linhas gerais, os pontos de destaque abaixo resumem um pouco da jornada construída até aqui:
- Os DataFrames são compostos por registros do tipo
Rowe atributos do tipoColumn - As referências aos atributos podem ser feitas pelas funções
col(),column()ouexpr() - Todas as três formas de referenciar colunas retornam o mesmo resultado
- Essencialmente, colunas referenciadas são como expressões posteriormente computadas pelo Spark como DAGs
- A função
expr()permite criar expressões como strings em uma linguagem próxima ao SQL - Os métodos
select()eselectExpr()podem ser utilizados para realizar consultas em DataFrames a partir de expressões previamente construídas
Foi ótimo ter você aqui, caro leitor. A partir deste ponto, uma série de novas possibilidades se abrem para as mais variadas aplicações de métodos em consultas à DataFrames. Fique ligado!




